







 利用PyTorch框架和ResNet18模型,实现人民币纸币的面值识别与分类,通过图像处理和深度学习技术,达到高精度的识别效果。
利用PyTorch框架和ResNet18模型,实现人民币纸币的面值识别与分类,通过图像处理和深度学习技术,达到高精度的识别效果。
字图像处理课程的编程作业,在此记录下来,方便自己和诸位查看。
编程环境:Colab或 jupyter Notebook
编程语言以及所用框架:python3.8 pytorch
实现思路:
本次编程作业我选择了实现人民币识别这一功能。
对于该问题,可以将其转化成为图像分类的问题,使用普通的卷积神经网络即可解决。因此我使用了18层的残差神经网络即ResNet18来作为本次作业图像分类的模型。为了方便起见,我使用了pytorch框架中所提供的已经进行了预训练的ResNet18模型。使用训练集对模型训练,同时进行交叉验证,训练完毕后,模型对任意的输入图片,即可预测出相应的面值。这便实现简单的人民币面值识别功能。
数据集说明:
关于本作业的数据集,我将收集到的不同弄面值的人民币都放在了文件夹RMBDataset下。所包含的面值有1元、5元、10元、20元、50元和100元,且全部为纸币。每个面值的纸币图片单独存放在名称为改面值数值的文件夹下,例如10元的人民币图片全部存放在文件夹10下。数据集一共有792张图片且拍摄方向各异,其中1元纸币的图片有134张,5元有99张,10元有157张,20元有101张,50元有168张,100元有133张。
数据集链接:https://github.com/bat67/RMB-Dataset
或:https://gitcode.net/mirrors/bat67/RMB-Dataset?utm_source=csdn_github_accelerator
源代码:https://pan.baidu.com/s/1mqvj-cVPApobeq-94om41A
提取码:ltkj
实现过程:
首先将收集的人民币纸币图片转化为pytorch可用的数据集,我使用了类RMBDataset来将文件夹RMBDataset中的图片构造成数据集。并且根据输入mode的不同将数据集分为训练集,验证集和测试集。其中训练集占整个数据集的60%,测试集和验证集各占剩余的20%。在生成数据集的过程中,还对图片进行预处理的操作,其中相较于测试集,训练集和验证集中的图片还多进行了随即旋转和中心裁剪的操作。而不对测试集中的图片进行上述操作主要是方便可视化查看图片。
在完成可视化对测试集图片进行查看后,加载pytorch中预训练处理后的模型resnet18,同时使用交叉熵函数CrossEntropyLoss作为损失函数,使用Adam函数作为优化函数,且初始学习率设置为0.001。
训练过程一共训练了100次,每训练一次,都会输出相应的平均损失Avg_loss,同时使用验证集进行一次交叉验证,得到相应的损失Val_loss和模型在验证集上的预测精度Vaild Accuracy,同时保存在验证集上预测精度最高时的模型参数以便于再训练集上预测出更好地结果。训练过程中,在验证集上得到的预测精度最高为100%,模型在测试集上的预测精度为96.8%。接下来对训练过程中所记录的模型在训练集上的平均损失Avg_loss和在验证集上的损失Val_loss得变化情况绘制折线进行可视化展示,同时还对训练过程中记录的模型在验证集上的预测精度的变化绘制图表进行了展示。
最后,随机取出32张图片使用模型对图片中纸币的面值进行识别,并同时可视化的展示图片中人民币的真实面值和模型识别的面值,如果识别正确,则用绿色表示,否则为红色。
代码展示:
由于本次作业是在jupyter Notebook上实现,故将代码分开给出。
导入相应的库并配置cuda环境。
import torch
import os, glob
import random, csv
import cv2 as cv
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import time
import torchvision
import matplotlib.pyplot as plt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
根据已有的图片构造数据集,
图片的标签只能是[0:c-1](此处代表前闭后闭的区间),其中c为图片的类别,否则可能会出现错误。
class RMBDataset(Dataset):
def __init__(self, root, resize, mode): # 根据输入mode的不同将数据集分为训练集,验证集和测试集
super(RMBDataset, self).__init__()
self.root = root
self.resize = resize
self.mode = mode
self.name2label = {} # "sq...": 0
for name in sorted(os.listdir(os.path.join(root))[:6], key=int):
if not os.path.isdir(os.path.join(root, name)):
continue
self.name2label[name] = len(self.name2label.keys())
# print(self.name2label[name])
self.images, self.labels = self.load_csv("images.csv")
if self.mode == 'train': # 60% mode=‘train’则生成训练集
self.images = self.images[: int(0.6 * len(self.images))]
self.labels = self.labels[: int(0.6 * len(self.labels))]
elif self.mode == 'val': # 20% = 60% -> 80% mode=‘val’则生成训练集
self.images = self.images[int(0.6 * len(self.images)): int(0.8 * len(self.images))]
self.labels = self.labels[int(0.6 * len(self.labels)): int(0.8 * len(self.labels))]
else: # mode=‘test’则生成训练集
self.images = self.images[int(0.8 * len(self.images)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
def load_csv(self, filename):# 加载文件
if not os.path.exists(os.path.join(filename)):
images = []
for name in self.name2label.keys():
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
random.shuffle(images)
with open(os.path.join(filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images:
