






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
(本文默认已经下载完anaconda且配置过pytorch的环境并下载完pytorch)
本文主要展示如何下载pycharm,并将介绍一些基础的pycharm使用技巧及如何导入数据集和项目所需的数据板块的一些操作。
一、如何下载并安装pycharm?
pycharm是一种集成开发环境,为了能够让你快速编写代码,便于调试.
下载pycharm:
- 官网下载:https://www.jetbrains.com/pycharm/download/#section=windows

- 专业版是收费的,社区版是免费的,社区版功能对新手足够使用,我们这里就下载社区版的。
- 请根据机器是64位还是32位来选择对应的PyCharm版本
安装pycharm:
- 下载完后,点击安装,修改安装路径,建议安装C盘以外位置
- 按图中勾选(建议不选择.py选项,这是关联文件,如果打钩了,以后电脑双击.java文件就会用它打开。),如图勾选后点next.
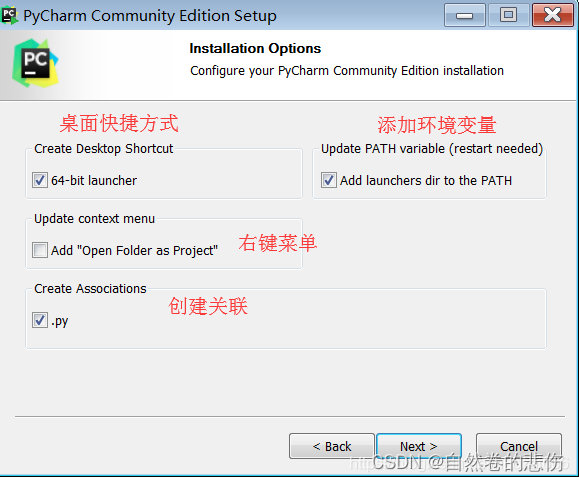
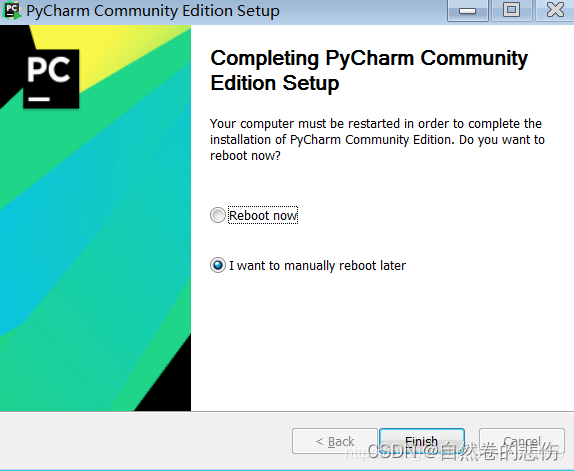
- 一路next,出现如图,自行选择是否现在重启(建议先把要保存的东西保存好,在手动重启)
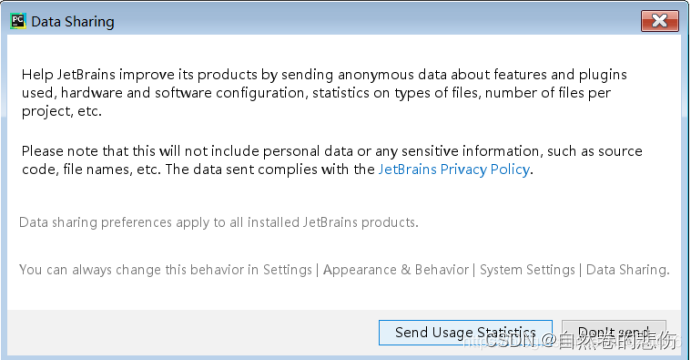
- 重启后打开pycharm应用,直接点击OK,我接受,然后出现如图,点击右边那个
二、简单使用pycharm
1.如何变成中文模式
出现下图说明安装成功,点击最上方选项

具体方案:
- 打开pycharm
- 点击file 找到setting点进去
- 搜索plugins
- plugins 下搜索框里输入 chinese
- 安装自己需要的中文包
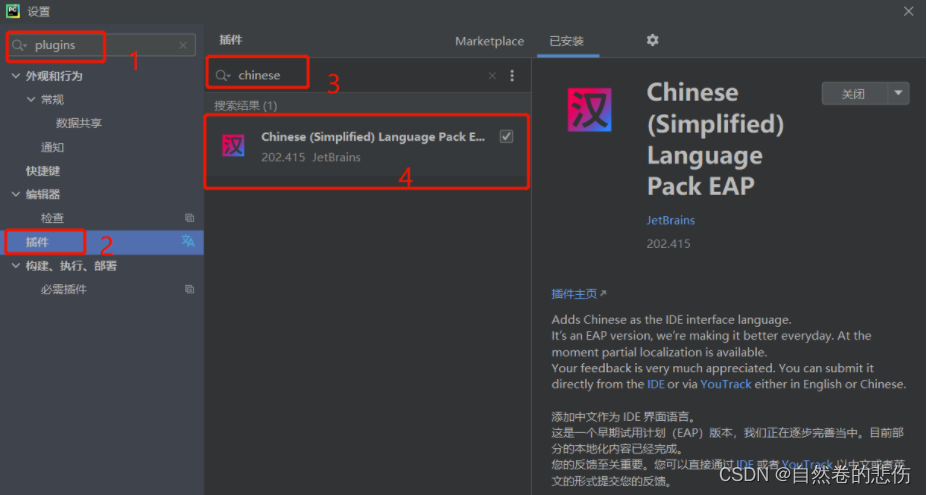
- 重启pycharm 就可以变成中文版本 再使用pycharm 就超级方便了
2.导入环境
1.首先打开pycharm 新建项目
2.点击左上角setting,如下图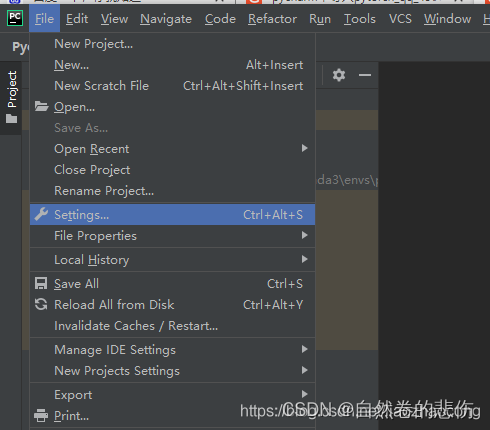
3.点击左栏的python interpreter
4.选择对应的解释器python interpreter ,点击ok完成
5.如果没有你要的解释器,则点击下面的选择show all
6.再选择+号
7.选择conda环境,然后选择已经存在的环境 existing environment
8.一路ok回去
9.再main.py文件中写入下面代码测试
import torch
print(torch.cuda.is_available())
x=torch.randn(3,5)
print(x)

