






HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库。
1.HBase与传统数据库的区别
数据类型:
- 关系数据库采用关系模型,具有丰富的数据类型和存储方式
- HBase采用了简单的数据模型
数据操作:
- 关系数据库提供了丰富的操作
- HBase提供的操作只有简单的插入、查询、删除、清空等
存储模式:
- 关系数据库是基于行模式存储的
- HBase是基于列存储的
数据索引:
- 关系数据库针对不同列构建复杂的多个索引
- HBase只有一个索引——行键
数据维护:
- 关系数据库更新操作时当前值替换记录中原来的旧值
- HBase更新操作时生成一个新的版本,旧的版本仍然保留(应该是用时间戳来存储的)
可伸缩性:
- 关系数据库很难横向扩展,纵向扩展空间有限
- HBase实现灵活的横向扩展,通过在集群中增加或者减少硬件数量来实现性能的伸缩
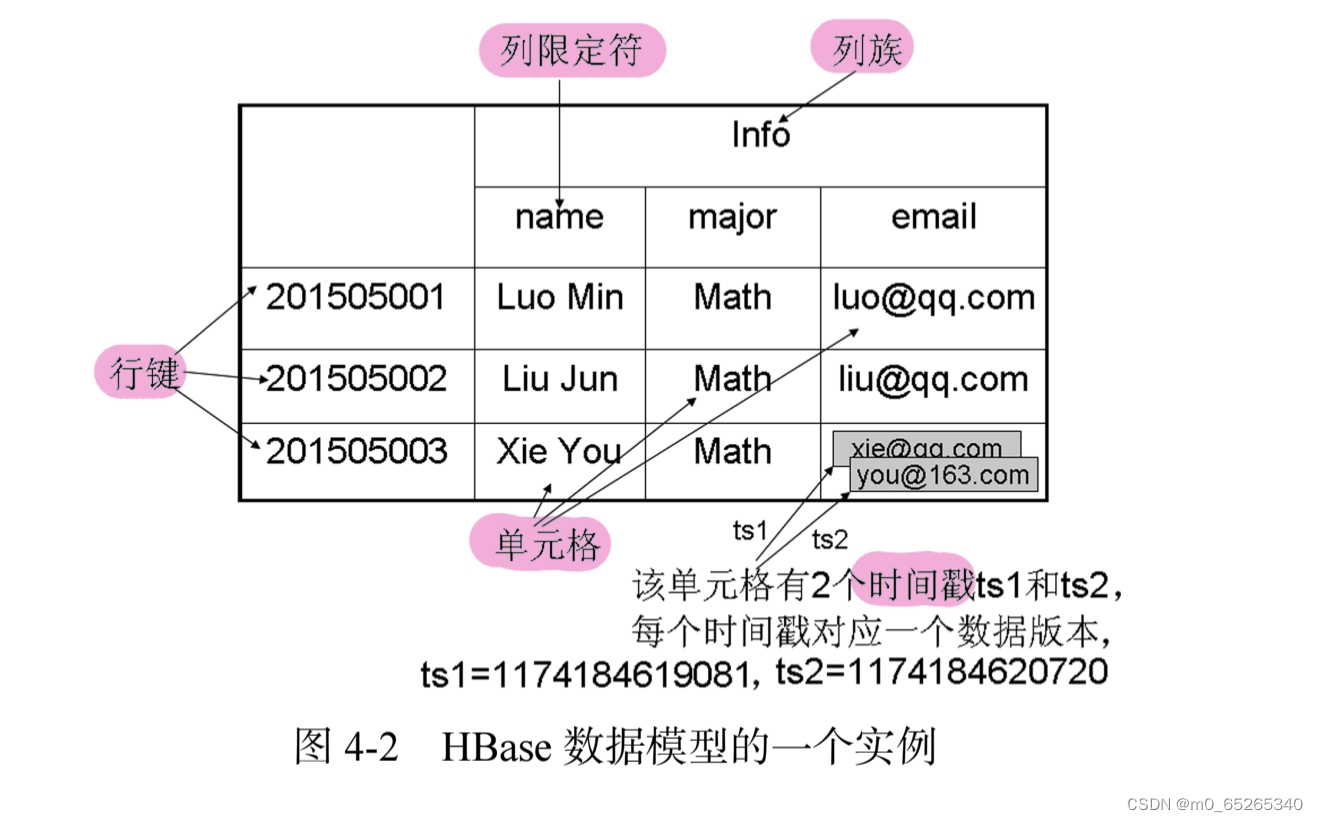
