







Python中的机器学习:从线性回归到随机森林的实现
机器学习是现代科技的核心驱动力之一,它通过让计算机从数据中学习,从而实现自主决策和预测。在Python中,机器学习的实现不仅高效,而且极其灵活,从简单的线性回归到复杂的随机森林,都能轻松应对。本文将通过一个引人入胜的故事,带领你一步步掌握从线性回归到随机森林的实现,帮助你理解机器学习的精髓。
一、机器学习的入门:从数据到模型
1. 什么是机器学习?
机器学习是一种通过数据让计算机自动学习和改进的技术。它广泛应用于各个领域,如图像识别、自然语言处理、推荐系统等。
2. 监督学习与无监督学习
监督学习(Supervised Learning)是通过已知的数据标签来训练模型,使其能够对新的数据进行预测。无监督学习(Unsupervised Learning)则是从无标签的数据中发现潜在的模式或结构。
示例验证:数据与模型的基本概念
# 导入必要的库
import numpy as np # 导入NumPy库,用于数值计算和数组操作
import matplotlib.pyplot as plt # 导入matplotlib的pyplot模块,用于数据可视化
from sklearn.model_selection import train_test_split # 从scikit-learn导入train_test_split函数,用于数据集划分
from sklearn.linear_model import LinearRegression # 导入线性回归模型类
from sklearn.metrics import mean_squared_error # 导入均方误差计算函数
# 生成示例数据
np.random.seed(42) # 设置随机种子,确保结果可重现
X = np.linspace(0, 10, 100).reshape(-1, 1) # 创建0-10范围内均匀分布的100个点,并转换为列向量
y = 2 * X + np.random.randn(100, 1) # 生成带有随机噪声的线性数据(斜率为2)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, # 特征数据
y, # 目标变量
test_size=0.2, # 测试集占比20%
random_state=42 # 固定随机状态确保每次划分结果相同
)
# 创建线性回归模型
model = LinearRegression() # 实例化线性回归模型对象
model.fit(X_train, y_train) # 在训练集上训练模型
# 进行预测
y_pred = model.predict(X_test) # 使用训练好的模型对测试集进行预测
# 计算均方误差
mse = mean_squared_error(y_test, y_pred) # 计算预测值与真实值的均方误差
print(f"均方误差: {mse:.2f}") # 格式化输出均方误差(保留两位小数)
# 可视化结果
plt.scatter(X_test, y_test, color='blue', label='实际值') # 绘制测试集实际值的散点图(蓝色)
plt.plot(X_test, y_pred, color='red', linewidth=2, label='预测值') # 绘制模型预测值的回归线(红色)
plt.xlabel('X轴') # 设置X轴标签
plt.ylabel('Y轴') # 设置Y轴标签
plt.title('线性回归模型预测结果') # 设置图表标题
plt.legend() # 显示图例
plt.show() # 显示图表问题验证:
- 什么是监督学习和无监督学习?
- 如何使用线性回归模型进行预测?
二、线性回归:机器学习的基础
1. 线性回归的数学原理
线性回归是机器学习中最基础的算法之一,它通过拟合一条直线来预测目标变量。
公式:

2. 损失函数与优化方法
损失函数(Loss Function)用于衡量模型预测值与真实值之间的差异。在线性回归中,常用均方误差(MSE)作为损失函数。
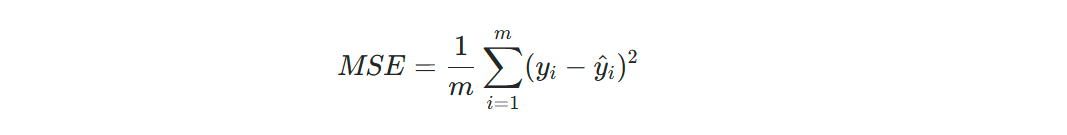
优化方法(如梯度下降)用于最小化损失函数,从而找到最佳的模型参数。
示例验证:线性回归的实现
# 导入NumPy库,用于数值计算和数组操作
import numpy as np
# 导入matplotlib的pyplot模块,用于数据可视化
import matplotlib.pyplot as plt
# 从scikit-learn导入train_test_split函数,用于划分数据集
from sklearn.model_selection import train_test_split
# 导入线性回归模型类
from sklearn.linear_model import LinearRegression
# 导入均方误差计算函数,用于评估模型性能
from sklearn.metrics import mean_squared_error
# 生成示例数据
# 设置随机种子,确保每次运行结果可重现
np.random.seed(42)
# 创建0到10之间的100个等间距点,并转换为列向量形式(100行1列)
X = np.linspace(0, 10, 100).reshape(-1, 1)
# 生成目标变量y:2倍X加上随机噪声(标准正态分布)
y = 2 * X + np.random.randn(100, 1)
# 划分训练集和测试集
# 使用train_test_split函数将数据集划分为训练集和测试集
# X: 特征数据, y: 目标变量, test_size=0.2: 测试集占20%, random_state=42: 固定随机状态确保可重现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
# 实例化一个线性回归模型对象
model = LinearRegression()
# 在训练集上训练模型,学习特征X和目标y之间的关系
model.fit(X_train, y_train)
# 进行预测
# 使用训练好的模型对测试集特征X_test进行预测
y_pred = model.predict(X_test)
# 计算均方误差
# 计算预测值y_pred与实际值y_test之间的均方误差
mse = mean_squared_error(y_test, y_pred)
# 打印格式化的均方误差结果,保留两位小数
print(f"均方误差: {mse:.2f}")
# 可视化结果
# 绘制测试集实际值的散点图,蓝色点表示实际值
plt.scatter(X_test, y_test, color='blue', label='实际值')
# 绘制模型预测值的回归线,红色线表示预测值,线宽为2
plt.plot(X_test, y_pred, color='red', linewidth=2, label='预测值')
# 设置X轴标签
plt.xlabel('X轴')
# 设置Y轴标签
plt.ylabel('Y轴')
# 设置图表标题
plt.title('线性回归模型预测结果')
# 显示图例
plt.legend()
# 显示图表
plt.show()问题验证:
- 线性回归的数学原理是什么?
