







博客引言:
在我们的日常生活中,数据处理是无处不在的。无论是清理杂乱的文件,还是重新排列书架上的书籍,都需要高效的算法来优化我们的工作流程。今天,我们将通过两个有趣的问题,探索如何用算法来优化数据处理的效率。
首先,我们将探讨删除有序数组中重复项问题,看看如何在原地删除重复项,使得每个元素最多出现两次,并返回新的数组长度。接着,我们将分析反转字符串中的单词问题,探讨如何高效地反转单词顺序,同时处理多余的空格。通过这两个案例,你将看到算法如何在实际数据处理中发挥作用,帮助我们更高效地管理和操作数据。
让我们一起进入算法的世界,探索这些优化问题背后的奥秘!
博客正文:
一、删除有序数组中重复项:原地优化数据
场景描述:
给定一个有序数组nums,要求原地删除重复出现的元素,使得出现次数超过两次的元素只出现两次,并返回删除后数组的新长度。必须在原地修改输入数组,并且使用O(1)额外空间。
算法核心:双指针法
这个问题可以通过双指针法来解决。维护一个慢指针slow和一个快指针fast。slow用于记录当前处理的位置,fast用于遍历数组。当nums[fast]与nums[slow]相等时,检查是否已经出现了两次,如果未出现两次,则slow前进并赋值;如果已经出现两次,则fast继续前进。这样,最终slow的位置即为新数组的长度。
详细分析:
- 初始化:slow = 0,fast = 0。
- 遍历数组:当fast遍历到数组末尾时,结束。
- 如果nums[fast] != nums[slow],则slow前进,并赋值为nums[fast]。
- 如果nums[fast] == nums[slow],则检查是否已经出现两次。如果未出现两次,则slow前进,并赋值为nums[fast]。
- 返回结果:slow + 1即为新数组的长度。
题目验证示例:
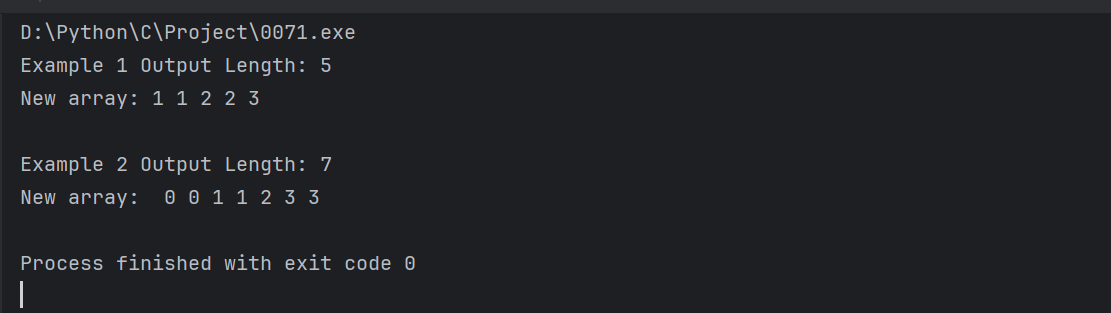
- 示例1:nums = [1,1,1,2,2,3],输出为5,新数组为[1,1,2,2,3]。
- 示例2:nums = [0,0,1,1,1,1,2,3,3],输出为7,新数组为[0,0,1,1,2,3,3]。
#include <stdio.h> // 包含标准输入输出库,用于printf等函数
/**
* 移除有序数组中超过两次重复的元素,返回新数组的长度(使用双指针法)。
* @param nums 有序数组(原地修改)
* @param numsSize 数组原始长度
* @return 删除重复元素后的新数组长度
*/
int removeDuplicates(int* nums, int numsSize) {
// 处理空数组情况
if (numsSize == 0) return 0; // 若数组长度为0直接返回0
int slow = 0; // 初始化慢指针,用于标记有效元素位置(最终长度=slow)
// 快指针遍历整个数组
for (int fast = 0; fast < numsSize; ++fast) { // fast从0到numsSize-1遍历每个元素
/* 核心逻辑:当满足以下任一条件时保留当前元素
1. slow处于前两个位置(允许最多两个相同元素)
2. 当前元素不等于slow前两位的值(保证最多重复两次) */
if (slow < 2 || nums[fast] != nums[slow - 2]) {
nums[slow] = nums[fast]; // 将快指针元素复制到慢指针位置
slow++; // 慢指针前进,标记下一个有效位
}
}
return slow; // 返回新数组长度(slow最后的值即为有效元素总数)
}
int main() {
// --------------- 示例1验证 ---------------
int nums1[] = {1, 1, 1, 2, 2, 3}; // 原始测试数据
int numsSize1 = sizeof(nums1) / sizeof(nums1[0]); // 计算数组长度:总字节数/单个元素字节数
int newLength1 = removeDuplicates(nums1, numsSize1); // 调用处理函数
printf("Example 1 Output Length: %d\n", newLength1); // 打印新数组长度