2.HBase数据模型
HBase实际上就是一个稀疏、多维、持久化存储的映射表,他采用行键、列族、列限定符和时间戳进行索引。
- 表:HBase采用表来组织数据,由行和列组成,列划分为若干个列族
- 行键:每个行由行键来标识。
访问表中的行只有三种方式
- 通过单个行键访问
- 通过一个行键的区间来访问
- 全表扫描
- 列族:列划分成为若干个列族,是基本的访问控制单元。
- 列限定符:列族里的数据通过列限定符(或列)来定位。
- 单元格:通过行键、列族和列限定符确定一个“单元格”。
- 时间戳:每个单元格都保存着同一份数据的多个版本,通过时间戳索引。每次对一个单元格执行操作时,HBase都会隐式地自动生成并存储一个时间戳。
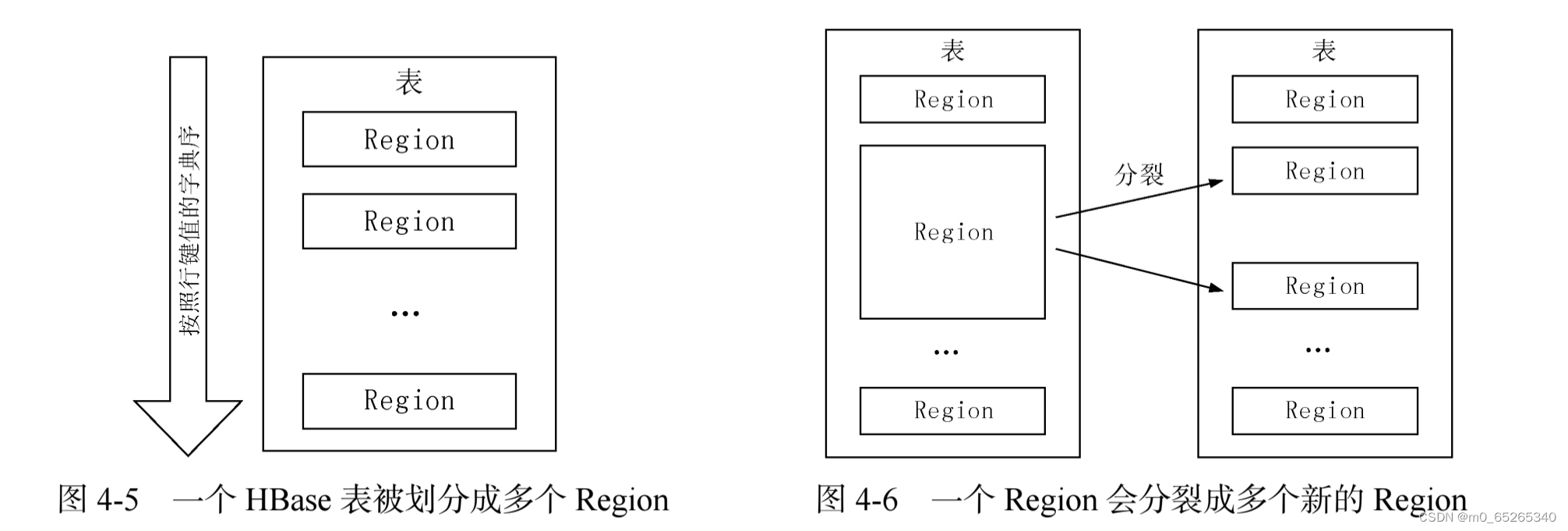
3.Region的概念
- 根据行键的值对表中的行进行分区,每个行区间构成一个分区,被称为“Region”。(图4-5)