- 如何使用
Scikit-learn库实现线性回归模型?
三、决策树:从简单到复杂
1. 决策树的基本概念
决策树是一种基于树结构的分类和回归算法。它通过一系列的判断规则,将数据划分为不同的类别或预测目标变量。
2. 决策树的优势与劣势
决策树易于理解和解释,能够处理非线性关系,但容易过拟合。
示例验证:决策树的实现
# 导入NumPy库,用于数值计算和数组操作
import numpy as np
# 导入matplotlib的pyplot模块,用于数据可视化
import matplotlib.pyplot as plt
# 从scikit-learn导入train_test_split函数,用于划分数据集
from sklearn.model_selection import train_test_split
# 导入决策树回归模型类
from sklearn.tree import DecisionTreeRegressor
# 导入均方误差计算函数,用于评估模型性能
from sklearn.metrics import mean_squared_error
# 生成示例数据
# 设置随机种子,确保每次运行结果可重现
np.random.seed(42)
# 创建0到10之间的100个等间距点,并转换为列向量形式(100行1列)
X = np.linspace(0, 10, 100).reshape(-1, 1)
# 生成目标变量y:正弦函数值加上随机噪声(标准正态分布乘以0.5)
y = np.sin(X) + np.random.randn(100, 1) * 0.5
# 划分训练集和测试集
# 使用train_test_split函数将数据集划分为训练集和测试集
# X: 特征数据, y: 目标变量, test_size=0.2: 测试集占20%, random_state=42: 固定随机状态确保可重现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树回归模型
# 实例化一个决策树回归模型对象,设置最大树深度为3(防止过拟合)
model = DecisionTreeRegressor(max_depth=3)
# 在训练集上训练模型,学习特征X和目标y之间的关系
model.fit(X_train, y_train)
# 进行预测
# 使用训练好的决策树模型对测试集特征X_test进行预测
y_pred = model.predict(X_test)
# 计算均方误差
# 计算预测值y_pred与实际值y_test之间的均方误差
mse = mean_squared_error(y_test, y_pred)
# 打印格式化的均方误差结果,保留两位小数
print(f"均方误差: {mse:.2f}")
# 可视化结果
# 绘制测试集实际值的散点图,蓝色点表示实际值
plt.scatter(X_test, y_test, color='blue', label='实际值')
# 绘制模型预测值的折线图,红色线表示预测值,线宽为2
plt.plot(X_test, y_pred, color='red', linewidth=2, label='预测值')
# 设置X轴标签
plt.xlabel('X轴')
# 设置Y轴标签
plt.ylabel('Y轴')
# 设置图表标题
plt.title('决策树回归模型预测结果')
# 显示图例
plt.legend()
# 显示图表
plt.show()问题验证:
- 什么是决策树?
- 如何使用
Scikit-learn库实现决策树回归模型?
