







如下是我工作中一个项目的一次经历(我将代码回退特意抓取的),出现这个问题的场景是一次压力测试导致整个系统卡顿,瞬间杀掉应用就OK了,究其原因最终查到是一个API的调运位置写错了方式,导致一直被狂调,当普通使用时不会有问题,压力测试必现卡顿。具体内存参考图如下:
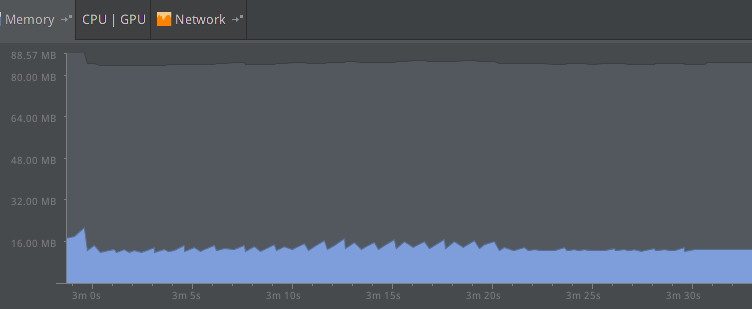
与此抖动图对应的LogCat抓取如下:
//截取其中比较密集一段LogCat,与上图Memory检测到的抖动图对应,其中xxx为应用包名
…
10-06 00:59:45.619 xxx I/art: Explicit concurrent mark sweep GC freed 72515(3MB) AllocSpace objects, 65(2028KB) LOS objects, 80% free, 17MB/89MB, paused 3.505ms total 60.958ms
10-06 00:59:45.749 xxx I/art: Explicit concurrent mark sweep GC freed 5396(193KB) AllocSpace objects, 0(0B) LOS objects, 75% free, 23MB/95MB, paused 2.079ms total 100.522ms
…
10-06 00:59:48.059 xxx I/art: Explicit concurrent mark sweep GC freed 4693(172KB) AllocSpace objects, 0(0B) LOS objects, 75% free, 23MB/95MB, paused 2.227ms total 101.692ms
…
我们知道,类似上面logcat打印一样,触发垃圾回收的主要原因有以下几种:
-
GC_MALLOC——内存分配失败时触发;
-
GC_CONCURRENT——当分配的对象大小超过一个限定值(不同系统)时触发;
-
GC_EXPLICIT——对垃圾收集的显式调用(System.gc()) ;
-
GC_EXTERNAL_ALLOC——外部内存分配失败时触发;
可以看见,这种不停的大面积打印GC导致所有线程暂停的操作必定会导致UI视觉的卡顿,所以我们要避免此类问题的出现,具体的常见优化方式如下:
-
检查代码,尽量避免有些频繁触发的逻辑方法中存在大量对象分配;
-
尽量避免在多次for循环中频繁分配对象;
-
避免在自定义View的onDraw()方法中执行复杂的操作及创建对象(譬如Paint的实例化操作不要写在onDraw()方法中等);
-
对于并发下载等类似逻辑的实现尽量避免多次创建线程对象,而是交给线程池处理。