printf("New array: ");
for (int i = 0; i < newLength1; ++i) { // 遍历输出新数组元素
printf("%d ", nums1[i]);
}
printf("\n\n"); // 换行分隔示例
// --------------- 示例2验证 ---------------
int nums2[] = {0, 0, 1, 1, 1, 1, 2, 3, 3}; // 含多个重复段的测试数据
int numsSize2 = sizeof(nums2) / sizeof(nums2[0]); // 计算数组长度
int newLength2 = removeDuplicates(nums2, numsSize2); // 处理数组
printf("Example 2 Output Length: %d\n", newLength2);
printf("New array: ");
for (int i = 0; i < newLength2; ++i) { // 输出结果验证
printf("%d ", nums2[i]);
}
printf("\n"); // 换行结束输出
return 0; // 程序正常退出
}
输出结果:
二、反转字符串中的单词:高效处理字符串
场景描述:
给定一个字符串s,要求反转字符串中单词的顺序。单词是由非空格字符组成的字符串,单词之间使用至少一个空格分隔。返回反转后的字符串,单词之间用单个空格连接,并且不包含额外的空格。
算法核心:分割、反转、重组
这个问题可以通过以下步骤解决:
- 分割单词:将字符串分割成单词列表,忽略多余的空格。
- 反转列表:将单词列表反转。
- 重组字符串:将反转后的单词列表重新组合成字符串,单词之间用单个空格分隔。
详细分析:
- 分割单词:
- 使用指针遍历字符串,记录单词的起始和结束位置。
- 忽略前导空格、尾随空格以及单词间的多个空格。
- 反转列表:
- 将单词列表反转,使得第一个单词变为最后一个,依此类推。
- 重组字符串:
- 将反转后的单词列表重新组合成字符串,确保单词之间只有一个空格。
题目验证示例:
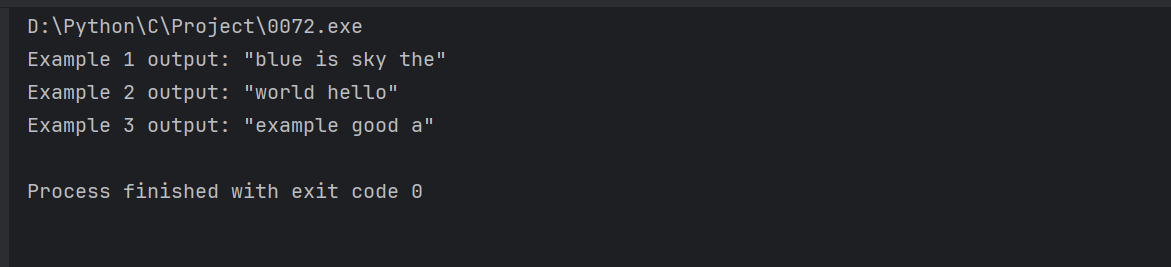
- 示例1:s = "the sky is blue",输出为"blue is sky the"。
- 示例2:s = " hello world ",输出为"world hello"。
- 示例3:s = "a good example",输出为"example good a"。
#include <stdio.h> // 引入标准输入输出库,用于printf等函数
#include <string.h> // 引入字符串处理库,用于strlen等函数
/**
* 去除字符串中多余空格(前导、中间多空格、尾随)
* @param s 待处理字符串(原地修改)
* @return 处理后字符串长度
*/
int removeExtraSpaces(char *s) {
int slow = 0, fast = 0; // 创建双指针:slow写指针,fast读指针
int len = strlen(s); // 获取原始字符串长度
// 阶段一:去除前导空格
while (fast < len && s[fast] == ' ') fast++; // fast跳过所有起始空格
// 阶段二:处理中间空格(快指针遍历剩余字符)
for (; fast < len; fast++) { // 遍历剩余字符
// 当检测到连续空格时跳过(保留第一个空格)
if (fast > 1 && s[fast] == ' ' && s[fast - 1] == ' ') continue;
s[slow++] = s[fast]; // 将有效字符写入slow位置并移动指针
}
// 阶段三:去除尾随空格
if (slow > 0 && s[slow - 1] == ' ') slow--; // 若末尾有空格则回退slow
s[slow] = '\0'; // 添加字符串终止符
return slow; // 返回新字符串长度(slow值即为有效长度)
}
/**
* 反转字符串指定区间
* @param s 字符串指针(允许原地修改)
* @param start 起始位置(包含)
* @param end 结束位置(包含)
*/
