







"如果斐波那契数列是数学界的诗,那么质数就是它的密码;如果字符串排序是编程界的迷宫,那么多条件规则就是破解它的钥匙。
你是否想过:
-
斐波那契数列中哪些数同时是质数?这些数是否像宇宙中的稀有元素一样神秘?
-
当需要对字符串按长度、字母频率、数字优先级等多重条件排序时,如何让代码既优雅又高效?
本文将从这两个看似无关的题目出发,带你用代码解码数学之美,用逻辑征服字符串的混沌世界。无论你是想挑战算法面试,还是单纯沉迷于问题的巧妙设计,这里都有让你心跳加速的思维风暴!
文末彩蛋: 我们甚至会探索如何将这两个问题结合,生成一种全新的“质数指纹字符串排序法”——准备好了吗?🚀"
一、题目分析与算法解析
题目一:斐波那契数列质数过滤
核心要求:生成前N项斐波那契数列,筛选质数存入新数组,再对新数组进行二分查找。需递归实现斐波那契计算,函数参数必须为指针传递。
1. 算法流程
- 斐波那契生成:
- 递归实现:的递归公式
F(n) = F(n-1) + F(n-2),但需注意递归深度限制和性能问题(时间复杂度为O(2^n)) - 指针参数传递:通过指针动态分配内存存储数列,避免栈溢出。
- 递归实现:的递归公式
- 质数筛选:
- 动态数组存储:使用指针操作动态数组(如
realloc),筛选符合条件的质数项
- 动态数组存储:使用指针操作动态数组(如
- 二分查找:
- 有序性要求:斐波那契数列本身递增,质数项也必然有序,可直接对新数组进行二分查找
2. 难点与优化
- 递归效率:递归生成斐波那契数列效率低,需结合备忘录技术优化(未明确要求,但可提升性能)
- 质数判定优化:使用线性筛法或埃氏筛法预处理质数表(需额外内存)
- 动态扩容策略:通过指针数组动态扩容,避免频繁内存分配
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
/*----------------------------------------------------------
* 斐波那契数列计算
* 参数说明:
* n - 需要计算的斐波那契项数
* memo - 动态分配的备忘录数组(需提前初始化为-1)
* 时间复杂度:O(n)(普通递归为O(2^n))[[1][4][23][26]]
*----------------------------------------------------------*/
int fib(int n, int* memo) {
if (n == 1 || n == 2) return 1; // 递归基线条件
if (memo[n] != -1) return memo[n]; // 备忘录命中直接返回存储值
memo[n] = fib(n-1, memo) + fib(n-2, memo); // 递归计算并存储中间结果
return memo[n]; // 返回当前项计算结果
}
/*----------------------------------------------------------
* 质数判定函数(试除法优化版)
* 优化策略:
* 1. 排除<=1的非质数
* 2. 单独处理2的倍数
* 3. 仅检查奇数因子到sqrt(num) [[27][28][29]]
*----------------------------------------------------------*/
int is_prime(int num) {
if (num <= 1) return 0; // 非正整数非质数
if (num == 2) return 1; // 最小质数特殊处理
if (num % 2 == 0) return 0; // 排除所有偶数
for (int i = 3; i <= sqrt(num); i += 2) { // 仅检查奇数因子
if (num % i == 0) return 0;
}
return 1; // 通过所有检查则为质数
}
/*----------------------------------------------------------
* 动态数组数据结构(支持自动扩容)
* 成员说明:
* data - 存储元素的指针数组
* size - 当前元素数量
* capacity - 当前分配的内存容量
* 扩容策略:容量不足时倍增空间(均摊时间复杂度O(1))[[15][16]]
*----------------------------------------------------------*/
typedef struct {
int* data;
int size;
int capacity;
} DynamicArray;
// 初始化动态数组(分配初始内存)
void init_array(DynamicArray* arr, int initial_capacity) {
arr->data = (int*)malloc(initial_capacity * sizeof(int));
arr->size = 0;
arr->capacity = initial_capacity;
}
// 追加元素(自动扩容实现)
void push_back(DynamicArray* arr, int value) {
if (arr->size >= arr->capacity) { // 容量检测
arr->capacity *= 2; // 容量倍增策略