当然了,有了上面说明GC导致的性能后我们就该定位分析问题了,可以通过运行DDMS->Allocation Tracker标签打开一个新窗口,然后点击Start Tracing按钮,接着运行你想分析的代码,运行完毕后点击Get Allocations按钮就能够看见一个已分配对象的列表,如下:
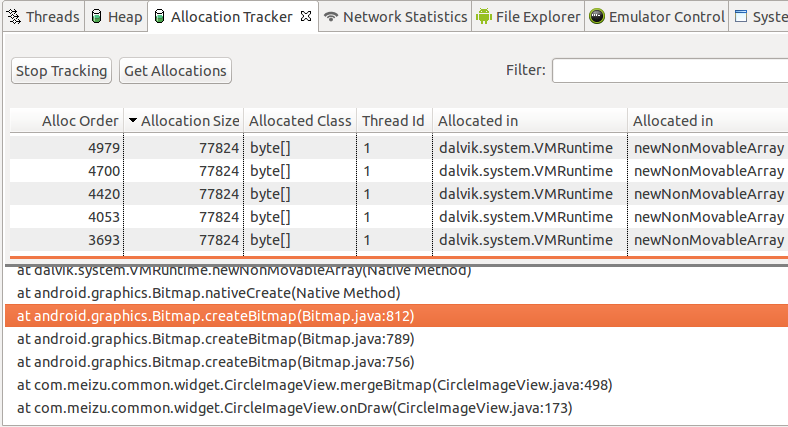
点击上面第一个表格中的任何一项就能够在第二个表格中看见导致该内存分配的栈信息,通过这个工具我们可以很方便的知道代码分配了哪类对象、在哪个线程、哪个类、哪个文件的哪一行。譬如我们可以通过Allocation Tracker分别做一次Paint对象实例化在onDraw与构造方法的一个自定义View的内存跟踪,然后你就明白这个工具的强大了。
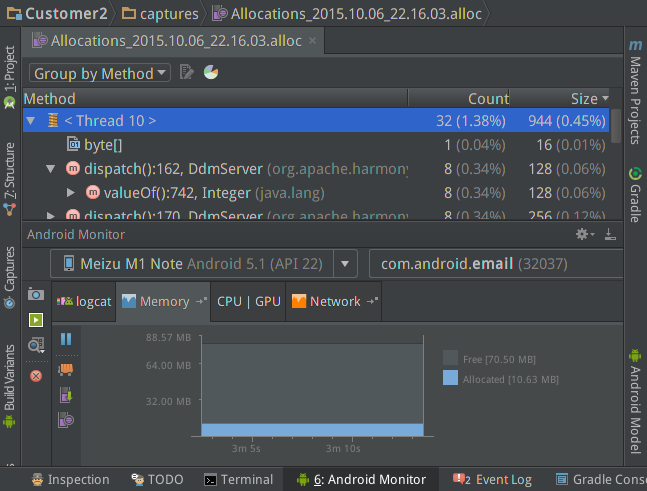
PS一句,Android Studio新版本除过DDMS以外在Memory视图的左侧已经集成了Allocation Tracker功能,只是用起来还是没有DDMS的方便实用,如下图:
2-3-6 使用Traceview和dmtracedump进行分析优化
关于UI卡顿问题我们还可以通过运行Traceview工具进行分析,他是一个分析器,记录了应用程序中每个函数的执行时间;我们可以打开DDMS然后选择一个进程,接着点击上面的“Start Method Profiling”按钮(红色小点变为黑色即开始运行),然后操作我们的卡顿UI(小范围测试,所以操作最好不要超过5s),完事再点一下刚才按的那个按钮,稍等片刻即可出现下图,如下:
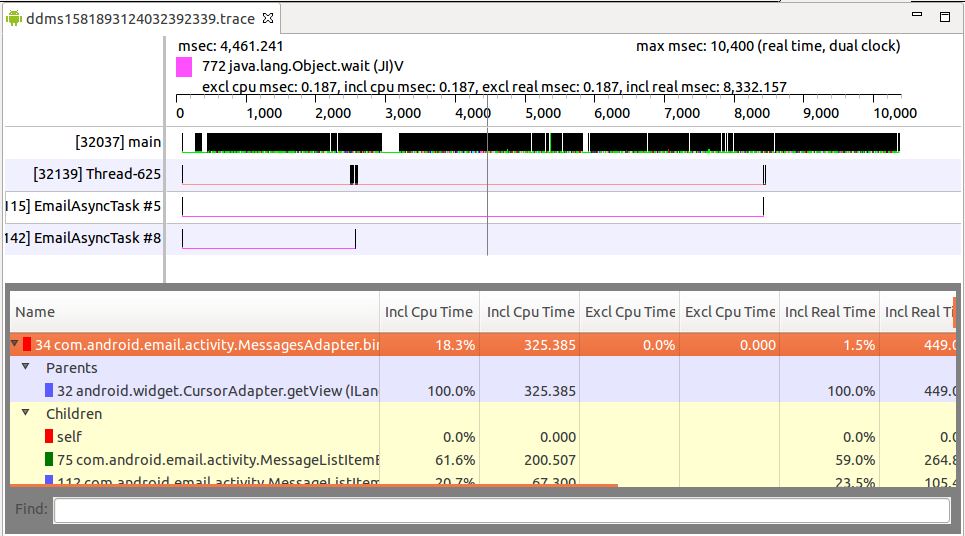
花花绿绿的一幅图我们怎么分析呢?下面我们解释下如何通过该工具定位问题:
整个界面包括上下两部分,上面是你测试的进程中每个线程运行的时间线,下面是每个方法(包含parent及child)执行的各个指标的值。通过上图的时间面板可以直观发现,整个trace时间段main线程做的事情特别多,其他的做的相对较少。当我们选择上面的一个线程后可以发现下面的性能面板很复杂,其实这才是TraceView的核心图表,它主要展示了线程中各个方法的调用信息(CPU使用时间、调用次数等),这些信息就是我们分析UI性能卡顿的核心关注点,所以我们先看几个重要的属性说明,如下:
| 属性名 | 含义 |
| — | — |
| name | 线程中调运的方法名; |
| Incl CPU Time | 当前方法(包含内部调运的子方法)执行占用的CPU时间; |
| Excl CPU Time | 当前方法(不包含内部调运的子方法)执行占用的CPU时间; |
| Incl Real Time | 当前方法(包含内部调运的子方法)执行的真实时间,ms单位; |
| Excl Real Time | 当前方法(不包含内部调运的子方法)执行的真实时间,ms单位; |
