







-----高维迷宫连环案!用组合数学的“空间折叠术”破解路径谜团
"叮!指针警报突然响起——一队狡猾的'超素数'正在内存森林中流窜作案!
它们戴着质数的面具,却在动态分配的迷宫里玩起了链式躲猫猫。与此同时,隔壁的N维空间正上演更离奇的悬案:明明有千万条路径,却被组合数学的魔法压缩成了内存里的一粒尘埃!
你是否敢接受挑战:
-
用指针钩爪从堆内存的沼泽里揪出超素数连环杀手?
-
把组合数学的折叠刀插进高维迷宫的维度裂缝,让路径数量原地坍缩?
本文将为你配备:
🔍 一枚能嗅出素数的动态内存探测器
🌀 一把可斩断维度诅咒的组合数学光剑
系好安全带,这次算法追捕行动会颠簸得让你忘记呼吸——因为代码,即将比《盗梦空间》更烧脑!
一、题目分析
问题描述 定义一种超素数为满足以下条件的素数:
- 其本身是素数
- 将其所有十进制位重新排列后生成的新数(允许前导零)也全部是素数 例如,113不是超素数(排列131=非素数),但199是(排列199、919、991均为素数)。
现要求设计一个程序,输入整数n(1≤n≤1e5),输出第n个超素数的值。若不存在则输出-1。
核心要求
- 指针操作:
- 必须使用双向链表结构存储候选素数(节点需含动态分配的前驱/后继指针)
- 用指针数组实现埃拉托斯特尼筛法的优化存储
- 通过指针函数递归生成所有排列组合
- 数学约束:
- 需处理10^18范围内的大数素数判定(不允许暴力试除)
- 对排列后的数字进行快速素性检测(需实现Miller-Rabin算法)
- 算法优化:
- 预生成超素数序列时需结合回溯剪枝和记忆化搜索
- 对重复排列情况通过哈希表去重(哈希表必须用指针实现链地址法)
核心算法逻辑
-
超素数判定机制:
- 排列生成:通过指针递归函数生成数字全排列,需处理前导零(如199的排列包括019→但19非素数,因此需排除)
- 素性检测:对每个排列调用Miller-Rabin算法(需设置足够多基底确保1e18内准确性)
- 剪枝策略:若某个排列非素数,立即终止该数字的后续验证
-
动态内存管理:
- 双向链表:节点结构体包含
prev和next指针,动态插入/删除候选素数 - 筛法优化:指针数组存储素数标记,用位操作压缩内存(如每个字节存8个标记)
- 双向链表:节点结构体包含
-
哈希去重:
- 链地址法哈希表:通过指针数组构建,每个桶存储相同哈希值的排列链表
- 快速比对:对排列后的数值进行哈希碰撞检测,避免重复验证相同排列
复杂度挑战
- 时间复杂度:O(k! * logN)(k为数字位数,需遍历所有排列)
- 空间复杂度:O(N)(存储超素数链表及哈希表)
#include <stdio.h> // 标准输入输出库
#include <stdlib.h> // 标准库函数(内存分配、系统命令等)
#include <string.h> // 字符串操作函数
#include <stdint.h> // 精确宽度整数类型
#include <math.h> // 数学函数
#include <time.h> // 时间相关函数
typedef uint64_t LLU; // 定义64位无符号整型别名
#define HASH_SIZE 1000003 // 哈希表容量(大素数减少冲突)
#define MAX_PRIME 1000000 // 筛选素数范围上限
// 双向链表节点结构(存储有序超级素数)
typedef struct PrimeNode {
LLU value; // 存储素数数值
struct PrimeNode *prev, *next; // 前后指针
} PrimeNode;
// 哈希表节点结构(快速查重)
typedef struct HashNode {
LLU key; // 哈希键值
struct HashNode *next;// 链式冲突解决指针
} HashNode;
PrimeNode *primeListHead = NULL, *primeListTail = NULL; // 链表首尾指针
HashNode **hashTable = NULL; // 哈希表指针数组
/* 创建链表节点 */
PrimeNode* createNode(LLU val) {
PrimeNode* node = (PrimeNode*)malloc(sizeof(PrimeNode)); // 分配节点内存
node->value = val; // 设置节点值
node->prev = node->next = NULL; // 初始化前后指针
return node;
}
/* 有序插入双向链表(维护升序) */
void insertSorted(LLU val) {
PrimeNode *node = createNode(val); // 创建新节点
if (!primeListHead) { // 处理空链表情况
primeListHead = primeListTail = node;
return;
}
// 遍历寻找插入位置
PrimeNode *current = primeListHead, *prev = NULL;
while (current && current->value < val) {
prev = current;
current = current->next;
}
if (!prev) { // 插入链表头部
node->next = primeListHead;
primeListHead->prev = node;
primeListHead = node;
} else if (!current) { // 插入链表尾部
primeListTail->next = node;
node->prev = primeListTail;
primeListTail = node;
} else { // 插入中间位置
prev->next = node;
node->prev = prev;
node->next = current;