true表示pytorch GPU版本可以使用了
三、RMB识别项目之数据部分的感悟
RMB识别项目可以跟着哔哩哔哩UP主 比飞鸟贵重的多_HKL 进行学习(亲测通俗易懂,而且非常基础),项目的具体代码在视频下方也有,以下是具体链接:人工智能打游戏系列课程1:基于深度学习的目标检测算法(正经深度学习教程!!!)_哔哩哔哩_bilibili
1.为什么要尝试实践这样一个简单的小项目?
我相信不少初学者在学习深度学习时会产生更为一样的想法,那就是知识点太多太繁杂了。而通过一个小项目的实践可以帮助我们迅速地了解一个项目的主干部分都有什么,正如一棵大树,只有拥有足够粗壮的躯体,才能支撑起更加繁茂的枝丫。在机器学习模型训练中大致有五大步骤;第一是数据,第二是模型,第三是损失函数,第四是优化器,第五个是迭代训练过程。本文主要讲述我在学习第一个板块,即数据部分的一些收获和感悟。
2.数据部分的收获
数据模块通常还会分为四个子模块,数据收集、数据划分、数据读取、数据预处理。在进行实验之前,需要收集数据,数据包括原始样本和标签。
有了原始数据之后,就需要进行第二个子模块数据划分,而数据集又可以分为三类:训练集、验证集和测试集
- 训练集用于训练模型,验证集用于验证模型是否过拟合,也可以理解为用验证集挑选模型的超参数,测试集用于测试模型的性能,测试模型的泛化能力;
- 通俗来说,每当一轮测试集中的数据全部使用后,将验证集中的数据代入模型,检验梯度。当所有轮次结束,再使用测试集中的数据。
- 最后,训练集、验证集和测试集中的数据必须不相同。
第三个子模块是数据读取,也就是这里要学习的DataLoader,pytorch中数据读取的核心是DataLoader。
而DataLoader则能细分为两个子模块,Sampler和DataSet;Sample的功能是生成索引,也就是样本的序号;Dataset是根据索引去读取图片以及对应的标签;
首先, DataLoader的功能是构建可迭代的数据装载器。而对于其用法,其中不仅需要我们根据特定情况设定的Dataset类(决定数据从哪里读取及如何读取),还需要我们设定以下参数,其具体功能如下:
- batchsize:批大小;
- num_works:是否多进程读取数据;
- shuffle:每个epoch是否乱序;
- drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据;
其中对于batchsize与Epoch的概念我们尤其要掌握:
所有训练样本都已输入到模型中,称为一个Epoch;而Batchsize则是代表了批大小,决定一个Epoch中有多少个Iteration。我们可通过一个Batchsize和Epoch实例进一步了解:
假设您有一个包含200个样本(数据行)的数据集,并且您选择的Batch大小为5和1,000个Epoch。这意味着数据集将分为40个Batch,每个Batch有5个样本。每批五个样品后,模型权重将更新。这也意味着一个epoch将涉及40个Batch或40个模型更新。有1000个Epoch,模型将暴露或传递整个数据集1,000次。在整个培训过程中,总共有40,000Batch。
其次, Dataset又具体承担什么责任呢?
简单来说,Dataset是用来定义数据从哪里读取(根据我们给定的存放数据集的路径),以及如何读取的问题。在具体实践中,我们往往会重新定义一个合适的Dataset类,而我们所定义的类则需要继承给定的Dataset抽象类,并且复写__init__(),__getitem__()函数。
- init:初始化我们所设定的Dataset类
- getitem:接收一个索引,返回一个样本

第四个子模块则是数据预处理:
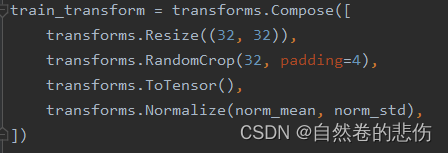
把数据读取进来往往还需要对数据进行一系列的图像预处理,比如说数据的中心化,标准化,旋转或者翻转等等。pytorch中数据预处理是通过transforms进行处理的。
数据预处理中 1. Resize的功能是缩放
2. RandomCrop的功能是裁剪
3. ToTensor的功能是把图片变为张量
总结
第一周正儿八经地去学了如何将一个简单的小项目落地,中间遇到了很多问题,比如环境的调试,运行的时候各种问题,这些都需要花费大量时间去搜索资料慢慢解决。也终于使我一个原先什么都不懂的小白成为了一个。。。普普通通的小白。总而言之,还是很有收获的,现在进度也在慢慢推进,等我学完模型等板块,也会继续发布我的收获的。















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