| Calls+Recur Calls/Total | 当前方法被调运的次数及递归调运占总调运次数百分比; |
| CPU Time/Call | 当前方法调运CPU时间与调运次数比,即当前方法平均执行CPU耗时时间; |
| Real Time/Call | 当前方法调运真实时间与调运次数比,即当前方法平均执行真实耗时时间;(重点关注) |
有了对上面Traceview图表的一个认识之后我们就来看看具体导致UI性能后该如何切入分析,一般Traceview可以定位两类性能问题:
-
方法调运一次需要耗费很长时间导致卡顿;
-
方法调运一次耗时不长,但被频繁调运导致累计时长卡顿。
譬如我们来举个实例,有时候我们写完App在使用时不觉得有啥大的影响,但是当我们启动完App后静止在那却十分费电或者导致设备发热,这种情况我们就可以打开Traceview然后按照Cpu Time/Call或者Real Time/Call进行降序排列,然后打开可疑的方法及其child进行分析查看,然后再回到代码定位检查逻辑优化即可;当然了,我们也可以通过该工具来trace我们自定义View的一些方法来权衡性能问题,这里不再一一列举喽。
可以看见,Traceview能够帮助我们分析程序性能,已经很方便了,然而Traceview家族还有一个更加直观强大的小工具,那就是可以通过dmtracedump生成方法调用图。具体做法如下:
dmtracedump -g result.png target.trace //结果png文件 目标trace文件
通过这个生成的方法调运图我们可以更加直观的发现一些方法的调运异常现象。不过本人优化到现在还没怎么用到它,每次用到Traceview分析就已经搞定问题了,所以说dmtracedump自己酌情使用吧。
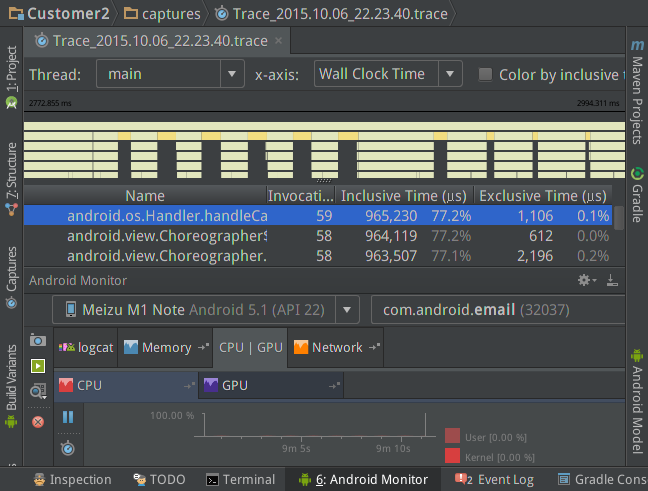
PS一句,Android Studio新版本除过DDMS以外在CPU视图的左侧已经集成了Traceview(start Method Tracing)功能,只是用起来还是没有DDMS的方便实用(这里有一篇AS MT个人觉得不错的分析文章(引用自网络,链接属于原作者功劳)),如下图:
2-3-7 使用Systrace进行分析优化
Systrace其实有些类似Traceview,它是对整个系统进行分析(同一时间轴包含应用及SurfaceFlinger、WindowManagerService等模块、服务运行信息),不过这个工具需要你的设备内核支持trace(命令行检查/sys/kernel/debug/tracing)且设备是eng或userdebug版本才可以,所以使用前麻烦自己确认一下。
我们在分析UI性能时一般只关注图形性能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









