






1 文件IO
1 linux系统编程是介于应用层和驱动层之间的一层。
2 在main函数中的argc表示命令行中参数的个数(文件名也算一个参数),char *argv[](字 符串指针数组,每一个元素都对应字符串的首地址,在输出字符串时,可以直接用指针 来输出)表示命令行的参数,argv[1]表示第一个参数。
3 file name 文件命令可以查看文件信息。
4 动态编译的可执行文件,需要附带一个动态链接库,在执行时,需要调用动态链接库中的 命令;优点是缩小了可执行文件的体积,并且加快了编译速度。缺点是哪怕一个简单的 程序,只用到链接库中的一两条命令也要附带庞大的链接库,如果其他计算机没有安装 对应的运行库,那么可执行文件则不能运行。
5 静态编译:编译器在编译可执行文件时候,把需要用到的对应动态链接库(.so和.Lib)中的 部分提取出来,链接到可执行文件中去,这样在执行文件时候不依赖动态链接库。
6 标准IO是间接调用系统函数,也就是C库函数;文件IO就是直接 调用内核提供的系统 调用函数。
7 标准IO的头文件是stdio.h,标准IO头文件是unistd.h;在任何操作系统中 使用标准IO都是兼容的;标准IO是围绕着流来操作,文件是围绕文件操作。
8 当我们打开一个文件时,系统会给我们分配一个文件描述符。
9 在posix.1应用程序中,文件描述符0,1,2分别对应标准输入,输出,出错。
10 open()函数用来打开文件,参数1是文件路径,参数2是文件标识(O_CREAT, O_RDWR,等),当参数2用到O_CREAT时参数3是权限。
11 文件权限可执行1,可写2,可读4;umask可以查看权限掩码。
12 close()函数用来关闭文件,参数是文件描述符,打开之后需要关闭的原因是 文件描述符是有限的。
13 read()函数的参数分别是文件描述符,缓冲区地址,读取的字节大小;成功 的话返回值是实际读取的字节数,读到末尾返回0,失败返回- 1;
14 write()参数和read()类似,如果成功返回值,就是实际写入的个数,失败 就是-1;
15 lseek()函数,参数分别是文件描述符,偏移量(向前或者向后移动),当前位置的基点 (SEEK_SET相对于文件开头,SEEK_CUR相对于当前文件读写指针的位置,SEEK_END相 对于文件末尾);返回值是当前的位置,也可以用来确定文件的长度。
2 目录IO
1 mkdir()函数用来创建文件夹,参数分别是路径,权限;创建成功返回值是0,创建失败 返回-1。
2 opendir()函数参数是路径,返回值失败返回NULL,成功是目录流指针(DIR类型),它告诉 我们从什么地方去读目录。
3 closedir()函数参数是目录流指针,成功返回0,失败返回-1;
4 readdir()函数,参数就是打开目录的结构体流指针(struct dirent *),成功返回一个结构体指 针(结构体成员第一个成员是d_ino(ll -i就可以看到),第二个成员是文件的名字d_name), 失败返回NULL。
5 在内核中文件的内容是通过链表来存放的,读取文件夹需要遍历(重复读文件夹即可)。
3 库
1 库是一种可执行的二进制文件,是编译好的代码;可以直接使用,提高开发效率。
2 linux下库分为静态库和动态库:静态库在程序编译的时候会被链接到目标代码里面,所以 我们的程序就不需要该静态库了,因此体积比较大,以lib开头,以.a结尾。
3 动态库不会被链接到目标代码中,而是在程序运行的时候被载入的,程序运行时候需要动 态库,以lib开头,以.so结尾。
4 静态库的制作:
1 编写库的源代码。
2 将源码生成.o文件:gcc -c
3 使用ar命令来创建静态库:ar cr libmylib.a mylib.o;c是创建r是覆盖。libmylib.a 是库文件名,mylib是库名。
4 测试库文件,gcc test.c -lmylib -L . -l后面加库名,-L后面跟库的地址。
5 动态库的制作(动态库制作好之后系统会默认到/lib或者/usr/lib下去找):
1 编写源代码。
2 生成.o文件:gcc -c -fpic mylib.c -fpic产生位置无关代码,让他可以被多个目标代码 加载。
3 gcc命令创建动态库:gcc -shared -o libmylib.so mylib.o -shared生成动态库
4 测试库文件gcc test.c -lmylib -L .