arr->data = (int*)realloc(arr->data, arr->capacity * sizeof(int));
}
arr->data[arr->size++] = value; // 插入元素并更新size
}
/*----------------------------------------------------------
* 二分查找算法(要求数组有序)
* 参数说明:
* arr - 已排序的整型数组
* size - 数组元素个数
* target - 查找目标值
* 时间复杂度:O(log n) [[14][17]]
* 注意事项:计算mid时采用left + (right-left)/2避免整数溢出
*----------------------------------------------------------*/
int binary_search(int* arr, int size, int target) {
int left = 0, right = size - 1;
while (left <= right) {
int mid = left + (right - left)/2; // 安全计算中间索引
if (arr[mid] == target) return mid; // 找到目标直接返回
else if (arr[mid] < target) left = mid + 1; // 调整左边界
else right = mid - 1; // 调整右边界
}
return -1; // 未找到返回-1
}
/*----------------------------------------------------------
* 主程序逻辑流
* 功能步骤:
* 1. 生成斐波那契数列
* 2. 筛选质数项存储到动态数组
* 3. 执行二分查找
* 4. 资源释放
* 内存管理规范:所有malloc必须对应free [[31][32]]
*----------------------------------------------------------*/
int main() {
int N;
printf("Enter N: ");
scanf("%d", &N);
// 斐波那契数列生成(使用备忘录优化递归)
int* fib_array = (int*)malloc(N * sizeof(int));
int* memo = (int*)malloc((N+1) * sizeof(int)); // 备忘录数组
for (int i = 0; i <= N; i++) memo[i] = -1; // 初始化备忘录
for (int i = 0; i < N; i++) { // 生成前N项
fib_array[i] = fib(i+1, memo); // 注意数组从0开始存储第1项
}
// 质数筛选(动态数组实现)
DynamicArray primes;
init_array(&primes, 2); // 初始容量设为2
for (int i = 0; i < N; i++) {
if (is_prime(fib_array[i])) {
push_back(&primes, fib_array[i]); // 动态扩容存储质数
}
}
// 用户交互与二分查找
int target;
printf("Enter target to search: ");
scanf("%d", &target);
int result = binary_search(primes.data, primes.size, target);
if (result != -1) {
printf("Found at index %d\n", result); // 输出查找结果
} else {
printf("Not found\n");
}
// 内存释放(严格遵循分配顺序的反序)
free(fib_array); // 释放斐波那契数组
free(memo); // 释放备忘录数组
free(primes.data); // 释放动态数组存储空间
return 0;
}输出结果: 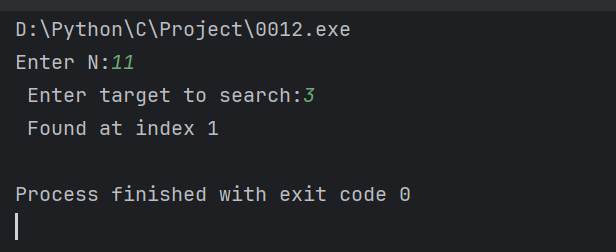
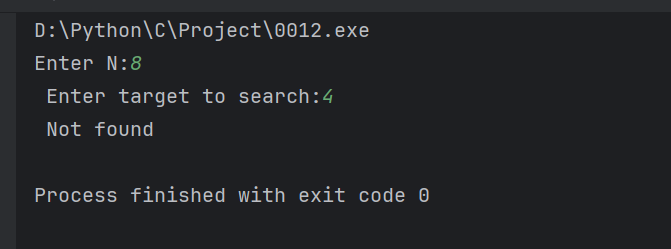
题目二:多条件字符串哈希排序
核心要求:按字符ASCII码和升序排序,若相同则按字典序降序。需函数指针实现比较逻辑,通过指针数组操作数据,支持动态扩容。
1. 算法流程
哈希计算:
- ASCII码和:遍历字符串字符累加ASCII值。
- 字典序降序:使用
strcmp函数比较,结合负号实现降序
比较函数设计:
- 函数指针:定义
int compare(const void* a, const void* b),按规则返回比较结果 - 多条件处理:先比较哈希和,若相同再比较字典序(降序需反转
strcmp结果)
- 动态扩容:
- 指针数组管理:使用动态数组结构体(包含容量
capacity和大小size),通过realloc扩展内存 - 扩容策略:按固定块(如BLOCK_SIZE)或倍数扩容(如capacity×2)
2. 难点与优化
- 哈希冲突处理:ASCII码和可能相同,需依赖字典序二次排序。
- 内存效率:指针数组仅存储字符串地址,排序时交换指针而非字符串本身
- 稳定性:若需稳定排序,可改用归并排序