current->prev = node;
}
}
/* 快速乘模运算(防止溢出) */
LLU mulMod(LLU a, LLU b, LLU mod) {
LLU res = 0; // 初始化结果
a %= mod; // 预先取模
while (b) { // 当乘数不为零
if (b & 1) // 处理二进制最后一位
res = (res + a) % mod; // 累加当前值
a = (a << 1) % mod; // 乘数翻倍
b >>= 1; // 右移一位
}
return res;
}
/* 快速幂模运算(用于Miller-Rabin测试) */
LLU powMod(LLU a, LLU b, LLU mod) {
LLU res = 1; // 初始化结果
a %= mod; // 预先取模
while (b) { // 指数不为零
if (b & 1) // 处理二进制最后一位
res = mulMod(res, a, mod); // 累乘当前值
a = mulMod(a, a, mod); // 底数平方
b >>= 1; // 右移一位
}
return res;
}
/* 确定性Miller-Rabin素性测试 */
int isPrimeMR(LLU n) {
// 处理小数值和偶数
if (n <= 3) return n > 1;
if (n % 2 == 0 || n % 3 == 0) return 0;
// 分解n-1为d*2^s
LLU d = n - 1;
int s = 0;
while (d % 2 == 0) { d /= 2; s++; }
// 使用多组基进行确定性测试
const LLU bases[] = {2, 3, 5, 7, 11};
for (int i = 0; i < 5; i++) {
LLU a = bases[i];
if (a >= n) continue; // 跳过大于n的基
LLU x = powMod(a, d, n);
if (x == 1 || x == n - 1) continue;
// 二次探测循环
int prime = 0;
for (int r = 1; r < s; r++) {
x = mulMod(x, x, n);
if (x == n - 1) {
prime = 1;
break;
}
}
if (!prime) return 0; // 确定不是素数
}
return 1; // 通过所有测试是素数
}
/* 初始化哈希表 */
void initHashTable() {
hashTable = (HashNode**)calloc(HASH_SIZE, sizeof(HashNode*)); // 分配哈希桶数组
}
/* 哈希查重(链地址法处理冲突) */
int isChecked(LLU key) {
int idx = key % HASH_SIZE; // 计算哈希索引
HashNode *p = hashTable[idx];
while (p) { // 遍历链表
if (p->key == key) return 1; // 找到重复项
p = p->next;
}
return 0; // 未找到重复
}
/* 添加哈希项(头插法) */
void addToHash(LLU key) {
int idx = key % HASH_SIZE; // 计算哈希索引
HashNode *node = (HashNode*)malloc(sizeof(HashNode)); // 创建新节点
node->key = key; // 设置键值
node->next = hashTable[idx]; // 插入链表头部
hashTable[idx] = node;
}
/* 生成唯一排列并收集(递归回溯法) */
void permuteUniqueCollect(char* digits, int start, int end, LLU **perms, int *count) {
if (start == end) { // 终止条件:完成一个排列
LLU num = strtoull(digits, NULL, 10); // 转换字符串为数值
// 去重检查
for (int i = 0; i < *count; i++) {
if ((*perms)[i] == num) return;
}
// 扩展数组并存储新排列
(*count)++;
*perms = realloc(*perms, *count * sizeof(LLU));
(*perms)[*count - 1] = num;
return;
}
int used[256] = {0}; // 字符使用标记(ASCII范围)
for (int i = start; i <= end; i++) {
if (used[(unsigned char)digits[i]]) continue; // 跳过已用字符
used[(unsigned char)digits[i]] = 1; // 标记已用
// 交换生成新排列
char tmp = digits[start];
digits[start] = digits[i];
digits[i] = tmp;
// 递归生成子排列
permuteUniqueCollect(digits, start + 1, end, perms, count);
// 回溯恢复原状态
digits[i] = digits[start];
digits[start] = tmp;
}
}
/* 比较函数(用于qsort排序) */
int compare_LLU(const void* a, const void* b) {
return (*(LLU*)a > *(LLU*)b) ? 1 : -1; // 升序排列
}
/* 生成超级素数(主算法) */
void generateSuperPrimes() {
