






SVM、logistic回归等方法都能进行二分类任务,我们可以直接利用这些方法进行多分类,思路是先将问题进行拆解,变成若干个二分类任务,对每个二分类任务进行学习,再将预测结果集成获得多分类结果。拆解方式可以分为一对一、一对其余、多对多三种。
一对一(OvO):
假设因变量共有N类,在其中任取两个类则共有
种组合,对每个组合训练出二分类分类器,并给出预测值,最后对C_N^2个预测结果看哪一个类被预测的次数最多,将其选为最终分类结果。
一对其余(OvR):
假设因变量共有N类,任取其中一个作为+1类,其余N-1个类合并统称为-1类,因此需要训练N个二分类分类器,最后产生N个预测结果,若其中仅有一个为+1类则此+1类的类就是预测结果,若有多个+1类则将它们中预测置信度最高者选为预测结果。

多对多(MvM):
最常用的技术叫做纠错输出码(ECOC),假设因变量有C_1, ..., C_N共N个类,我们取M个(即编码长度为M)二分类分类器f_1, ..., f_M,任意f_j将N个类中的一部分(大于等于1小于N个)作为+1类,剩余作为-1类,这样任意C_i都得到了长度为M的编码。使用M个二分类器得到长度为M的预测值编码,然后计算预测值编码和C_1, ..., C_N的编码的距离,距离最小的类C_min就是预测分类。
注意除了+1和-1这种编码方式叫做二元码,除此之外还有三元码,即+1, -1和0,0表示停用类。
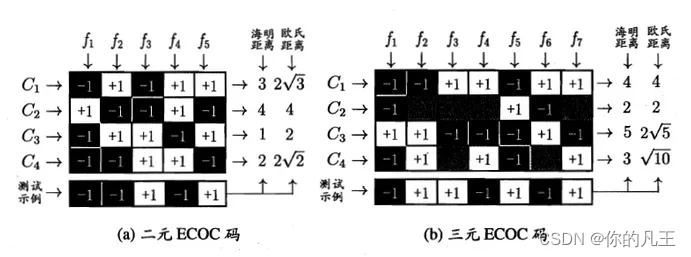
ECOC对分类器的错误有一定容忍和修正能力,少数分类器预测出错仍有可能得到正确的最终分类。对同一个任务,ECOC编码越长纠错能力越强,计算和存储代价也越大,此外有限的类别数可能得组合数是有限的,编码长度超过一定范围就失去了意义。
对同等长度的编码,任意两个类别之间的编码距离越远则纠错能力越强,码长较小时可按此原则设计出最优编码,但是实践中非最优的编码也能产生足够好的分类器。















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









