






1.分布式文件系统
- 分布式文件系统一般是通过网络实现文件在多台主机上进行分布式存储的文件系统。
- 已得到广泛应用的分布式文件系统主要包括GFS和HDFS等。
- 分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。
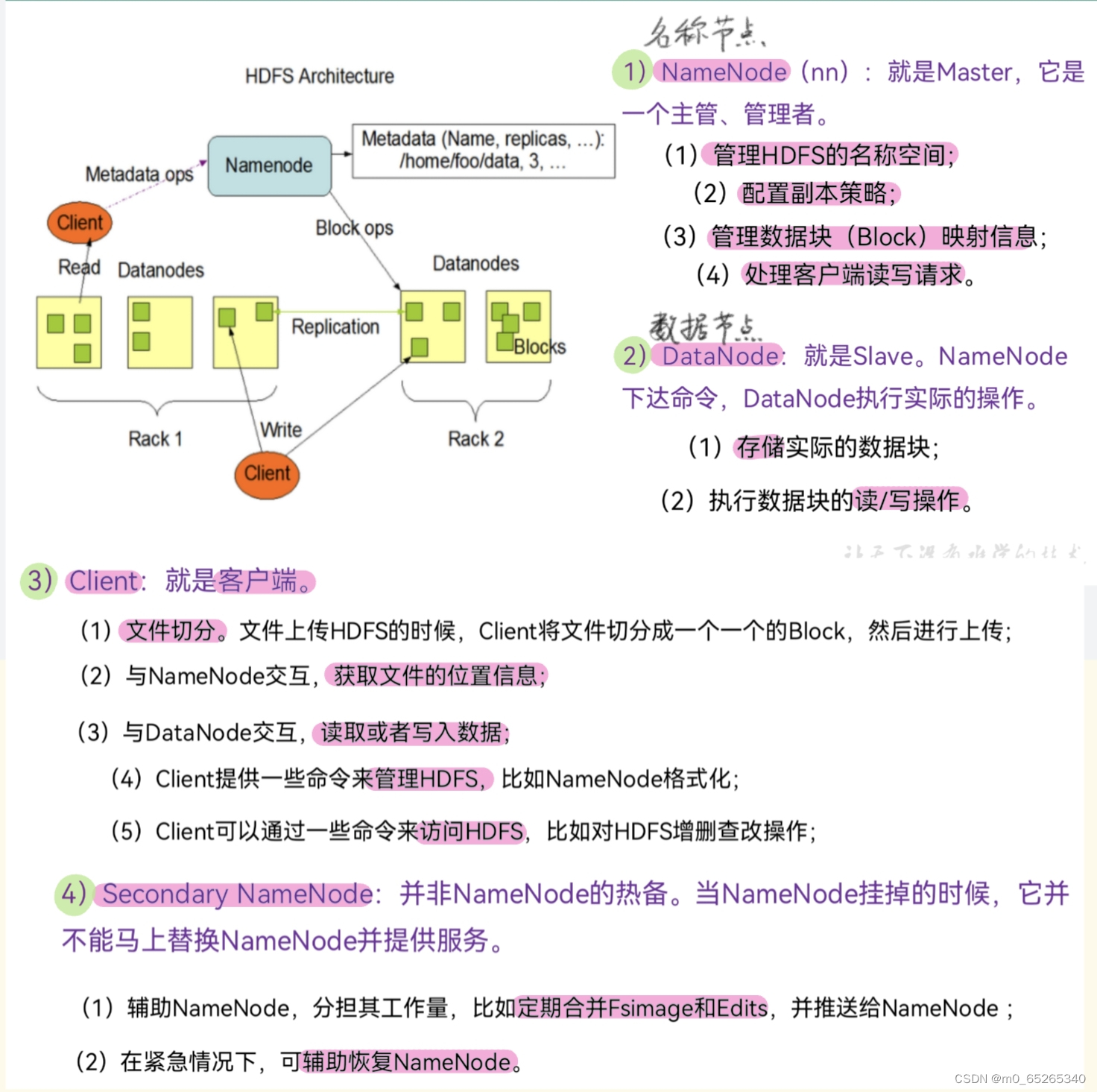
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的。这些节点分为两类:
- 主节点(Master Node)/名称节点(NameNode):负责文件和目录的创建、删除和重命名等。
- 从节点(Slave Node)/数据节点(DataNode):负责数据的存储和读取。
2.HDFS简介及概念
(1)HDFS要实现的目标
- 兼容廉价的硬件设备
- 流数据读写
- 大数据集
- 简单的文件模型
- 强大的跨平台兼容性
(2)HDFS的局限性
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
(3)块
在HDFS中文件会被拆分成多个块,每个块作为独立的单元进行存储。
HDFS中的块大小设置主要取决于磁盘传输速率。不宜设置过大,也不可过小。
HDFS采用抽象的块概念的好处:
- 支持大规模文件存储
- 简化系统设计
- 适合数据备份
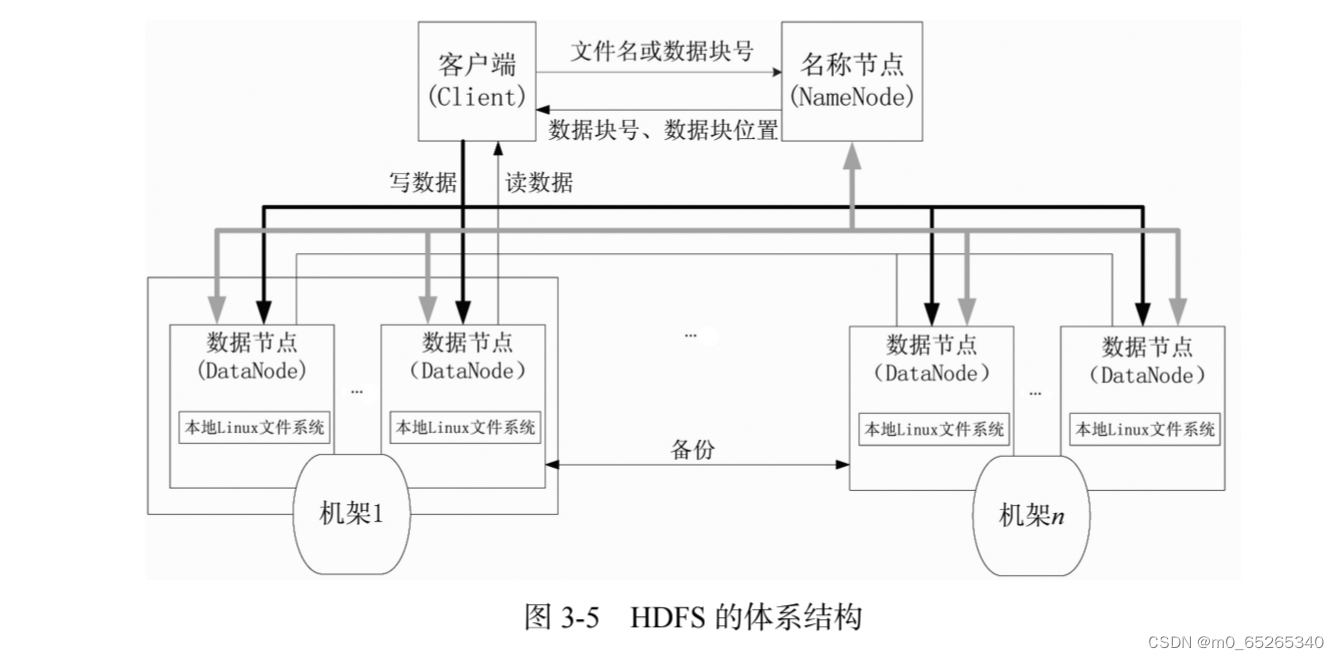
3.HDFS体系结构
HDFS采用了主从结构模型
- 一个HDFS集群包括一个名称节点和若干个数据节点。
- 名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问
- 数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求。
- 每个数据节点会周期性地名称节点发送“心跳”信号,报告自己的状态,没有按时发送心跳信息的数据节点会被标记为“死机”,不会再给他分配任何I/O请求。
4.HDFS的存储原理
为了保证系统的容错性和可用性,HDFS采用了多副本方式对数据进行冗余存储。
HDFS副本的放置策略
- 第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点。
- 第二个副本:放置在与第一个副本不同的机架的节点上。
- 第三个副本:与第一个副本相同机架的其他节点上。
- 更多副本:随机节点
写文件过程
(1)客户端向名称节点发起写文件请求。
(2)名称节点检查请求路径是否存在,并验证客户端的写权限。然后为文件分配数据块ID和副本位置。
(3)客户端从名称节点获取数据块的元数据,包括每个数据块的副本位置。然后,客户端将第一个数据块的数据流传送到第一个数据节点。