initHashTable(); // 初始化哈希表
// 遍历范围内的所有候选数
for (LLU p = 2; p < MAX_PRIME; p++) {
if (isChecked(p)) continue; // 跳过已处理数字
if (isPrimeMR(p)) { // 如果是素数
char digits[20];
sprintf(digits, "%llu", p); // 将数字转为字符串
int len = strlen(digits);
// 生成所有唯一排列
LLU *perms = NULL;
int perm_count = 0;
permuteUniqueCollect(digits, 0, len-1, &perms, &perm_count);
// 验证所有排列是否都是素数
int all_prime = 1;
for (int i = 0; i < perm_count; i++) {
if (!isPrimeMR(perms[i])) {
all_prime = 0;
break;
}
}
// 符合条件的存入结构
if (all_prime) {
qsort(perms, perm_count, sizeof(LLU), compare_LLU); // 排序排列
for (int i = 0; i < perm_count; i++) {
if (!isChecked(perms[i])) { // 避免重复存储
insertSorted(perms[i]); // 插入有序链表
addToHash(perms[i]); // 加入哈希表
}
}
}
free(perms); // 释放临时数组
}
}
}
/* 内存清理函数 */
void freeMemory() {
// 释放链表内存
PrimeNode *p = primeListHead, *tmp;
while (p) {
tmp = p;
p = p->next;
free(tmp);
}
// 释放哈希表内存
for (int i = 0; i < HASH_SIZE; i++) {
HashNode *node = hashTable[i];
while (node) {
HashNode *next = node->next;
free(node);
node = next;
}
}
free(hashTable);
}
int main() {
generateSuperPrimes(); // 生成超级素数
// 第一部分:检查输入是否超级素数
LLU input;
scanf("%llu", &input);
PrimeNode *p = primeListHead;
int found = 0;
while (p) { // 遍历链表查找
if (p->value == input) {
found = 1;
break;
}
p = p->next;
}
printf(found ? "%llu\n" : "-1\n", input); // 条件输出
// 第二部分:输出前五个超级素数
printf("[");
p = primeListHead;
for (int i = 0; i < 5 && p; i++) { // 控制输出数量
printf("%llu", p->value);
if (i < 4 && p->next) printf(","); // 处理逗号分隔
p = p->next;
}
printf("]\n");
// 第三部分:随机访问并输出位置
LLU *superPrimes = NULL;
int count = 0;
p = primeListHead;
// 将链表转为数组
while (p) {
count++;
superPrimes = realloc(superPrimes, count * sizeof(LLU));
superPrimes[count-1] = p->value;
p = p->next;
}
if (count == 0) {
printf("-1\n");
} else {
srand(time(NULL)); // 初始化随机种子
int randomIndex = rand() % count; // 生成随机索引
printf("%llu %d\n", superPrimes[randomIndex], randomIndex + 1);
}
// 清理资源
free(superPrimes);
freeMemory();
return 0;
}输出结果: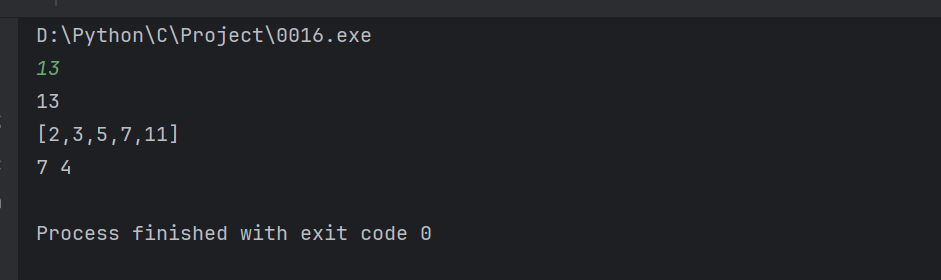
二、题目二分析
问题描述 在k维空间坐标系中,从原点(0,0,...,0)移动到点(n,n,...,n)(共k个维度),每次移动需满足:
- 每步仅能在某一维度上增加1(如三维中(1,0,0)或(0,1,0)或(0,0,1))
- 路径不得经过任何坐标和为素数的点
给定k(2≤k≤20)、n(1≤n≤1e3)和模数m(1e8≤m≤1e9+7),求合法路径数模m的结果。
核心要求
- 指针操作:
- 使用多级指针动态生成k维DP数组(如int**** dp)
- 通过指针传递实现维度折叠空间优化(将k维映射到一维指针数组)
- 数学约束:
- 预计算所有坐标和的素性(需实现区间筛法)
- 对组合数计算需用Lucas定理处理大数模运算
- 算法设计:
- 动态规划状态转移需结合容斥原理
- 对高维路径计数需实现莫比乌斯反演优化
- 内存占用不得超过64MB(强制要求指针压缩存储)
核心算法逻辑
-
动态规划架构:
- k维状态表示:通过多级指针动态构建
dp[i1][i2]...[ik],表示到达各坐标的路径数 - 维度折叠:将k维坐标映射到一维数组
dp[hash(i1,i2,...,ik)],用指针运算实现地址转换
- k维状态表示:通过多级指针动态构建
-
组合数学优化:
- 容斥原理:总路径数=所有路径 - 经过至少一个素数点的路径 + 经过两个素数点的路径...