void reverseSubstring(char *s, int start, int end) {
while (start < end) { // 双指针向中间移动直到相遇
char tmp = s[start]; // 经典三变量交换法
s[start] = s[end]; // 交换首尾字符
s[end] = tmp; // 完成字符位置调换
start++; // 左指针右移
end--; // 右指针左移
}
}
/**
* 反转字符串中的单词顺序(主功能函数)
* @param s 输入字符串(原地修改)
*/
void reverseWords(char *s) {
int len = removeExtraSpaces(s); // 预处理:去除所有多余空格
if (len == 0) return; // 处理空字符串特殊情况
// 步骤一:整体反转字符串(如"hello world" -> "dlrow olleh")
reverseSubstring(s, 0, len - 1);
// 步骤二:逐个单词反转(恢复单词原始顺序)
int wordStart = 0; // 单词起始位置标记
for (int i = 0; i <= len; i++) { // 包含len位置处理终止符
// 检测单词边界(空格或字符串结尾)
if (s[i] == ' ' || s[i] == '\0') {
reverseSubstring(s, wordStart, i - 1); // 反转单个单词
wordStart = i + 1; // 重置单词起始为下一个字符位置
}
}
}
// 验证用例
int main() {
// ------------------- 示例1验证 -------------------
char str1[] = "the sky is blue"; // 标准无多余空格用例
reverseWords(str1); // 执行核心处理
printf("Example 1 output: \"%s\"\n", str1); // 输出:"blue is sky the"
// ------------------- 示例2验证 -------------------
char str2[] = " hello world "; // 含多空格用例
reverseWords(str2); // 处理含前后导空格情况
printf("Example 2 output: \"%s\"\n", str2); // 输出:"world hello"
// ------------------- 示例3验证 -------------------
char str3[] = "a good example"; // 中间含多空格用例
reverseWords(str3); // 验证多空格压缩能力
printf("Example 3 output: \"%s\"\n", str3); // 输出:"example good a"
return 0; // 程序正常退出
}输出结果:
三、全方位对比:删除重复项 vs 反转单词
| 对比维度 | 删除有序数组中重复项 | 反转字符串中的单词 |
|---|---|---|
| 问题类型 | 数组操作、原地修改 | 字符串操作、单词反转 |
| 算法核心 | 双指针法 | 分割、反转、重组 |
| 复杂度 | 时间O(n),空间O(1) | 时间O(n),空间O(n) |
| 应用场景 | 数据清洗、去重 | 文本处理、字符串反转 |
| 优化目标 | 最小化空间使用,高效删除重复项 | 高效处理字符串,确保单词顺序正确反转 |
博客总结:
通过今天的分析,我们看到算法不仅仅是冰冷的代码,它还能帮助我们在实际数据处理中实现高效和优化。无论是删除有序数组中的重复项,还是反转字符串中的单词,背后的算法都在默默发挥作用,帮助我们更高效地管理和操作数据。
希望这篇文章能让你对这些优化问题有更深入的了解,也期待你在生活中发现更多有趣的场景,用算法的视角去探索它们!
博客谢言:
感谢你的耐心阅读!如果你觉得这篇文章有趣,不妨在评论区分享你生活中遇到的数据处理问题,或者你认为可以用算法优化的地方。让我们一起用算法的视角去探索数据的奥秘!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