四、随机森林:集成学习的力量
1. 随机森林的基本概念
随机森林是一种集成学习方法,通过组合多个决策树来提高模型的泛化能力和稳定性。
2. 随机森林的优势与劣势
随机森林能够有效减少过拟合,提高模型的准确性和稳定性,但模型的解释性较差。
示例验证:随机森林的实现
# 导入NumPy库,用于数值计算和数组操作
import numpy as np
# 导入matplotlib的pyplot模块,用于数据可视化
import matplotlib.pyplot as plt
# 从scikit-learn导入train_test_split函数,用于划分数据集
from sklearn.model_selection import train_test_split
# 导入决策树回归模型类
from sklearn.tree import DecisionTreeRegressor
# 导入均方误差计算函数,用于评估模型性能
from sklearn.metrics import mean_squared_error
# 生成示例数据
# 设置随机种子,确保每次运行结果可重现
np.random.seed(42)
# 创建0到10之间的100个等间距点,并转换为列向量形式(100行1列)
X = np.linspace(0, 10, 100).reshape(-1, 1)
# 生成目标变量y:正弦函数值加上随机噪声(标准正态分布乘以0.5)
y = np.sin(X) + np.random.randn(100, 1) * 0.5
# 划分训练集和测试集
# 使用train_test_split函数将数据集划分为训练集和测试集
# X: 特征数据, y: 目标变量, test_size=0.2: 测试集占20%, random_state=42: 固定随机状态确保可重现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树回归模型
# 实例化一个决策树回归模型对象,设置最大树深度为3(防止过拟合)
model = DecisionTreeRegressor(max_depth=3)
# 在训练集上训练模型,学习特征X和目标y之间的关系
model.fit(X_train, y_train)
# 进行预测
# 使用训练好的决策树模型对测试集特征X_test进行预测
y_pred = model.predict(X_test)
# 计算均方误差
# 计算预测值y_pred与实际值y_test之间的均方误差
mse = mean_squared_error(y_test, y_pred)
# 打印格式化的均方误差结果,保留两位小数
print(f"均方误差: {mse:.2f}")
# 可视化结果
# 绘制测试集实际值的散点图,蓝色点表示实际值
plt.scatter(X_test, y_test, color='blue', label='实际值')
# 绘制模型预测值的折线图,红色线表示预测值,线宽为2
plt.plot(X_test, y_pred, color='red', linewidth=2, label='预测值')
# 设置X轴标签
plt.xlabel('X轴')
# 设置Y轴标签
plt.ylabel('Y轴')
# 设置图表标题
plt.title('决策树回归模型预测结果')
# 显示图例
plt.legend()
# 显示图表
plt.show()五、案例分析:从线性回归到随机森林
1. 案例背景
假设我们有一个房价数据集,包含房屋的面积和价格。我们的目标是通过机器学习模型来预测房屋价格。
2. 数据预处理
# 导入pandas库,用于数据处理和分析
import pandas as pd
# 导入numpy库,用于数值计算和数组操作
import numpy as np
# 导入matplotlib的pyplot模块,用于数据可视化
import matplotlib.pyplot as plt
# 从scikit-learn导入train_test_split函数,用于划分数据集
from sklearn.model_selection import train_test_split
# 导入StandardScaler类,用于特征标准化
from sklearn.preprocessing import StandardScaler
# 导入LinearRegression类,用于线性回归模型
from sklearn.linear_model import LinearRegression
# 导入DecisionTreeRegressor类,用于决策树回归模型
from sklearn.tree import DecisionTreeRegressor
# 导入RandomForestRegressor类,用于随机森林回归模型
from sklearn.ensemble import RandomForestRegressor
# 导入mean_squared_error函数,用于计算均方误差
from sklearn.metrics import mean_squared_error
# 导入r2_score函数,用于计算决定系数(R²)
from sklearn.metrics import r2_score
# 加载房屋价格数据集
# 使用pandas的read_csv函数读取CSV文件
data = pd.read_csv('house_prices.csv')
# 打印数据集的前5行,用于初步查看数据结构
print(data.head())
# 数据预处理
# 选择特征变量:这里只使用'面积'作为特征(单变量模型)
X = data[['面积']]
# 选择目标变量:房屋'价格'
y = data['价格']
# 划分训练集和测试集
# 使用train_test_split函数将数据集分割为训练集和测试集
# X: 特征数据, y: 目标变量, test_size=0.2: 测试集占比20%, random_state=42: 固定随机种子确保可重现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征缩放(标准化)
# 创建StandardScaler对象,用于数据标准化
scaler = StandardScaler()
# 对训练集进行拟合和转换:计算均值和标准差,并标准化数据
X_train = scaler.fit_transform(X_train)
# 对测试集进行转换:使用训练集计算的均值和标准差进行标准化
X_test = scaler.transform(X_test)3. 模型实现与比较
