






 本文讲述了在使用OpenCV进行计算机视觉项目时,理解matchesMask参数以及如何运用ratiotest来筛选匹配对的重要性。作者通过实例解释了knnMatch方法返回的匹配结构,并讨论了最佳匹配与次佳匹配的距离关系及其在实际应用中的意义。
本文讲述了在使用OpenCV进行计算机视觉项目时,理解matchesMask参数以及如何运用ratiotest来筛选匹配对的重要性。作者通过实例解释了knnMatch方法返回的匹配结构,并讨论了最佳匹配与次佳匹配的距离关系及其在实际应用中的意义。
最近在写计算机视觉的作业,一开始matchesMask参数我完全没get到是什么意思,搜了很多篇文章之后才差不多弄懂,写个文章记录一下吧,有错的话欢迎指出!前面的读取图片、使用sift提取关键点、创建FLANN对象就不贴代码了,下面只说明比率测试的部分:
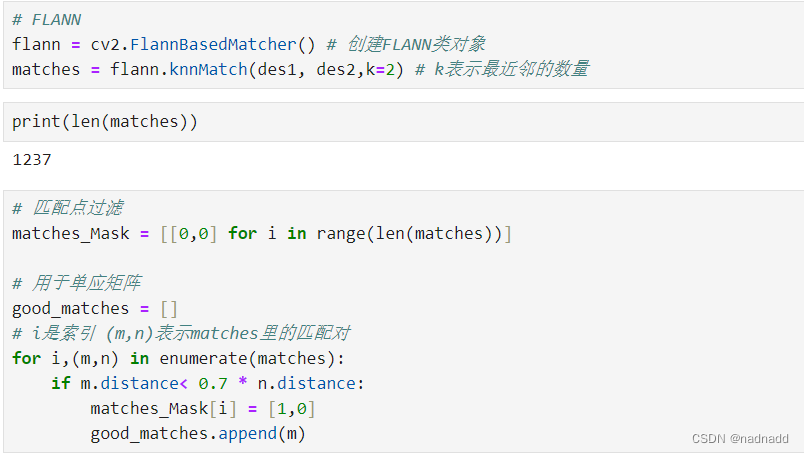
首先这里的good_matches是用于后面的单应矩阵的,和cv2.drawMatchesKnn方法无关,重点在matches_mask上面。
我看了一篇文章(链接在文末),其中提到knnMatch()方法返回的是2个最佳匹配,matches和matchesMask都是二维列表。在我的代码里FLANN匹配中,knnMatch(des1,des2,k=2)方法设置的参数k为2,也就是说寻找的最近邻数量为2,那么在返回的最佳匹配的列表matches中,其中每个匹配项包含了两个最佳匹配,也就是一个是最佳匹配,一个是次佳匹配,具体来说:
-matches[i]:代表第i个关键点的匹配结果
-matches[i][0]:代表第i个关键点的最佳匹配
-matches[i][1]:代表第i个关键点的次佳匹配
在这种情况下,每个匹配项是一个包含两个元素的列表,第一个元素m是最佳匹配,第二个元素n是次佳匹配。因此在循环中 for i,(m,n) in enumerate(matches): 遍历每个匹配项,其中m是最佳匹配,n是次佳匹配。然后我问了一下gpt,其给出的回答是:
理论上,最佳匹配的距离(m.distance)应该比次佳匹配的距离(n.distance)要小。这是因为在匹配过程中,最佳匹配是最相似的,所以它们的距离应该更接近于零。而次佳匹配可能是在另一个不太相似的特征点上,距离相对较远。
但是在实际的应用中,特征点的质量可能会受到噪声、遮挡或者其他因素的影响,这可能导致次佳匹配的距离与最佳匹配的距离非常接近,甚至有时次佳匹配的距离可能会更小(这种特征点是受到了影响的,不那么标准的)。因此,采用比率测试来筛选匹配对,可以帮助减少错误匹配的数量,提高匹配的准确性。
所以我理解的是,在代码里,如果某个匹配对的最佳匹配距离小于次佳匹配距离的70%(也就是说最佳匹配和次佳匹配的距离相差比较大,则最佳匹配被认为是更加可靠的,如果距离很相近的话,则有可能这个匹配点受到的影响比较大,得到的匹配结果也不这么可靠),则被认为是“好的匹配”。这种筛选就可以帮助去除一些不太可靠的匹配,提高整体匹配的质量。
而对于代码里的[0,0]和[1,0],我理解的是通过m.distance< 0.7 * n.distance筛选掉这种受到了影响的特征点,满足该条件的点标注为[1,0],应该是表示使用最佳匹配、不使用次佳匹配;不满足条件的点标注为[0,0],表示最佳匹配和次佳匹配都不使用。
以下是代码运行结果:
(1)不采用比率测试的匹配结果(应该是把所有匹配点的最佳和次佳匹配都画出来了):

(2)比率测试设置为0.85(效果还是比较乱七八糟的,但大部分是符合预期的连线)

(3)比率测试设置为0.7(也就是最佳匹配和次佳匹配的差距比较大,筛掉了更多受影响的不靠谱的匹配点,明显看出留下来的线条都是符合预期的匹配连线)

我也不知道理解的有没有问题,大概是这个意思吧!有说错的地方欢迎指出!
下面这篇文章标题是“OpenCV-Python|Feature模块 — drawMatches()与drawMatchesKnn()分析”,不知道链接点不点的开















 3420
3420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