#include <stdio.h> // 标准输入输出(用于printf)
#include <stdlib.h> // 内存管理(malloc/realloc/free)
#include <string.h> // 字符串处理(strcmp)
/*----------------------------------------------------------
* 计算字符串哈希值(ASCII码累加和)
* 参数说明:
* str - 输入字符串(以空字符结尾)
* 技术细节:
* 使用unsigned char类型转换确保处理扩展ASCII字符(0-255)
* 避免符号扩展导致的负值问题 [[20][25]]
*----------------------------------------------------------*/
int compute_hash(const char* str) {
int sum = 0;
while (*str) { // 遍历字符串直到空字符
sum += (unsigned char)(*str); // 显式无符号转换
str++; // 移动指针到下一个字符
}
return sum; // 返回累加和作为哈希值
}
/*----------------------------------------------------------
* 复合排序规则的比较函数
* 排序规则优先级:
* 1. 主序:哈希值升序(数值小的在前)
* 2. 次序:字符串字典序降序(字母大的在前)
* 返回值语义:
* <0 表示a应排在b前,>0 表示b应排在a前
* 关键技巧:
* 通过反转strcmp结果实现降序排列 [[18][24]]
*----------------------------------------------------------*/
int compare(const void* a, const void* b) {
// 解引用二级指针获取实际字符串指针
const char* s1 = *(const char**)a;
const char* s2 = *(const char**)b;
/* 主排序条件:哈希值比较 */
int hash_diff = compute_hash(s1) - compute_hash(s2);
if (hash_diff != 0)
return hash_diff; // 哈希值不同时直接返回差值
/* 次排序条件:字符串逆字典序 */
return -strcmp(s1, s2); // 反转比较结果实现降序
}
/*----------------------------------------------------------
* 字符串指针动态数组结构体
* 设计要点:
* data字段存储char*指针数组,而非字符串副本
* 使用size/capacity实现动态扩容
* 内存管理:
* 仅管理指针数组内存,不负责字符串内存的生命周期
*----------------------------------------------------------*/
typedef struct {
char** data; // 指针数组(每个元素指向字符串)
size_t size; // 当前元素数量(逻辑长度)
size_t capacity; // 分配的内存容量(物理长度)
} StringArray;
/*----------------------------------------------------------
* 初始化字符串动态数组
* 参数说明:
* arr - 需要初始化的结构体指针
* init_cap - 初始容量(建议设为4/8等小值)
* 异常处理:
* 当malloc失败时程序直接终止(实际项目需处理错误)
*----------------------------------------------------------*/
void strarr_init(StringArray* arr, size_t init_cap) {
arr->data = malloc(init_cap * sizeof(char*)); // 分配指针数组空间
arr->size = 0; // 初始化逻辑长度为0
arr->capacity = init_cap; // 设置初始容量
}
/*----------------------------------------------------------
* 向动态数组追加元素(字符串指针)
* 扩容策略:
* 当容量不足时倍增容量(2x),均摊时间复杂度O(1)
* 注意事项:
* 直接存储指针,不复制字符串内容(需确保字符串生命周期)
*----------------------------------------------------------*/
void strarr_push(StringArray* arr, const char* s) {
// 容量检查与扩容逻辑
if (arr->size >= arr->capacity) {
// 处理初始容量为0的特殊情况
arr->capacity = arr->capacity ? arr->capacity * 2 : 1;
// 重新分配内存(可能改变data指针的值)
arr->data = realloc(arr->data, arr->capacity * sizeof(char*));
