







需要先进行hadoop安装
hadoop - hdfs
hadoop - MapReduce -yarn
1、安装anaconda
下载annaconda
上传安装包到linux目录中:

执行shell文件:
sh ./Anaconda3-5.3.1-Linux-x86_64.sh
# 执行命令后进行安装目录指定
-> 执行后回车
-> 输入yes

-> 输入annaconda存储的路劲
-> 输入yes初始化
重启服务器,配置anaconda:
```linux
reboot
vim ~/.condarc
# 增加如下内容
nnels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
auto_activate_base: false
# 创建一个pyspark虚拟空间
conda create -n pyspark python=3.8
2、安装spark
spark下载
上传下载文件:

tar -zxvf spark-3.2.0-bin-hadoop3.2-scala2.13.tgz -C ../soft/
# 进入到soft目录中,该一个短的名称
mv spark-3.2.0-bin-hadoop3.2-scala2.13 saprk320
配置环境变量:
vim ~/.bashrc
# 安装jdk已经配置的
export JAVA_HOME=/home/kk/export/soft/jdk18
export HADOOP_HOME=/home/kk/export/soft/hadoop336
# 新增配置
export SPARK_HOME=/home/kk/export/soft/spark320
export PYSPARK_PYTHON=/home/kk/export/soft/anaconda1/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
本地模式配置完毕:
进入spark安装目录/bin 执行pyspark:
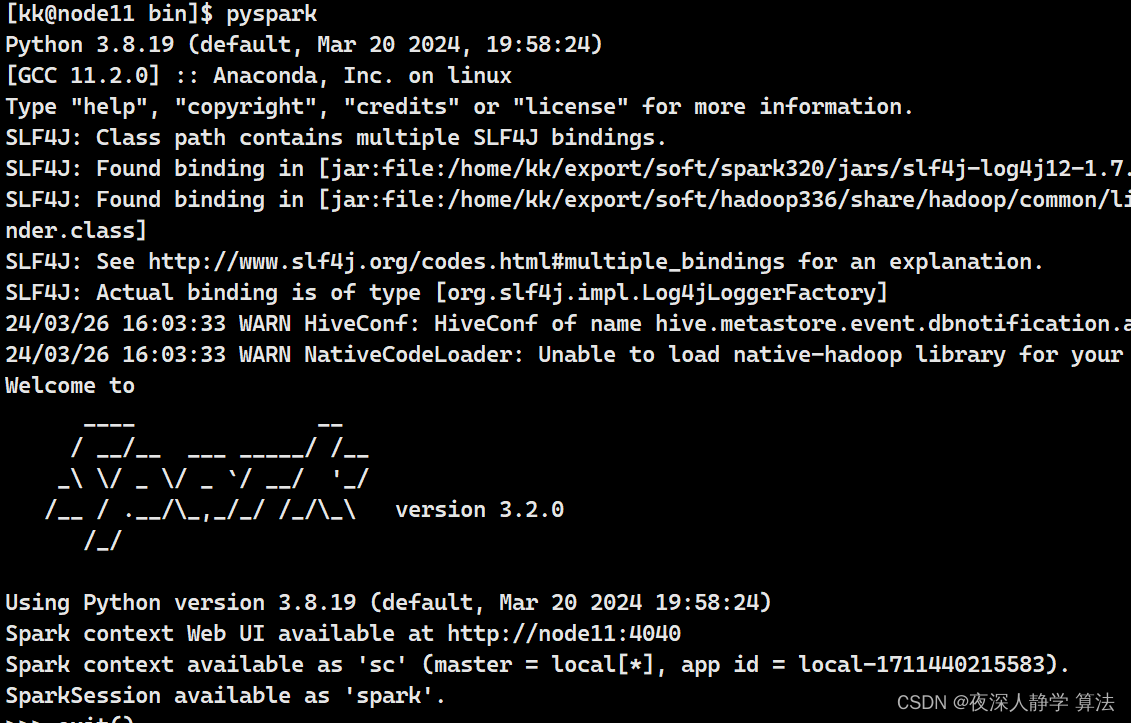
3、spark 集群模式搭建
配置spark配置文件 - 进入到spark安装目录下的conf目录中
配置workers文件:
vim workers
# 配置集群主机
node11
node22
node33
配置spark-env.sh文件:
vim spark-env.sh
# HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
#export SPARK_MASTER_HOST=node11
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的webui端口
SPARK_MASTER_WEBUI_PORT=8082
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
#将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中,需要在hdfs中创建文件
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node11/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
配置spark-defaults.conf文件
vim spark-defaults.conf
# 开启spark的日期记录功能
spark.eventLog.enabled true
# # 设置spark日志记录的
# # 设置spark日志是否启动压缩
spark.eventLog.compress true
node2 和 node3 中也需要安装annaconda
分发spark :
scp -r spark320 node22:`pwd`
scp -r spark320 node33:`pwd`
在spark目录下启动spark节点:
./sbin/start-all.sh

浏览器web端查看:
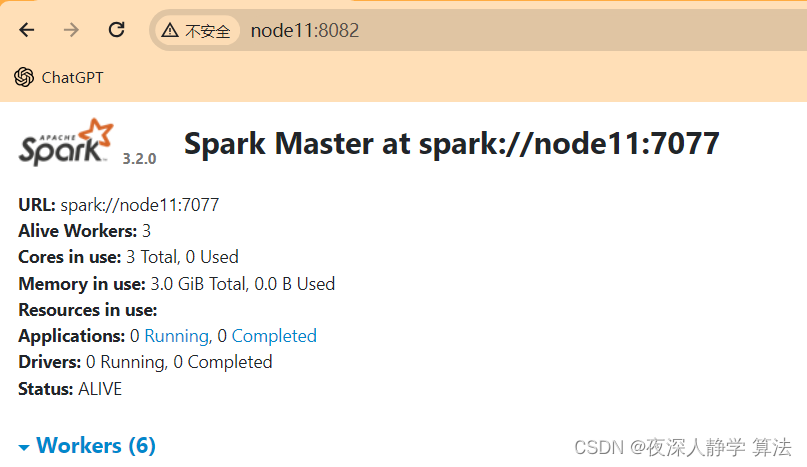
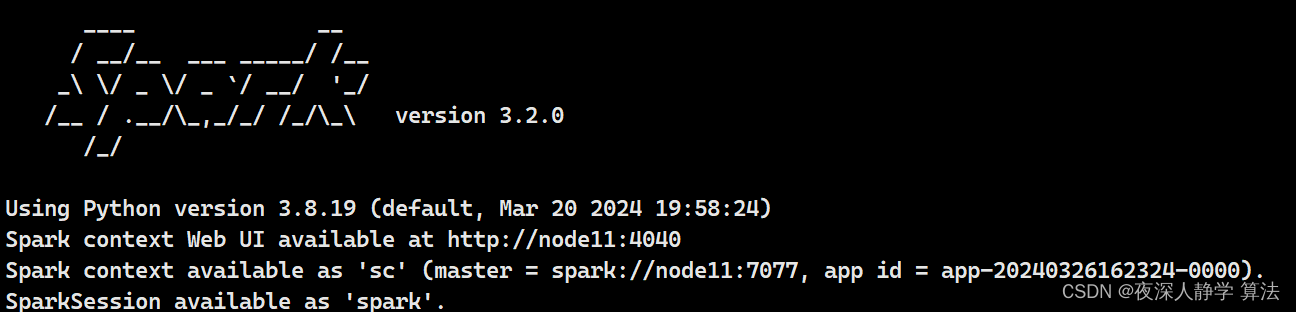
启动集群pyspark:
pyspark --master spark://node11:7077
4、 spark高可用搭建
配置spark-env.sh文件
vim spark-env.sh
# 配置ha模式
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=node11:2181,node22:2181,node33:2181
-Dspark.deploy.zookeeper.dir=/spark"
配置spark-defuldes.sh文件
# xjycluster为namenode逻辑地址名
spark.hadoop.fs.defaultFS hdfs://xjycluster
# 在hdfs上的日志存储路劲,需要自己创建
spark.eventLog.dir hdfs://xjycluster/sparklog
在node1中启动集群:
sbin/start-all.sh
# 在node2中启动master
sbin/start-master.sh
浏览器中可以查看两个master

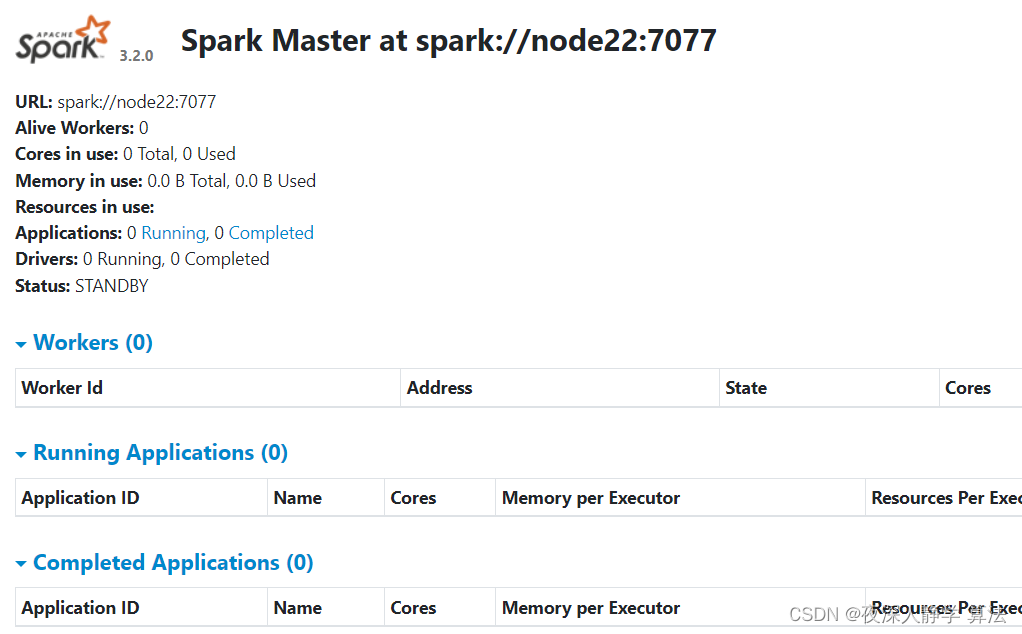
# 杀死node1中的master进程查看
skill -9 进程号
等待一段时间后查看node2的master:

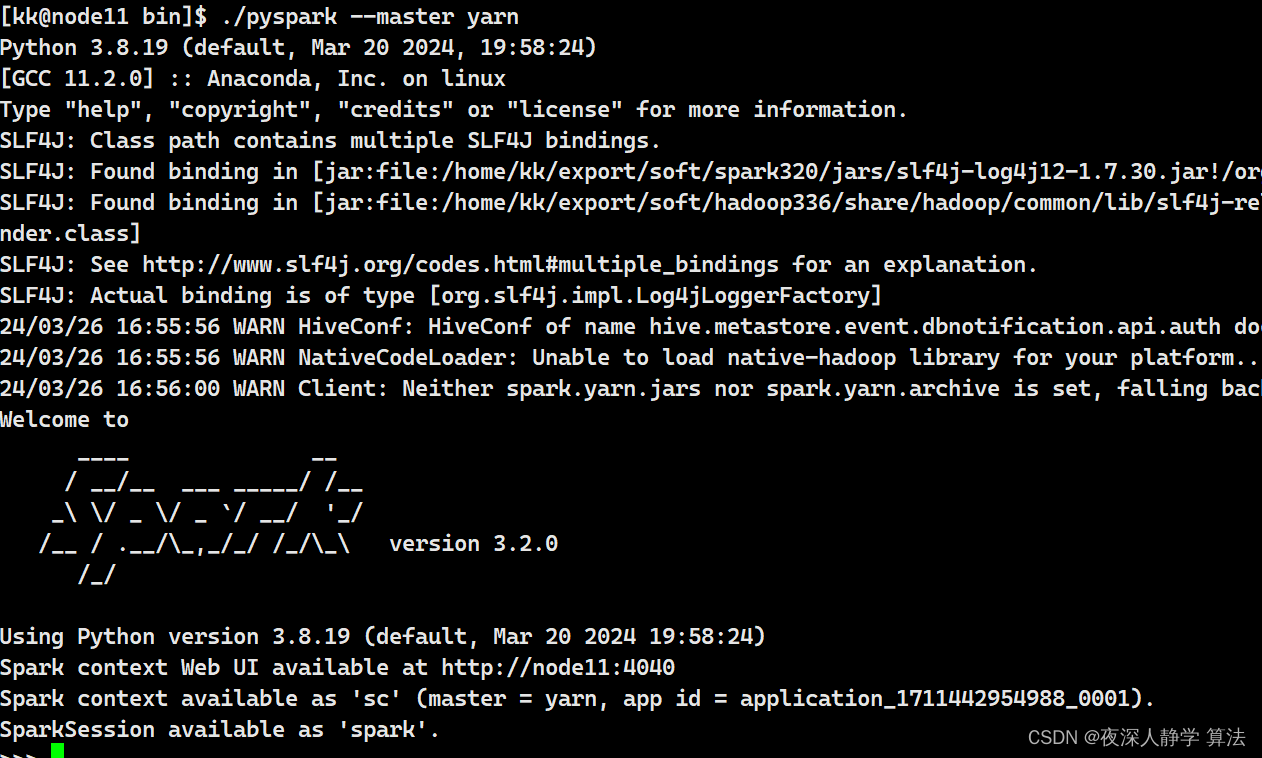
5 spark yarn模式
# master地址指定为yarn即可
./pyspark --master yarn














 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