# 线性回归模型
# 创建线性回归模型实例
linear_model = LinearRegression()
# 在训练集上训练线性回归模型
linear_model.fit(X_train, y_train)
# 使用训练好的线性回归模型对测试集进行预测
y_pred_linear = linear_model.predict(X_test)
# 计算线性回归模型的均方误差
mse_linear = mean_squared_error(y_test, y_pred_linear)
# 计算线性回归模型的决定系数(R²)
r2_linear = r2_score(y_test, y_pred_linear)
# 打印线性回归模型的评估结果
print(f"线性回归 - 均方误差: {mse_linear:.2f}, R²: {r2_linear:.2f}")
# 决策树模型
# 创建决策树回归模型实例,设置最大深度为3防止过拟合
tree_model = DecisionTreeRegressor(max_depth=3)
# 在训练集上训练决策树模型
tree_model.fit(X_train, y_train)
# 使用训练好的决策树模型对测试集进行预测
y_pred_tree = tree_model.predict(X_test)
# 计算决策树模型的均方误差
mse_tree = mean_squared_error(y_test, y_pred_tree)
# 计算决策树模型的决定系数(R²)
r2_tree = r2_score(y_test, y_pred_tree)
# 打印决策树模型的评估结果
print(f"决策树 - 均方误差: {mse_tree:.2f}, R²: {r2_tree:.2f}")
# 随机森林模型
# 创建随机森林回归模型实例
# n_estimators=100: 使用100棵决策树
# max_depth=3: 限制每棵树的最大深度为3
# random_state=42: 固定随机种子确保结果可重现
forest_model = RandomForestRegressor(n_estimators=100, max_depth=3, random_state=42)
# 在训练集上训练随机森林模型
forest_model.fit(X_train, y_train)
# 使用训练好的随机森林模型对测试集进行预测
y_pred_forest = forest_model.predict(X_test)
# 计算随机森林模型的均方误差
mse_forest = mean_squared_error(y_test, y_pred_forest)
# 计算随机森林模型的决定系数(R²)
r2_forest = r2_score(y_test, y_pred_forest)
# 打印随机森林模型的评估结果
print(f"随机森林 - 均方误差: {mse_forest:.2f}, R²: {r2_forest:.2f}")4. 模型评估与选择
# 导入matplotlib的pyplot模块,用于数据可视化
import matplotlib.pyplot as plt
# 创建散点图:绘制测试集实际值
# X_test: 测试集特征数据(房屋面积)
# y_test: 测试集实际价格
# color='blue': 设置散点颜色为蓝色
# label='实际值': 设置图例标签为"实际值"
plt.scatter(X_test, y_test, color='blue', label='实际值')
# 绘制线性回归模型的预测结果线
# X_test: 测试集特征数据
# y_pred_linear: 线性回归模型对测试集的预测价格
# color='red': 设置线条颜色为红色
# linewidth=2: 设置线宽为2
# label='线性回归': 设置图例标签为"线性回归"
plt.plot(X_test, y_pred_linear, color='red', linewidth=2, label='线性回归')
# 绘制决策树模型的预测结果线
# X_test: 测试集特征数据
# y_pred_tree: 决策树模型对测试集的预测价格
# color='green': 设置线条颜色为绿色
# linewidth=2: 设置线宽为2
# label='决策树': 设置图例标签为"决策树"
plt.plot(X_test, y_pred_tree, color='green', linewidth=2, label='决策树')
# 绘制随机森林模型的预测结果线
# X_test: 测试集特征数据
# y_pred_forest: 随机森林模型对测试集的预测价格
# color='purple': 设置线条颜色为紫色
# linewidth=2: 设置线宽为2
# label='随机森林': 设置图例标签为"随机森林"
plt.plot(X_test, y_pred_forest, color='purple', linewidth=2, label='随机森林')
# 设置X轴标签
# xlabel='面积': 标注X轴为"面积"
plt.xlabel('面积')
# 设置Y轴标签
# ylabel='价格': 标注Y轴为"价格"
plt.ylabel('价格')
# 设置图表标题
# title='房价预测模型比较': 设置图表标题为"房价预测模型比较"
plt.title('房价预测模型比较')
# 显示图例
# 根据前面设置的label参数自动生成图例
plt.legend()
# 显示图表
# 将前面设置的所有可视化元素渲染并显示出来
plt.show()问题验证:
- 如何从线性回归到随机森林逐步实现模型?
- 如何选择合适的模型并进行调优?
六、总结与展望
从线性回归到随机森林,我们见证了机器学习的强大与灵活性。线性回归作为基础算法,为我们提供了简单的预测能力;决策树通过树结构增强了模型的表达能力;而随机森林则通过集成学习进一步提升了模型的泛化能力和稳定性。
在实际应用中,建议开发者:
- 根据数据的特点和问题的复杂度选择合适的模型。
- 通过交叉验证和网格搜索等方法进行模型调优。
- 使用
Scikit-learn等优秀的库,简化机器学习的实现过程。
希望这篇博客能够帮助你掌握从线性回归到随机森林的实现,提升你的机器学习能力!如果你有任何问题或建议,欢迎在评论区留言!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