4 进程
1 进程是指正在运行的程序,是资源分配的最小单位。
2 每个进程都有一个唯一的表示符,这个就是进程ID。
3 进程之间的通信方式:
1 管道通信:有名管道,无名管道
2 信号通信:信号发送,接收,处理
3 IPC通信:共享内存,消息队列,信号灯。
4 socket通信
4 进程的三种状态,以及转换。
5 pid_t fork(void)用来创建进程,如果创建失败,返回值为负数;在父进程中, 返回值为新创建子进程的PID;在子进程中,返回0;
6 getpid()获得当前进程的PID;
7 getppid()获得当前进程的父进程的PID,如果返回的是1说明父进程已退出。
8 子进程代码内容和父进程是一样的,但是子进程是从fork()函数开始执行的; 父子进程的执行顺序是不一定的,看谁能先抢到CPU资源。
9 exec函数族主要有两种情况:
1 当进程认为自己不能为系统和用户做出任何贡献时候,就可以调用exec 让自己重生。
2 如果一个程序想要执行另外一个程序,那么它可以调用fork()函数,新建 一个进程,然后调用任何一个exec函数使子进程重生。
10 execl的参数分别是要执行的可执行文件的路径,要执行程序的程序名,如 果程序有参数那么第三个参数就时程序参数,最后以NULL结尾,失败返回 -1,成功无返回值;此函数使换核不换壳。它还可以把程序换成命令。
11 exit()可以让进程退出参数为退出值。
12 ps命令可以列出系统中当前运行的哪些进程:
1 参数a显示所有进程,tty表示该进程要关联终端(可以交互),COMMD是 进程执行的程序。
2 参数u可以显示进程归属用户和内存使用情况,VSZ表示进程使用虚拟内 存的大小,RSS表示进程使用物理内存的大小,%MEM占用内存的%比。
3 参数x是表示与终端无关的进程信息。
4 |grep可以用来查找我们想要的东西。
13 kill -9 命令是用来杀死进程的。
14 孤儿进程表示父进程已近死了,但是子进程还活着,子进程会被pid号为1 的init进程所领养。
15 僵尸进程(z+表示进程是僵尸状态)表示子进程结束以后,父进程还在运行, 但是父进程不去释放进程控制块,子进程的部分资源需要父进程释放,这个 子进程就是僵尸进程。
16 pid_t wait(int *status)函数成功返回pid号,失败的话返回-1;与wait 函数参数有关的两个宏定义:如果正常退出WIFEXITED(status)为真, WEXITSTATUS(status)如果正常退出,该宏定义值为子进程的退出值;wait 是一个阻塞函数,它会一直阻塞直到子进程退出。
17 守护进程的一个特点就是运行在后台,不跟任何控制终端相关联。
18 守护进程的要求创建:
1 必须作为我们init进程的子进程,让他变成孤儿进程(必须)。
2 setsid守护进程不予任何控制终端相交互(必须)。
3 调用chdir(“/”)函数,将当前的工作目录改成根目录。
4 从设umask(0)文件掩码。
5 关闭文件描述符(标准输入输出出错),节省资源close(0),1,2。
6 执行代码(必须),while(1);
19 调用setsid()函数会创建一个新的会话抛弃控制终端;一个进程组有多个进 程,一个会话有多个进程组。
5 进程之间的通信
1 进程在应用层不能进行交流,必须通过内核通信。
2 无名管道通信只能实现有亲缘关系的通信。
3 pipe(int pipefd[2])函数参数是得到的文件描述符,fd[0]是读,fd[1]是写; 返回值成功为0,失败为1;在fork函数之前创建管道。
4 管道里面没有数据,读的话会阻塞。
5 有名管道可以实现没有亲缘关系进程之间的通信。
6 mkfifo()创建管道类型特殊的文件名,参数分别是创建的文件名,权限;返回 值成功0,失败-1;
7 access(argv[1], F_OK),用来判断是否存在文件,不存在返回-1;
8 memset()用来设置内存区的值,参数分别是地址,内容,大小。
9 信号通信也是在内核中进行通信。
10 kill()函数的参数分别是pid号,信号类型。
11 raise()函数使自己给自己发信号等价于kill(gitpid(), sig),参数是数字;
12 alarm()类似一个定时器,当时间到了,就会产生一个信号,如果不去处理就 会中止该进程。
13 pause()函数会让进程暂停(进入睡眠状态),直到被信号中断,只返回-1;