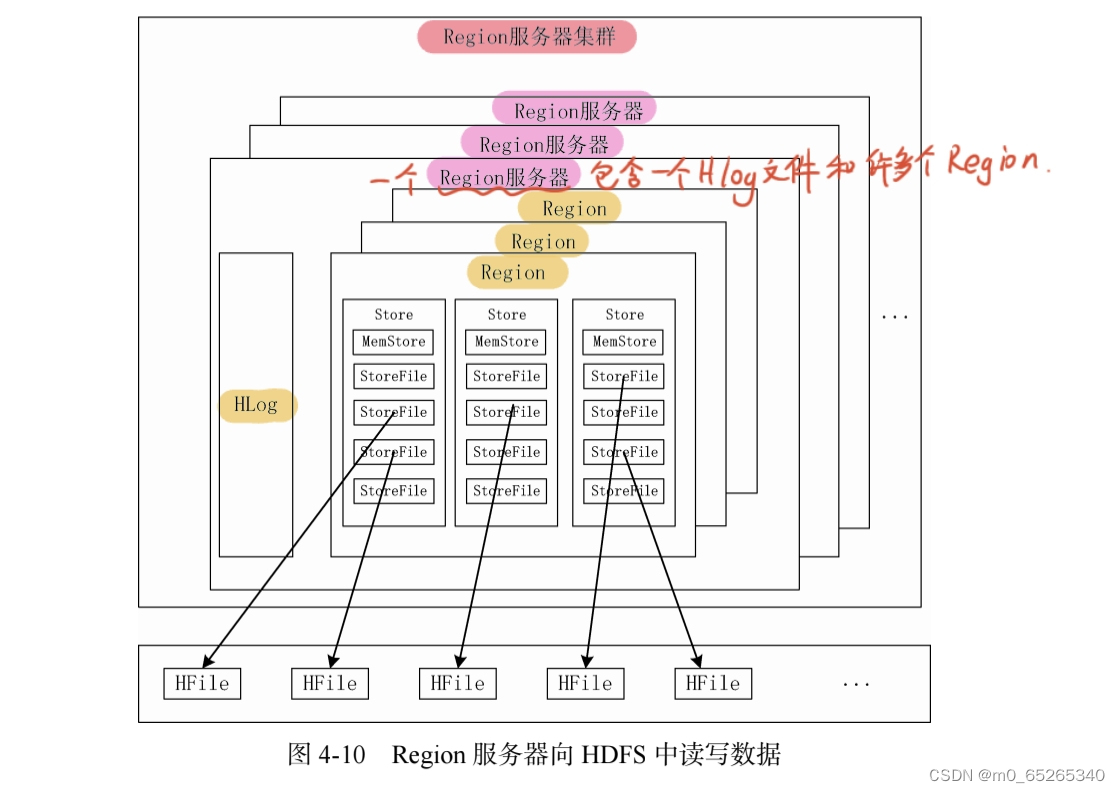
- Region包含了位于某个值域区间内的所有数据,是负载均衡和数据分发的基本单位。这些Region会被分发到不同的Region服务器上。(注:Region服务器与Region不是一个东西,Region服务器中包含很多个Region,后面的图4-10)
- 初始时,每个表只包含一个Region,随着数据的不断插入,Region会持续增大,当一个Region中包含的行数量达到一个阈值时,就会被自动等分成两个新的Region,随着表中行数量继续增加,就会分裂出越来越多Region。(图4-6)
4.Region的定位
Region包含了位于某个值域区间内的所有数据,是负载均衡和数据分发的基本单位。
HBase的三层结构

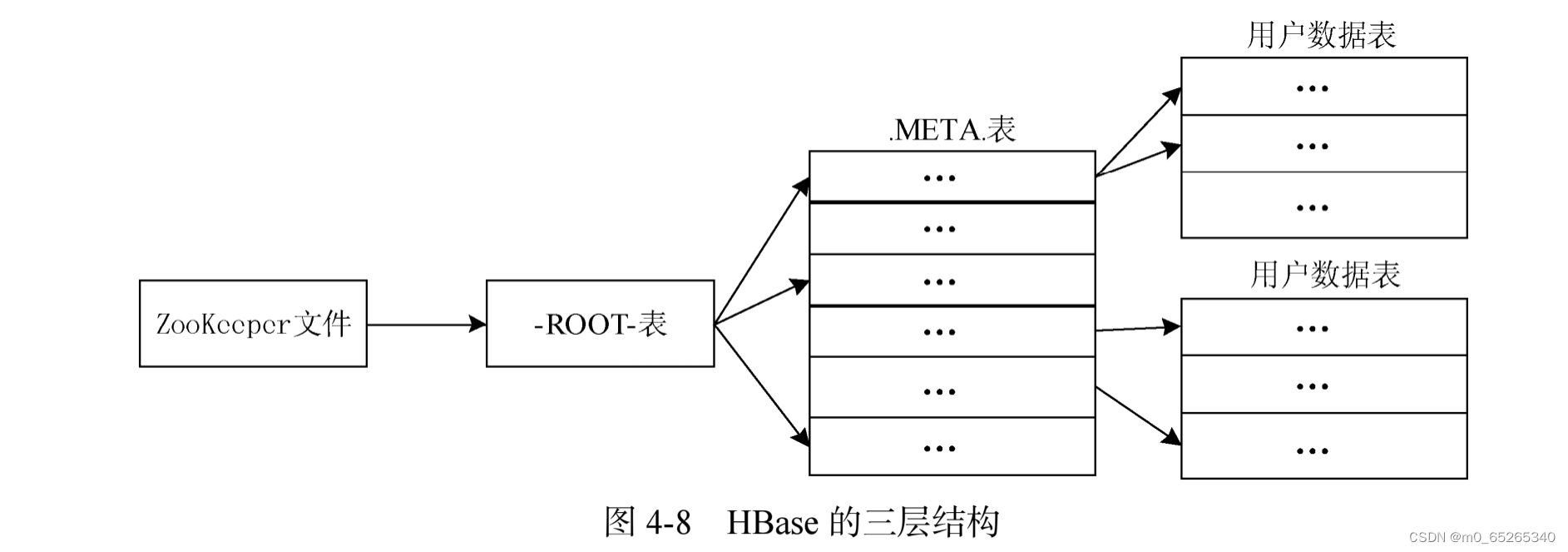
客户端访问用户数据之前,需要首先访问ZooKeeper,获取-ROOT-表的位置信息,然后访问-ROOT-表,获得.META.表的信息,接着访问.META.表,找到所需的Region具体位于哪个Region服务器,最后才会到该Region 服务器读取数据。