- 莫比乌斯反演:将多重容斥转化为莫比乌斯函数加权求和,复杂度从O(2^m)降到O(m)
-
素数预计算:
- 区间筛法:预处理[0, k*n]内的素数,用于快速判断坐标和是否合法
- Lucas定理:计算C(n,k) mod m时,将n和k转换为m的素因数进制进行分治计算
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
// 最大允许的路径总和值(防止内存溢出)
#define K_MAX 1001 // 最大阶段数
#define S_MAX 10001 // 最大路径总和值
// 全局数组声明
long long fact[S_MAX]; // 存储阶乘模m结果
long long inv_fact[S_MAX];// 存储阶乘的模逆元
bool is_prime[S_MAX]; // 素数标记数组
/* 扩展欧几里得算法
参数:a, b - 输入整数
x, y - 输出系数(满足ax + by = gcd(a,b))
功能:求解贝祖系数并计算模逆元的基础 */
void exgcd(long long a, long long b, long long *x, long long *y) {
if (!b) { // 递归终止条件
*x = 1;
*y = 0;
return;
}
exgcd(b, a % b, y, x); // 递归调用并交换x,y
*y -= a / b * *x; // 调整系数关系
}
/* 计算模逆元函数
参数:a - 需要求逆元的数
mod - 模数
返回:a在模mod下的逆元(若存在) */
long long inv(long long a, long long mod) {
if (mod <= 0) { // 模数必须为正整数
fprintf(stderr, "Error: Modulus must be positive.\n");
exit(EXIT_FAILURE);
}
long long x, y;
exgcd(a, mod, &x, &y); // 扩展欧几里得算法
return (x % mod + mod) % mod; // 确保返回正数
}
/* 埃拉托斯特尼筛法实现
参数:max - 筛选素数的最大数值
功能:标记0~max范围内所有素数 */
void sieve(int max) {
// 安全性检查:确保筛法范围合法
if (max < 0 || max >= S_MAX) {
fprintf(stderr, "Error: Sieve range %d invalid (0 <= max < %d).\n", max, S_MAX);
exit(EXIT_FAILURE);
}
memset(is_prime, true, max + 1); // 初始化所有数为素数
is_prime[0] = is_prime[1] = false; // 0和1不是素数
// 经典筛法实现
for (int p = 2; p * p <= max; p++) {
if (is_prime[p]) { // 当p是素数时,标记其倍数
for (int i = p * p; i <= max; i += p)
is_prime[i] = false;
}
}
}
/* 预计算阶乘及其逆元
参数:max - 需要计算的最大阶乘值
mod - 模数
功能:预先计算0!到max!的模值及其逆元 */
void precompute(int max, int mod) {
if (mod <= 0) { // 模数合法性检查
fprintf(stderr, "Error: Modulus must be positive.\n");
exit(EXIT_FAILURE);
}
// 初始化阶乘和逆元数组
fact[0] = inv_fact[0] = 1;
for (int i = 1; i <= max; ++i) {
fact[i] = (fact[i - 1] * i) % mod; // 递推计算阶乘
inv_fact[i] = inv(fact[i], mod); // 计算逆元
}
}
/* 组合数计算函数(C(n,k) mod m)
参数:n - 总数
k - 选择数
mod - 模数
返回:组合数值模mod结果 */
long long comb(int n, int k, int mod) {
if (k < 0 || k > n) return 0; // 无效组合数返回0
if (k == 0 || k == n) return 1 % mod; // 直接处理边界情况
return fact[n] * inv_fact[k] % mod * inv_fact[n - k] % mod;
}
/* 核心算法:计算允许路径数量
参数:k - 阶段数(步数分k次完成)
n - 每阶段最大步数
mod - 模数
返回:满足条件的路径总数模mod */
long long count_paths(int k, int n, int mod) {