14 信号的处理分为系统默认(一般就是中止进程),忽略,捕获。
15 signal()函数,参数分别是要处理的信号(SIGINT等),处理的方式(忽略, 默认,捕获 SIG_IGN,SIG_DFL,myfunc(),函数的参数就是参数1)。
16 shmget(),参数1是IPC_PRIVATE或者ftok函数进行填充(权限要加// IPC_CREAT),第二是共享内存大小,第三个是权限。成功返回共享内存的标 识符(key_t类型),失败-1;
17 ftok()函数生成ket_t值,第一个参数是文件路径和文件名,第二个参数是 字符。
18 ipcs -m查看共享内存,ipcrm -m id可以用来删除共享内存。-q是队列。
19 shmat()函数用来映射共享内存内核到应用地址,参数分别是共享内存的返回 值(shmget()的返回值),映射到的地址(NULL系统自动映射),权限(0表示 可读可写);成功返回映射的地址(返回值key_t类型)。
21 shmdt()将进程中映射后的地址删除,参数是映射后的地址。
21 共享内存是进程之间通信效率最高的方式,因为不用进入内核进行操作。
22 shmactl()参数分别是操作内核中共享内存的标识符,命令(IPC_STAT(获取对 象的属性),IPC_RMID(删除对象)),指定属性时用来保存或设置属性。
23 strncpy()向地址中写数据,参数分别是地址,字符串,大小;
24 管道通信方式的中间介质是文件,有名管道与消息队列类似,但是少了打开 和关闭文件方面的复杂性。优点:可以通过发送消息来避免管道同步和阻塞 的问题,可以通过某些方法查看紧急消息;
25 int msgget()用来创建消息队列,参数分别是key_t,访问权限;成功返回 消息队列ID,失败返回-1;
26 int msgctl()操作队列,参数分别是id,命令(读IPC_STAT,IPC_SET设置消 息队列的属性,IPC_RMID删除),struct msqid * ;成功返回的0,失败-1;
27 int msgsnd()参数分别是id,const void *指向消息队列的指针,数据大小 (消息内容),int msgflag为0阻塞发送为IPC_NOWAIT消息没发完,函数也 会返回,非阻塞发送;成功0,失败-1。
28 struct msgbuf{long mtype消息类型,char mtext[128]消息内容};
29 msgrcv()参数分别是id,接受缓冲区指针,字节数,接受消息的标识0代表 接受的第一个消息,最后一个是否阻塞;成功返回接受的字节,失败返回-1;
30 信号量不以传输数据位主要目的,主要用来保护共享资源。
31 int semget(key_t, int, int)参数分别是信号量的键值,信号量的数量,标 识;成功返回信号量ID,失败返回-1;
32 int semctl(int,int, int,union semun),参数分别是id,信号量编号, 命令(IPC_STAT获取信号量的属性,IPC_SET设置信号量的属性,IPC_RMID 删除,SETVAL设置信号量的值),联合体union semun{int val设置值用到; struct semid_ds *buf获取和设置用到, unsigned short *array; struct seminfo *__buf};
33 int semop(int, struct sembuf *, size_t)函数可以进行减1加1操作,参 数分别是id,信号量结构体指针struct sembuf{unsigned short sem_num 要操作信号量编号; short sem_op//1为V操作释放资源,-1为P分配资源, 0为等待,直到信号量变为0; short sem_flg//0为阻塞,IPC_NOWAIT非阻 塞}, 要操作信号量的数量。
34 在定义变量时候,每个变量都有其独有的存储空间,但是联合体union可以 在同一片内存下储存不同类型的数据,它的优势是成员不会被同时使用时, 可以节省空间,空间大小最少也是最大成员的大小。
6 线程
1 线程是程序执行的最小单位,系统独立调度和分配CPU的基本单位。
2 线程在linux中是一个轻量级的进程。
3 线程与进程的区别:
1 进程有自己独立的地址空间;线程有属于自己的栈和寄存器,很多空间是共用的。