name = img.split(os.sep)[-2]
label = self.name2label[name]
writer.writerow([img, label]) # 将图片路径和标签写入csv文件
images, labels = [], []
with open(os.path.join(filename)) as f:
reader = csv.reader(f)
for row in reader:
img, label = row
label = int(label)
images.append(img)
labels.append(label)
assert len(images) == len(labels)
# print(type(images), type(labels[0]))
return images, labels
def denormalize(self, x_hat): # 反归一化
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
x = x_hat * std + mean
return x
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img, label = self.images[idx], self.labels[idx]
# 数据增强
tf1 = transforms.Compose([
lambda x : Image.open(x).convert('RGB'),
transforms.Resize((int(self.resize * 1.25), int(self.resize * 2))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
tf2 = transforms.Compose([
lambda x : Image.open(x).convert('RGB'),
transforms.Resize((int(self.resize * 1), int(self.resize * 1.5))),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
if self.mode == 'test': # 对于测试集数据使用tf2的方式对图片进行数据增强,该方式主要是为了方便可视化查看。
img = tf2(img)
else:
img = tf1(img)
label = torch.tensor(label)
return img, label
根据输入mode的不同分别生成训练集,验证集和测试集
其中训练集占整个数据集的60%,测试集和验证集各占剩余的20%
train_data = RMBDataset('RMBDataset', 256, 'train')
val_data = RMBDataset('RMBDataset', 256, 'val')
test_data = RMBDataset('RMBDataset', 256, 'test')
train_loader = DataLoader(train_data, batch_size=32, shuffle=True, pin_memory=True)
val_loader = DataLoader(val_data, batch_size=32, shuffle=True, pin_memory=True)
test_loader = DataLoader(test_data, batch_size=32, shuffle=True, pin_memory=True)
可视化查看数据集图片
%matplotlib inline
import numpy as np
classes = ['RMB ¥1', 'RMB ¥5', 'RMB ¥10', 'RMB ¥20', 'RMB ¥50', 'RMB ¥100']
images, labels = next(iter(test_loader))
def imshow(img):
img = train_data.denormalize(img).numpy()
img = np.transpose(img, (1, 2, 0))
plt.imshow((img*255).astype('uint8'))
fig = plt.figure(figsize=(25, 4))
for i in range(8):
plt.subplot(2, 4, i+1)
plt.axis('off')
imshow(images[i])
plt.title(classes[labels[i].numpy()], fontdict={'fontsize':18})
输出图片:

使用ResNet18 作为模型来对人民币进行识别
from torchvision import models
resnet = models.resnet18(pretrained=True).to(device)
resnet.fc = torch.nn.Linear(resnet.fc.in_features, 6).to(device)
import torch.optim as optim
import torch.nn as nn
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(resnet.parameters(), lr=0.001)
训练模型并进行交叉验证
训练过程中保存模型在验证集上预测精度最高时的参数,在预测时加载出,以便于取得最好的预测结果。
epoches = 100
best_val_acc = 0.0
running_loss_history = []
running_corrects_history = []
val_running_loss_history = []
val_running_corrects_history = []
for epoch in range(epoches):
running_loss = 0.0
running_corrects = 0.0
val_running_loss = 0.0
val_running_corrects = 0.0
for inputs, labels in train_loader:
resnet.train()
inputs, labels = inputs.to(device), labels.to(device)
outputs = resnet(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, pred = torch.max(outputs, 1)
running_loss += loss.item() * labels.size(0)
running_corrects += torch.sum(pred == labels.data)
with torch.no_grad():
for val_inputs, val_labels in val_loader:
val_inputs, val_labels = val_inputs.to(device), val_labels.to(device)