5.HBase的功能组件
HBase的实现包括3个主要的功能组件:库函数(链接到每个客户端);一个Master主服务器(也称为Master);许多个Region服务器(每个Region服务器中都有一个Hlog文件和许多个Region)。
- Region服务器负责存储和维护分配给自己的Region,处理来自客户端的读写请求。
- Master主服务器负责管理和维护HBase表的分区信息,也负责维护Region服务器列表。
6.HBase系统架构
HBase的系统架构包括客户端、ZooKeeper服务器、Master主服务器、Region服务器。
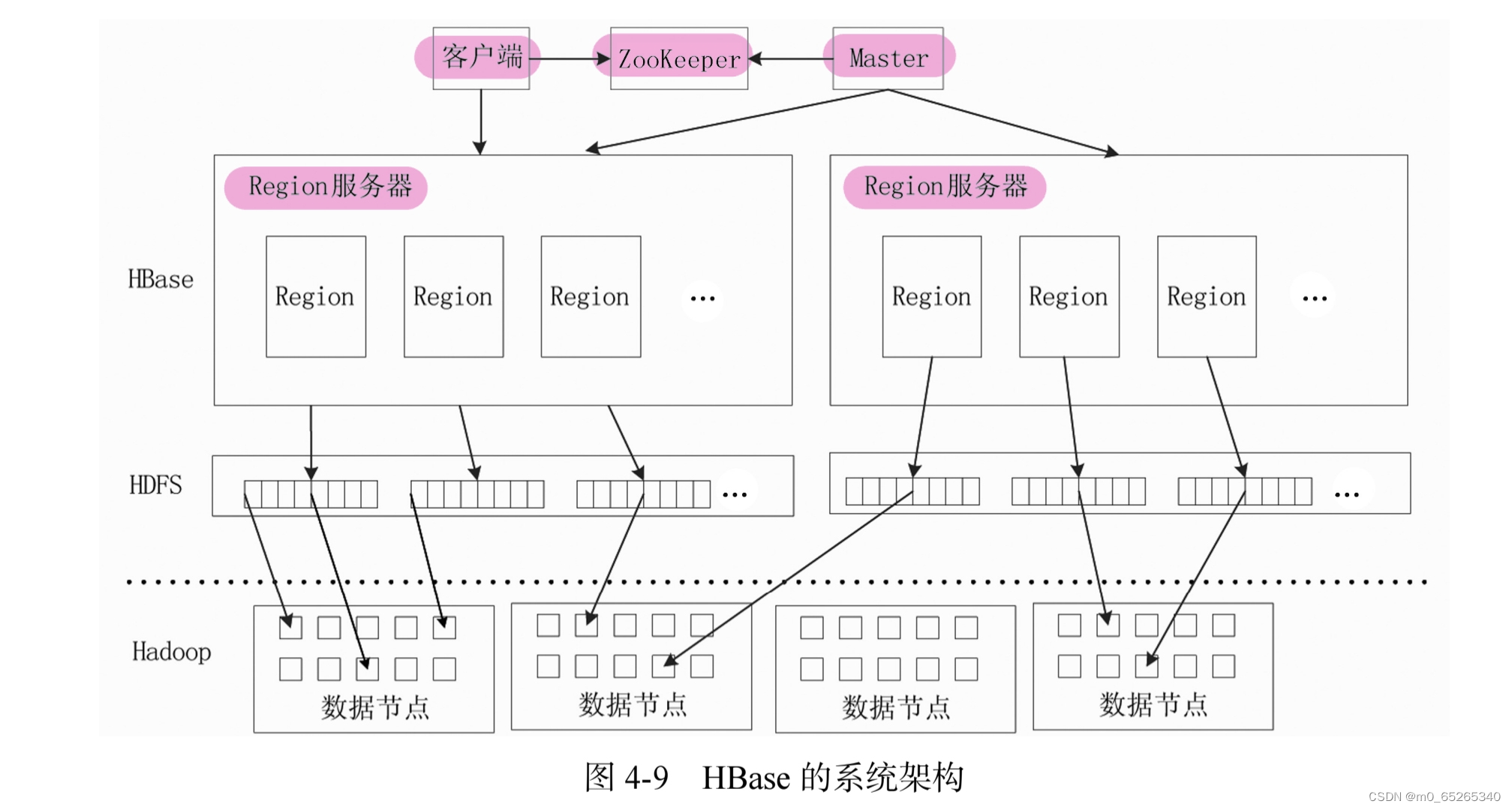
客户端
包含访问HBase 的接口,同时在缓存中维护着已经访问过的Region 位置信息,用来加快后续数据访问过程。
ZooKeeper服务器
- 能够帮助维护当前的集群中机器的服务状态(Master主服务器就可以通过ZooKeeper服务器随时感知到各个Region 服务器的工作状态)
- 帮助选举出一个Master 主服务器作为集群的总管,并保证在任何时刻总有唯一一个Master 主服务器在运行,这就避免了Master主服务器的"单点失效"问题。
Master
Master主服务器主要负责表和Region的管理工作。
- 管理用户对表的增加、删除、修改、查询等操作。
- 实现不同Region服务器之间的负载均衡。
- 在Region分裂或合并后,负责重新调整Region的分布。
- 对发生故障失效的Region服务器上的Region进行迁移。
Region服务器
是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求。
7.HBase编程命令

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