2 线程是程序执行的最小单位,进程是资源分配的最小单位。
3 线程的上下文切换比进程快的多。
4 启动速度快,退出也快,对系统资源冲击小
4 如果有1个cpu,8个核,那它就可以同时处理8个线程。
5 在处理多程序任务时,并不是线程越多越好:
1 文件IO操作:文件IO对CPU使用率不高,因此可以分时复用CPU时间片 效率最高时线程个数 = 2 * CPU核数。
2 处理复杂算法线程个数 = CPU核数。
6 pthread_t pthread_self(void)返回当前线程的id。
7 int pthread_create(pthread_t *thread传出id参数, const
pthread_attr_t *attr线程属性一般默认写NULL, void
*(*start_routine) (void *)函数指针在线程中执行的任务, void *arg函 数的参数)。
8 sleep()函数会让程序挂起,放弃cpu资源,不会影响cpu效率。
9 默认情况下主线程执行完了后就会释放对相应的地址空间,子线程就不存在了。
10 在编译线程时需要制定线程库ggc a.c -lpthread。
11 void pthread_exit(void *retval参数是退出传出的返回值)函数用来退出 线程,并且不会影响其他线程,在子线程和主线程中都可以使用。
12 int pthread_join(pthread_t thread, void **retval二级指针,指向一级 指针的地址,是一个传出参数)主线程用来回收子线程资源的,它会一直阻 塞等待子线程退出。
13 int pthread_detach(pthread_t)线程分离函数。在某些情况下,程序中的主 线程有自己的业务,如果让主线程负责回收子线程的资源,调用 pthread_join()会被阻塞,那么在主线程中调用线程分离函数(还要调用 pthread_exit()),子线程的资源被系统其他进程接管并回收。
14 int pthread_cancel(pthread_t)在线程A中杀死线程B,但是B不会马上死, 当B调用了系统函数之后才会被杀死。
15 int pthread_equal(pthread_t, pthread_t)线程id的比较,linux线程id 是无符号长整形,本来可以直接比较,但是线程库是可以跨平台使用,在某 些平台可能不是一个单纯的整形。相等返回非0,不相等返回0;
7 线程同步
1 线程同步是指当一个线程在对内存的共享资源进行操作的时候,其他线程不允许对这块内 存进行操作,直到这个线程访问完为止;所谓线程同步不是指多个线程同时对内存进行 访问,而是按照先后顺序依次执行。
2 读数据从物理内存出来,通过三级缓存(寄存器的处理速度比物理内存快的多得多,缓存 来提高处理效率)到寄存器。
3 int pthread_mutex_init(pthread_mutex_t *restrict mutex变量地址, const pthread_mutexattr_t *restrict arr互斥锁的属性一般NULL)初始化互斥 锁,*restrict关键字来修饰指针,访问锁的地址只能用mutex。
4 int pthread_mutex_destroy(pthread_mutex *mutex)函数销毁互斥锁。
5 int pthread_mutex_lock(pthread_mutex_t *mutex)给互斥锁上锁,其他线程 上锁就会失败,会阻塞在上锁这里。
6 int pthread_mutex_unlock(pthread_mutex_t *mutex);解锁,谁上的谁解开, 解开之后阻塞的线程竞争这把锁,没抢到的继续阻塞。
7 int pthread_mutex_trylock(pthread_mutex_t *mutex)尝试加锁,锁打开的 加锁成功,已近被锁了返回错误号,不会阻塞。
8 有多少个共享资源就有多少把锁;当有两把锁时候,两个线程都需要用两把锁, 但是各自占用了一把锁,那么这样就会造成死锁。
9 pthread_rwlock_init()初始化读写锁pthread_rwlock_destroy()销毁读写锁
读写锁变量是pthread_rwlock_t类型。