val_outputs = resnet(val_inputs)
val_loss = criterion(val_outputs, val_labels)
_, val_pred = torch.max(val_outputs, 1)
val_running_loss += val_loss.item() * val_labels.size(0)
val_running_corrects += torch.sum(val_pred == val_labels.data)
epoch_loss = running_loss / len(train_data)
epoch_acc = running_corrects / len(train_data)
running_loss_history.append(epoch_loss)
running_corrects_history.append(epoch_acc)
val_epoch_loss = val_running_loss / len(validation_data)
val_epoch_acc = val_running_corrects / len(validation_data)
val_running_loss_history.append(val_epoch_loss)
val_running_corrects_history.append(val_epoch_acc)
if best_val_acc < val_epoch_acc:
best_val_acc = val_epoch_acc
torch.save(resnet.state_dict(), 'resnet18_best.mdl')
print('epoch: ',(epoch+1))
print('training loss: {:.4f}, acc {:.2f}% '.format(epoch_loss, epoch_acc * 100))
print('validation loss: {:.4f}, validation acc {:.2f}% '.format(val_epoch_loss, val_epoch_acc.item()*100))
print("Best validation acc {:.2f}%".format(best_val_acc * 100))
最后结果如下:
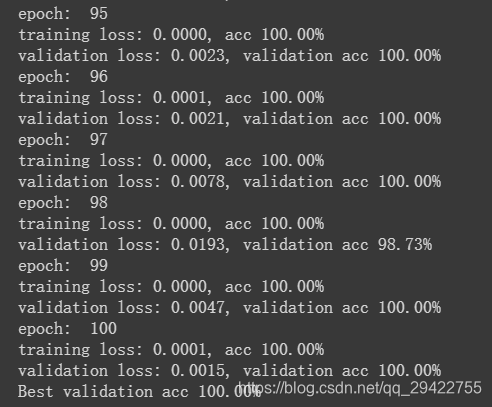
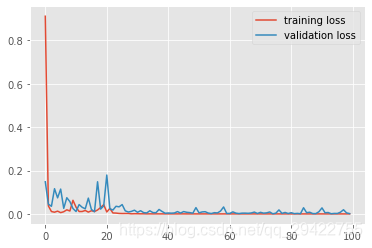
对所记录的模型训练过程中的误差变化和模型在验证集上的预测精度变化进行可视化的展示
# 训练和交叉验证误差变化曲线
%matplotlib inline
plt.style.use('ggplot')
plt.plot(running_loss_history, label='training loss')
plt.plot(val_running_loss_history, label='validation loss')
plt.legend()
# 验证集上模型预测精度的变化
plt.style.use('ggplot')
plt.plot(running_corrects_history, label='training accuracy')
plt.plot(val_running_corrects_history, label='validation accuracy')
plt.legend()
得到图片如下:
训练误差和验证误差变化:
模型在训练集和验证集上的准确率变化:
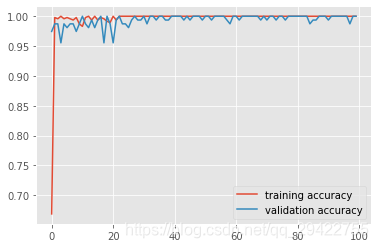
从图片可以看出训练过程是有一定的波动的,但最终模型的预测准确率达到了100%!
测试集测试
# 加载已存储的模型
resnet.load_state_dict(torch.load('ResNet18_best.mdl'))
# 测试集测试
test_loss = 0.0
correct = 0
total = 0
resnet.eval()
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = resnet(images)
loss = criterion(outputs, labels)
test_loss += loss.item() * labels.size(0)
_, pred = torch.max(outputs, 1)
correct += torch.eq(pred, labels).sum().float().item()
total += labels.size(0)
Loss = test_loss / total
test_acc = correct / total
print("Test Loss: {}\tTest Accuracy:{}".format(Loss, test_acc))
预测精度达到了96.8%
用训练好的模型进行人民币识别
输出图片的标签中括号中的为图片的实际面值,括号外为模型预测的面值。
如果识别正确,则标签颜色为绿色,否则为红色。
mean_vals = [0.485, 0.456, 0.406]
std_vals = [0.229, 0.224, 0.225]
def imshow(img):
img = np.transpose(img, (1, 2, 0))
img = img * std_vals + mean_vals
plt.imshow((img * 255).astype('uint8'))
images, labels = iter(test_loader).next()
# images shape [b, 3, 32, 32]
images, labels = images.to(device), labels.to(device)
output = resnet(images)
_, preds = torch.max(output, 1)
preds = np.squeeze(preds.cpu().numpy())
images = images.cpu().numpy()
# 将tensor 转换位 numpy [b, 3, 32, 32]
fig = plt.figure(figsize=(25, 8)) # figsize(width, height)
for i in range(32):
ax = fig.add_subplot(4, 8, i+1)
plt.axis('off')
imshow(images[i]) #对于每个images[i] 其shape为 [3, 32, 32]
ax.set_title("{} ({})".format(classes[preds[i]], classes[labels[i]]),
color=("green" if preds[i]==labels[i].item() else "red"),fontdict={'fontsize':13})
识别效果:

以上就是这次作业的全部内容,作业较为简单,将问题转化为分类问题后使用CNN即可实现。

















 1630
1630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









