






模型:InternVL2-2B
微调方法:LoRA
参数:矩阵秩 r
测评案例:羊肉抓饭(新疆),肠粉(粤菜),口水鸡(川菜),叉烧肉(粤菜)
r = 8:


可以看出,模型虽然认得菜品,但是这个回答并不准确,比如说口水鸡是四川火锅。
r = 128:
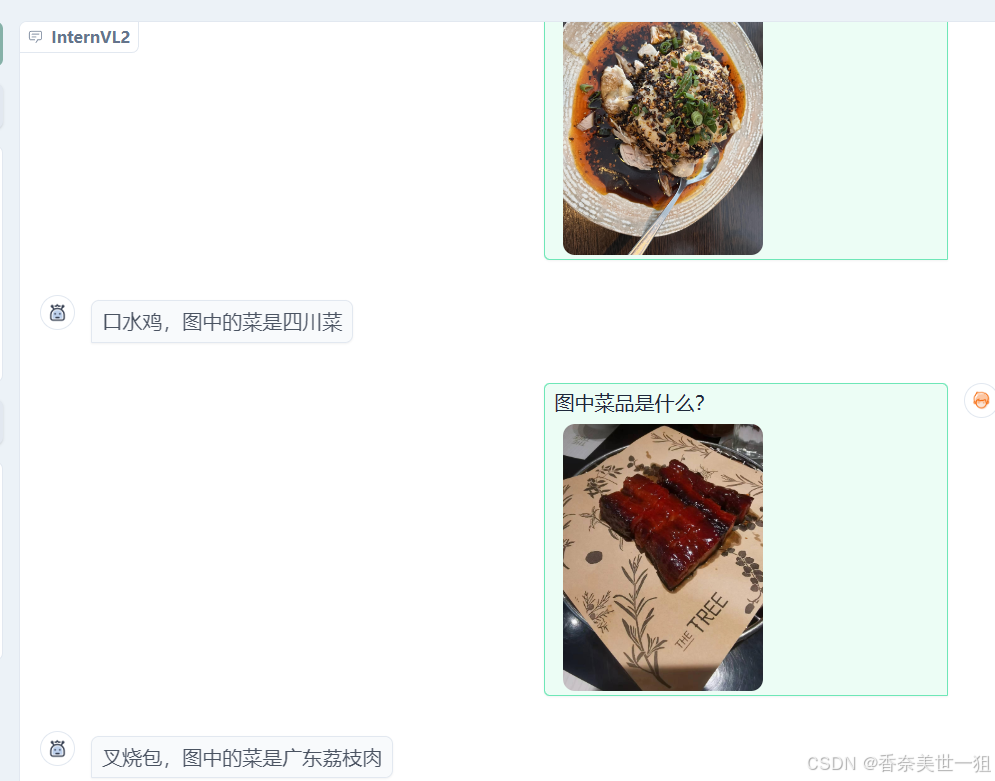
鸡蛋肠粉和羊肉抓饭也认出来了,比r=8好的是口水鸡说的很对,不过最后的叉烧肉还是说错了,我查了一下广东荔枝肉,和图中的叉烧肉还是有不小差别的。
再测试一次,r=128的模型又说对了。而r=8的模型仍然坚持四川火锅。
可见就是 r 越高确实能提高生成的准确性,尤其当用户没有明确问来自哪个菜系时,模型对于生成内容的概率分布会随着r升高而变得更准确(比如r=8的模型会坚持把口水鸡和四川火锅关联在一起,多次生成同一结果说明错误的概率分布占比较大)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









