









什么是哈希表
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
官方的解释可能有点懵,直白来讲其实数组就是一张哈希表。
哈希作为一个非常常用的查找数据结构,它能够在O(1) 的时间复杂度下进行数据查找。
比方说我有一个集合有如下数据,而我想要快速查找一个数据在不在这个集合中,我应该采取什么办法?
一般情况下可以使用遍历的方式,但是如果数据量太多,则每次遍历的代价将不可接受。
那么,如果它们是有序的,则可以使用树形数据结构进行二分查找,效率也是非常的高,但很不巧我们这些数据是无序的。
所以就有人想到一个很巧妙的办法来寻找它,就是将要寻找的数据(下文称为键)进行一次计算得到一个数组下标值,然后将这个值放到对应的数组里。
以后我们每次寻找的时候都对键进行计算从而得到一个数组下标值,然后通过下标拿到数组对应的数据,就能知道它是否存在于这个数组中了。
这种数据查找的数据结构就叫做哈希表,对键的计算的方法叫做哈希函数。
什么是哈希函数
哈希函数可以把给定的数据转换成固定长度的无规律数值。转换后的无规律数值可以作为数据摘要应用于各种各样的场景。
我们可以把哈希函数想象成搅拌机,如下图所示。

将数据放入搅拌机里

经过哈希函数计算后,搅拌机会输出固定长度的无规律数值。输出的无规律数值就是“哈希值”。哈希值虽然是数字,但多用十六进制来表示。

计算机使用二进制管理所有数据,虽然哈希值是用十六进制表示的,但它也是数据,计算机在存储哈希值时,会通过计算将其转换为二进制进行管理。
哈希函数的特征
- 哈希值的长度与输入数据的大小的无关
- 输入相同的数据,输出的哈希值也必定相同
- 输入相似的数据,输出的哈希值必定不同
- 输入的数据完全不同,但输出的哈希值可能是相同的。这种情况被称作“哈希冲突”
- 哈希值是不可逆的,通过哈希值不可能反向推算出原本的数据。
哈希冲突
哈希冲突是指多个不同的键散列到了同一个数组下标位置上,案例如下:
在上图中,耳、朵、不 这三个字经过散列之后的数组下标都是0,而且因为是三个不同的值,所以也不能直接在数组上覆盖,那么我们就需要有一个办法把这三个值存起来。
一般哈希冲突有两种解决方法, 拉链法和开放地址法。
拉链法:就是在冲突的下标元素处维护一个链表,所有冲突的元素都依次放到这个链表上去:
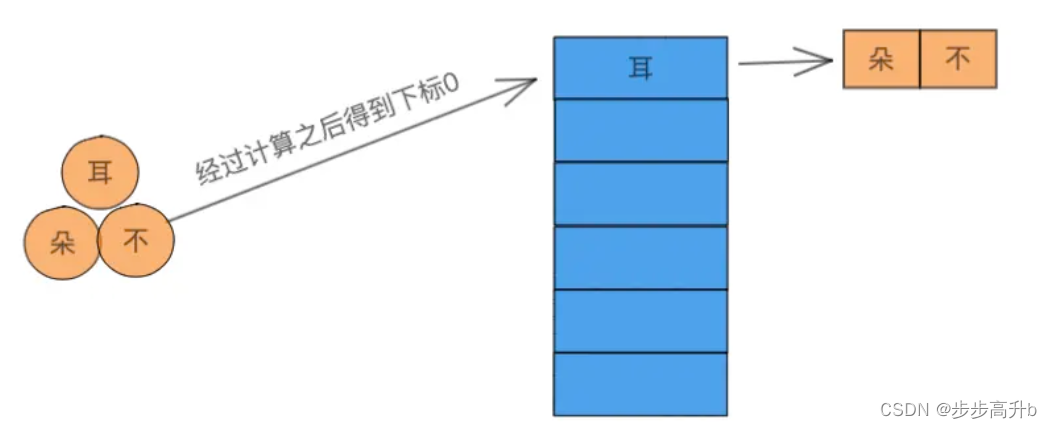
在上图中,将冲突的两个键就按照顺序放在了链表中,下次寻找时只需要查看该数组元素以及遍历这个链表即可。
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
开放地址法:是一种比较简单的解决冲突的方法,它的原理非常简单:
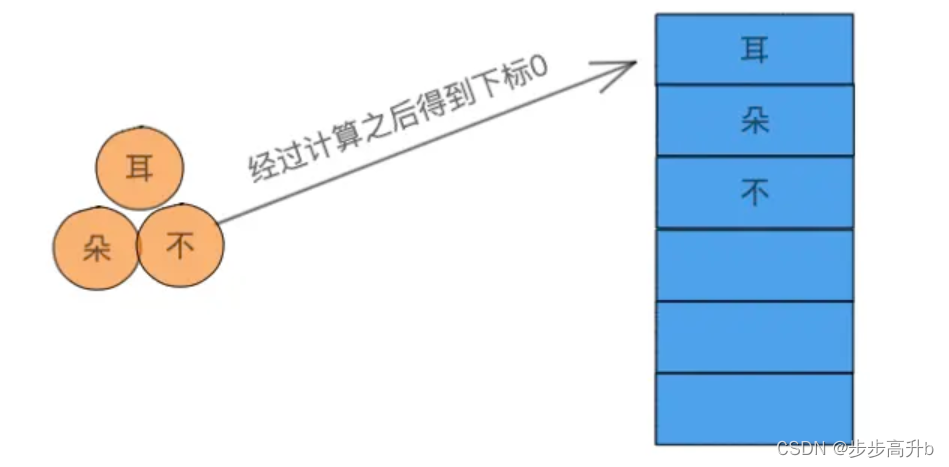
就是在第一个耳字已经占用了下标0之后,第二个朵字则向后进行寻找空余的下标,找到之后将自己设置进去,所以朵字在下标1处,而不字在下标2处。
根据寻找下标的方式不同,开放地址法可以分为以下几种:

其实原理都差不多,都是在当前下标的基础上向后寻找空余的下标,不过步长不一样罢了。
常见的三种哈希结构
- 数组(array)
- 集合(set)
- 映射(map)
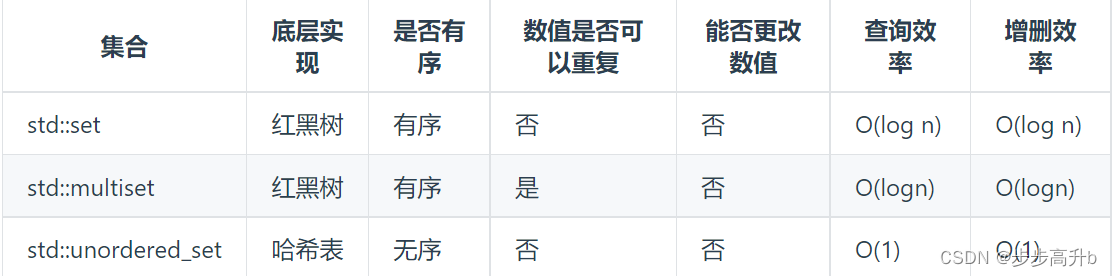
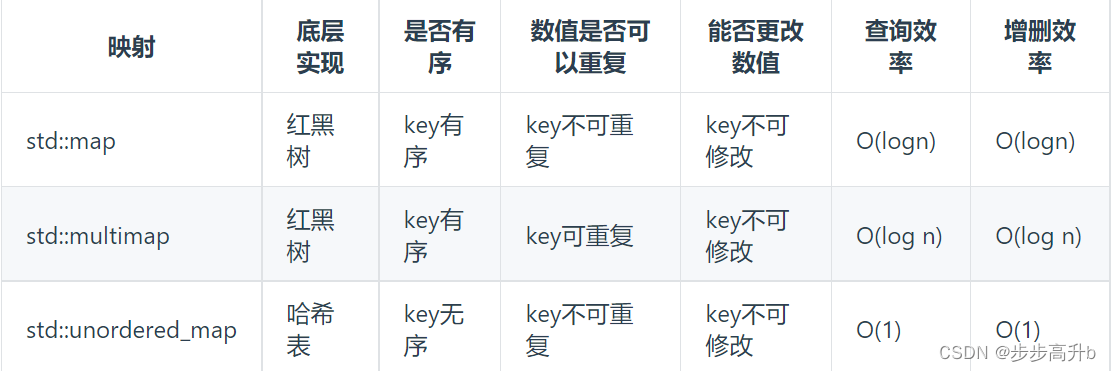
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
哈希表的缺点
1.哈希冲突太多会导致部分查找线性。
2.不能进行范围查找。
对于第一个缺点,一般正常使用是不会出现太多冲突
对于第二个缺点,这是哈希表一个无法回避的硬伤,在需要范围的查找的需求下,还是树类数据结构更能兼顾范围查找与指数级速度。
当然哈希表在记录数据量很大的时候,处理记录的数据很快,平均操作时间是一个不太大的常数。这足以掩盖很多缺点。
















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