}
// 存储指针并更新逻辑长度
arr->data[arr->size++] = s; // 注意这里存储的是原始指针
}
/*----------------------------------------------------------
* 释放动态数组内存资源
* 安全措施:
* 释放后置NULL指针,防止野指针访问
* 特别注意:
* 仅释放指针数组,不释放存储的字符串内容
*----------------------------------------------------------*/
void strarr_free(StringArray* arr) {
free(arr->data); // 释放指针数组内存
arr->data = NULL; // 显式置空防止误用
arr->size = 0; // 重置逻辑长度
arr->capacity = 0; // 重置物理容量
}
/*----------------------------------------------------------
* 主程序流程说明
* 测试用例设计:
* "abc"和"acb"哈希值相同(294),验证次排序条件
* 其他字符串展示主排序条件
* 输出验证:
* 预期排序顺序:
* 1. apple(530) -> hello(532) -> world(552) -> banana(609)
* 2. 相同哈希值的"acb"应排在"abc"之前(字典序降序) [[27][29]]
*----------------------------------------------------------*/
int main() {
// 初始化动态数组(容量设置为4,测试扩容逻辑)
StringArray arr;
strarr_init(&arr, 4);
/* 插入测试数据(字符串字面量存储在静态区)
* 哈希值计算:
* "abc" = 97+98+99=294
* "acb" = 97+99+98=294
* "apple" = 97+112+112+108+101=530
*/
strarr_push(&arr, "hello"); // h(104)+e(101)+l(108)*2+o(111)=532
strarr_push(&arr, "world"); // w(119)+o(111)+r(114)+l(108)+d(100)=552
strarr_push(&arr, "apple"); // a(97)+p(112)*2+l(108)+e(101)=530
strarr_push(&arr, "banana"); // b(98)+a(97)*3+n(110)*2=609
strarr_push(&arr, "abc"); // 哈希294
strarr_push(&arr, "acb"); // 哈希294(验证次排序条件)
// 执行快速排序(修改指针数组的排列顺序)
qsort(arr.data, arr.size, // 排序数组起始地址和元素个数
sizeof(char*), // 每个元素的大小(指针大小)
compare); // 使用自定义比较函数
// 输出排序结果(验证排序规则)
printf("Sorted results:\n");
for (size_t i = 0; i < arr.size; i++) {
// 打印字符串及其哈希值
printf("[%zu] %s (hash=%d)\n",
i, arr.data[i], compute_hash(arr.data[i]));
}
// 释放动态数组内存(程序退出前清理资源)
strarr_free(&arr);
return 0;
}输出结果:
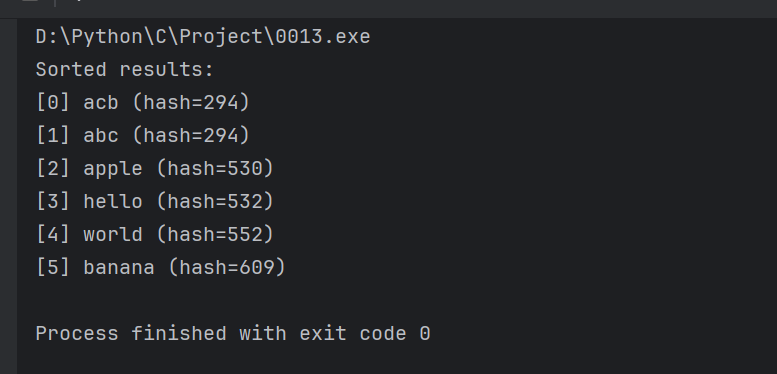
| 维度 | 斐波那契质数过滤 | 多条件字符串排序 |
|---|---|---|
| 核心算法 | 递归生成、质数筛法、二分查找 | 哈希计算、多条件比较、动态扩容 |
| 时间复杂度 | O(2^n)(递归生成) + O(n√n)(质数筛选) | O(n log n)(排序) + O(n)(哈希计算) |
| 空间复杂度 | O(n)(斐波那契存储) + O(k)(质数数组) | O(n)(指针数组) + O(m)(字符串存储) |
| 内存管理 | 动态数组扩容(需手动realloc) | 动态指针数组扩容(高效内存复用) |
| 关键数据结构 | 动态整型数组、质数表 | 指针数组、字符串哈希表 |
| 函数设计特点 | 递归函数、指针参数传递 | 函数指针、多条件比较逻辑 |
| 性能瓶颈 | 递归深度限制、质数判定效率 | 哈希冲突处理、动态扩容频率 |
| 应用场景 | 数学计算密集型任务 | 数据处理与排序密集型任务 |
三、总结
-
算法目标差异:
- 斐波那契题目聚焦数学逻辑(递归、质数筛选)和动态内存管理,强调算法正确性优化(如质数判定)。
- 字符串排序题目注重多条件数据处理和高效内存操作,需灵活运用函数指针与动态结构
-
实现策略对比:
- 斐波那契需权衡递归效率与内存消耗,而字符串排序依赖哈希计算和排序算法稳定性。
- 动态扩容在两者中均为关键,但字符串题目更依赖指针数组的灵活性



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