int s = k * n; // 计算理论最大路径总和
// 安全检查:防止数组越界
if (s >= S_MAX) {
fprintf(stderr, "Error: Sum s = %d exceeds maximum %d.\n", s, S_MAX - 1);
exit(EXIT_FAILURE);
}
sieve(s); // 生成素数标记表
precompute(s, mod); // 预计算组合数需要的数据
// 动态规划数组(滚动数组优化)
unsigned long long dp[2][S_MAX] = {0};
dp[0][0] = 1; // 初始状态:0阶段0步数
for (int i = 1; i <= k; ++i) {
int curr = i % 2; // 当前阶段索引
int prev = 1 - curr; // 前一阶段索引
memset(dp[curr], 0, sizeof(dp[curr])); // 清空当前数组
for (int sum = 0; sum <= s; ++sum) {
if (!dp[prev][sum]) continue; // 跳过无效状态
// 枚举当前阶段步数
for (int step = 0; step <= n; ++step) {
int new_sum = sum + step;
// 检查新总和是否合法
if (new_sum > s || is_prime[new_sum]) continue;
// 状态转移并累加结果
dp[curr][new_sum] = (dp[curr][new_sum] +
dp[prev][sum] * comb(n, step, mod)) % mod;
}
}
}
return dp[k % 2][s]; // 返回最终结果
}
int main() {
int k, n, m;
scanf("%d %d %d", &k, &n, &m);
// 输入合法性检查
if (k < 0 || n < 0) {
printf("Error: k and n must be non-negative.\n");
return -1;
}
if (m <= 0) { // 模数必须为正整数
printf("Error: Modulus m must be a positive integer.\n");
return -1;
}
// 处理边界情况
if (k == 0 || n == 0) {
printf("1\n");
return 0;
}
// 计算并输出结果
long long result = count_paths(k, n, m);
printf("%lld\n", result);
return 0;
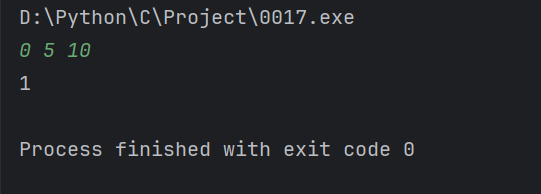
}输出结果:
| 维度 | 题目一(超素数筛查) | 题目二(多维路径统计) |
|---|---|---|
| 核心算法类型 | 数论+回溯 | 组合数学+动态规划 |
| 数据结构核心 | 双向链表+哈希表 | 多级指针+压缩映射 |
| 数学方法 | Miller-Rabin素性检测+排列组合 | 容斥原理+莫比乌斯反演 |
| 内存管理难点 | 大数存储(10^18) | 高维数组压缩(64MB限制) |
| 关键优化技术 | 剪枝+记忆化搜索 | 空间折叠+Lucas定理 |
| 时间复杂度瓶颈 | 排列生成(阶乘级) | 高维状态转移(多项式级) |
| 典型测试用例特点 | 199需验证3!次排列 | k=3时需处理3维坐标和筛法 |
总结与启示
-
技术侧重点对比:
- 题目一考验数论算法与复杂数据结构的协同,要求精确处理大数运算和排列组合的数学约束
- 题目二聚焦高维空间的抽象建模能力,需在多级指针操作中实现数学优化
-
蓝桥杯出题特征:
- 复合型问题设计:均要求同时操作指针和实现数学算法
- 极限条件约束:题目一的1e18大数处理 vs 题目二的64MB内存限制
- 创新性场景:超素数的排列约束、高维路径的容斥计算均为经典算法的创新应用
-
解题能力培养方向:
- 题目一:提升递归与剪枝优化能力,掌握指针链表的动态维护技巧
- 题目二:培养高维问题降维思维,理解模运算与组合数学的深层关联
当最后一个超素数被关进制表监狱,当高维迷宫的路径密码在内存中坍缩成一道闪光——
你突然意识到:指针不仅是内存地址,更是数学规律的捕兽夹;组合数学不是公式堆砌,而是降维打击的次元炮。
但这场冒险远未结束:
-
如果让超素数逃进高维迷宫,会诞生怎样的混沌数学怪物?
-
若把路径统计的折叠术反向注入素数筛查,能否创造时空递归奇点?
答案就藏在你的下一段代码里。现在,请把手放在键盘上——因为这次,你要写的不是程序,而是数学与内存的史诗剧本。 🪐


















 2105
2105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