(4) 第一个数据节点接收到数据后,立即将其写入本地存储,同时将数据传输到下一个数据节点,形成数据传输流水线,然后其他数据节点重复这俩操作。
(5)当全部都写成功后,最后一个数据节点会通知前一个数据节点直到第一个数据节点,再由第一个数据节点通知客户端写入成功。
读文件过程
(1)客户端向名称节点发起读文件请求。
(2)名称节点根据请求路径,查找文件的元数据并返回数据块的位置(数据节点列表)给客户端。
(3)客户端根据表选择一个最近或最优的数据节点,直接从该数据节点请求数据块。
(4)数据节点将数据块的内容传输给客户端。客户端依次读取每个数据块,直到整个文件读取完毕。
(5)客户端读取完所有数据块后,关闭连接,完成读文件操作。
数据复制采用了流水线复制的策略。
5.HDFS常用命令
- hadoop fs -ls <path>:显示路径指定文件的详细信息
- hadoop fs -cat<path>:将该路径文件输出
- hadoop fs -chown:改变路径文件的对应权限。
- hadoop fs -touchz <path>:在该路径创建一个空文件
- hadoop fs -mkdir <paths>:创建一个文件夹
- hadoop fs -put <localsrc> <dst>:从本地通过hdfs上传到dst
- hadoop fs -mv <src> <dest>:将文件从路径下移动到<dst>
- hadoop fs -rm <path>:删除指定文件
- hadoop fs -rm -r <path>:删除指定文件夹下所有文件还有文件夹自己
6.HDFS常用Java API及应用实例
- 定义过滤器,我们将过滤掉扩展名为“.abc”的文件,这里通过实现接口org.apache.hadoop.fs.PathFilter中的方法accept(Path path),对path指代的文件进行过滤。
- 利用FileSystem.listStatus(Path path,PathFilter filter)方法获得目录path中所有文件经过过滤器filter过滤后的状态对象数组。
- 利用FileSystem.open(Path path)方法获得与路径path相关的FSDataInputStream对象,并利用该对象读取文件的内容。
- 利用Filesystem.create(Path path)方法获得与路径path相关的FSDataOutputStream对象,并利用该对象将字节数组输出到文件。
- 利用FileSystem.get(URI uri,Configuration,conf)方法,根据资源表示符uri和文件系统配置信息conf获得对应的文件系统。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