10 pthread_rwlock_rdlock()如果读写锁是打开的,那么加锁成功;如果读写锁 已近锁定了读操作,调用他依然可以加锁成功,因为读锁是共享的,如果已 近锁定写操作,那么会被阻塞。
11 pthread_rwlock_tryrdlock()和rdlock函数区别就是他不会阻塞。
12 pthread_rwlock_wrlock()读写锁是打开的,加锁成功,如果已近锁定读或写, 那么会被阻塞。
13 phread_rwlock_trywrlock()和wrlock一样线程不会阻塞,只会返回错误码。
14 pthread_rwlock_unlock()读写锁都可以解开。
15 读写锁在多多线程读,少线程写有优势,因为读是可以共享的。
16 单独把i++和++i拿出来说都是一样的i=i+1;如果当做运算符或者在while() 中a=i++指先赋值i再加1,a=++i是指先加1,再赋值;在for效果一样, 都是先执行i=0,再++;
17 rand()产生随机数。
18 条件变量用来配合互斥锁来解决生产者消费者模型:消费和生产的速度不一 样,任务队列满了停止生产,全力消费;任务队列空了停止消费全力生产。
19 pthread_cond_t cond条件变量。
20 pthread_cond_init()函数,pthread_cond_destroy()参数模式和互斥锁一样
21 pthread_cond_wait()让线程阻塞(会自动打开上锁的互斥锁,解除阻塞后又 会自动给互斥锁上锁),参数分别是条件变量地址,互斥锁地址。
22 pthread_cond_timewait()将线程阻塞一定时间之后解除阻塞,参数分别是& 环境变量,&互斥锁,第三个是timespec结构体地址。
23 struct timespec {time_t tv_sec秒, long tv_nsec纳秒,一般初始化0}从 某个时间点开始;
24 time_t time()到当前时间的总秒数字,参数填NULL。
25 pthread_cond_signal()解除至少一个阻塞线程。pthread_cond_broadcast() 唤条件变量中所有阻塞线程。
26 使用头插法建立链表(注意要使用链表指针必须先申请空间):
1 typedef struct LNode{int data; struct LNode *next}LNode, *LinkList; 链表的数据结构,data是要存放的数据,另外一个是指向下一个节点的指针;
2 通过LinkList类型定义链表头指针变量L(通常不存储数据),s用元素节 点存数数据。
3 定义头结点之后,内存尚未分配空间,通过malloc关键字分配空间,并 让L指针指向这片空间,空间大小是结构体大小,next指向NULL。
4 初始化s节点,填写数据,s->next = NULL;
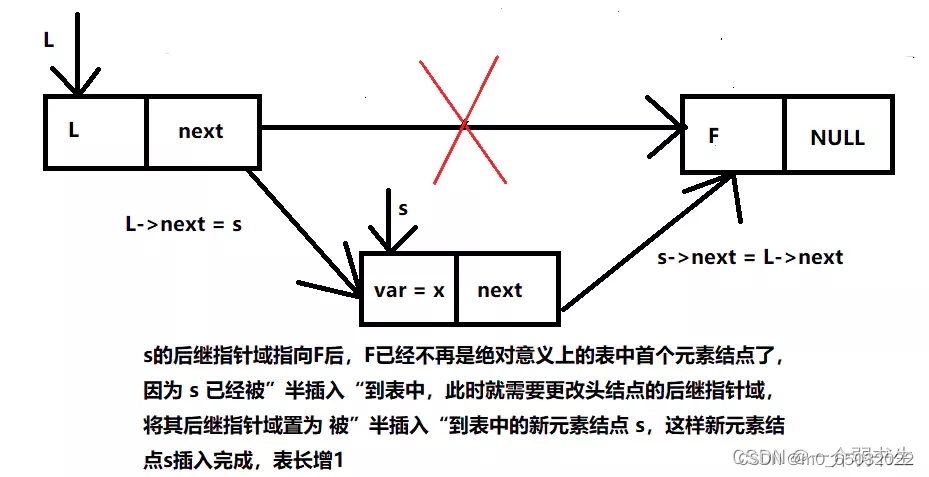
5 新的节点s始终在L->next之前插入,输入的顺序与最终链表顺序相反。
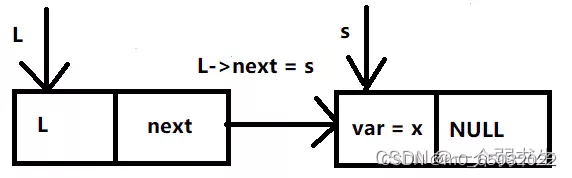
6 头结点指向s,L->next = s; 返回头结点。
7 遍历节点while(L->next != NULL){L = L->next;}
8 malloc()函数用于申请一块连续的指定大小的内存;free()函数用于释放 malloc()申请的内存,参数是malloc返回的地址。
27 信号量也可以用来处理生产者消费者模型,定义信号量类型变量sem_t。
28 sem_init(sem_t *, int如果是0那就作线程同步,1进程同步, usigned int 指定资源数);sem_destroy(sem_t *)销毁信号量。
29 int sem_wait(sem_t *)函数判断信号量的资源数量,资源数量是0那么这个 资源就阻塞了,如果是大于0,调用函数就会减1;
30 int sem_trywait()和_wait函数一样,但是不会阻塞。
31 int sem_post(sem_t *)调用一次信号量就会加一。
32 int sem_getvalue(sem_t *, int *传出参数),查看信号量拥有的资源个数。
33 当信号量为1的时候不用加锁,当信号量不为1需要加锁。















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









