






一个很朴素的想法是:既然市面上存在这么多大模型,秉持着存在即合理的原则,每个模型应该都有其优势。比如说:文心一言的API产品矩阵十分丰富、通义千问API分区以及内容生成更加完善、豆包有算法帝的算法、GPT是传统王者…
那有没有一个现成的产品能兼容所有优点,或者至少能从中选出最适合当前场景的大模型?

github上还有大佬的成熟项目,我也尝试写一个,此博客记录我从零开始编写自己的LLM-Client
- 如果从一个产品的角度思路这个项目,一期要先实现简单的API调用和呈现,二期解决延迟、重试、VPN切换等待性能问题
现阶段效果:
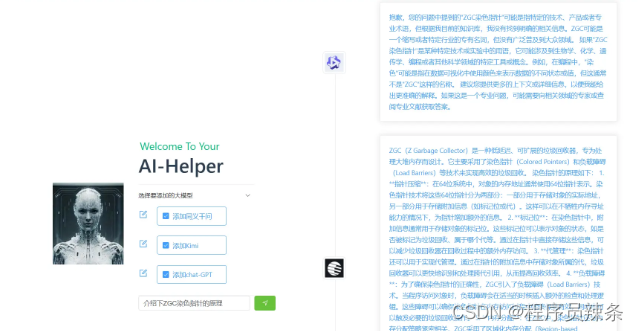
后端实现方式有很多,由于我是Java程序员,项目框架选择Spring-boot
-
想法1:由Java调用python脚本,在不同python脚本中调各大模型的包,远程调用API
问题:
- 异构语言,不易联调
-
想法2:Java语言中封装请求的Request Body,直接调用远程API
由于大模型提供的Java client不完善,所以大部分只能自己手写封装JSON的逻辑 不同模型RequestBody规范不同,Response Body也不同,同时还有不同场景的不同规范…工程量较大
-
想法3:在调用接口过程中发现响应太慢,官方文档提供的解决方案是使用流式查询,查询过程中实时刷新client页面内容;除此之外,我想要不干脆把模型迁移到本地?GPT提供了开源版本,其他模型应该也会提供,如果我将开源的模型在本地用同样的文本训练,最终结果的不同就完全是算法的不同…
现阶段核心代码:
public class PythonEngine {
public static String execPythonScript(String content,AIModules modules){
Process proc;
try {
String[] args1=new String[]{
"C:\\Users\\吴松林\\PycharmProjects\\pythonProject\\.venv\\Scripts\\python.exe",
modules.path,
content,
"user"};
proc = Runtime.getRuntime().exec(args1);
InputStream is = proc.getInputStream();
byte[] bytes = is.readAllBytes();
String ans = new String(bytes, Charset.forName("gbk"));
proc.waitFor();
return ans.length() == 0?"接口异常":ans;
} catch (IOException | InterruptedException e) {
e.printStackTrace();
return "接口异常";
}
}
dashscope.api_key = "yours"
content = sys.argv[1]
def call_with_messages():
messages = [
# {'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': content}]
response = dashscope.Generation.call(
dashscope.Generation.Models.qwen_turbo,
messages=messages,
result_format='message', # set the result to be "message" format.
)
if response.status_code == HTTPStatus.OK:
choices = response.output.choices
for choice in choices:
print(choice.message.content)
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
if __name__ == '__main__':
call_with_messages()
希望看到这里的大佬多多指教
更新:
一版本由于每个请求都通过Runtime.getRuntime().exec()启动一个线程执行脚本,很明显并发场景下并不合适。于是需要一些措施来优化
-
批量 + 同步
想到Kafka中将海量数据通过异步 + 批量操作的方式增强并发,我这里也尝试将并发下的连续多个请求批量传给脚本,由脚本统一调用API,再将结果统一返回
同步是指每个请求先将内容交给执行器,自旋等待结果返回
代码如下:
public class testController {
public static final BlockingQueue<String> currentRequestByKimi = new LinkedBlockingQueue<>();
public static long lastTimeKimi;
public static final BlockingQueue<String> currentRequestByTongyi = new LinkedBlockingQueue<>();
public static final BlockingQueue<String> currentRequestByGPT = new LinkedBlockingQueue<>();
public static final ConcurrentHashMap<String,String> result = new ConcurrentHashMap<>();
@GetMapping("/queryFromKimi")
public String queryFromKimi(@RequestParam String content) throws InterruptedException {
// String ans = PythonEngine.execPythonScript(content, AIModules.KIMI);
currentRequestByKimi.put(content);
result.put(content,"_");
long time;
if((time = System.currentTimeMillis()) - lastTimeKimi > 5) {
synchronized (currentRequestByKimi) {
PythonEngine.execPythonScript(currentRequestByKimi.toArray(), AIModules.KIMI);
lastTimeKimi = time;
}
}
while (result.get(content).equals("_")) {
}
String ans = result.get(content);
System.out.println("kimi-ans" + ans);
return ans;
}
每个大模型对应一个BlockingQueue,每隔5ms将阻塞队列中的消息一并发给执行器,执行器将结果放在static1的map中。而请求的线程自旋check map中有无结果,有则返回
执行器代码:
public static volatile Runtime runtime;
public static Runtime getRuntime() {
// 第一次检查,如果 proc 不为空,则直接返回,避免不必要的同步
if (runtime == null) {
// 同步块,保证只有一个线程进入临界区
synchronized (PythonEngine.class) {
// 第二次检查,确保在同步块内再次检查 proc 的状态
if (runtime == null) {
// 创建 Process 对象的实例
return Runtime.getRuntime();
}
}
}
return runtime;
}
public static void execPythonScript(Object[] content, AIModules modules) {
try {
String[] args1 = new String[3 + content.length];
args1[0] = "C:\\Users\\吴松林\\PycharmProjects\\pythonProject\\.venv\\Scripts\\python.exe";
args1[1] = modules.path;
args1[2] = String.valueOf(content.length);
System.arraycopy(content, 0, args1, 3, 3 + content.length - 3);
Runtime runtime = getRuntime();
Process proc = runtime.exec(args1);
InputStream is = proc.getInputStream();
byte[] bytes = is.readAllBytes();
String ansOrigin = new String(bytes, Charset.forName("gbk"));
ansOrigin = ansOrigin.trim();
if (ansOrigin.startsWith("[")) {
ansOrigin = ansOrigin.substring(1);
}
if (ansOrigin.endsWith("]")) {
ansOrigin = ansOrigin.substring(0, ansOrigin.length() - 1);
}
String[] ans = ansOrigin.split(",");
proc.waitFor();
for (int i = 0; i < content.length; i++) {
testController.result.put((String) content[i],ans[i]);
}
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
基本思路就是用全局单例的进程多次向大模型发起请求
并发测试: 很尴尬的是开发者平台并不支持短时间连续调用
request reached max request: 3, please try again after 1 seconds
解决的思路1:土办法
将多个不同的内容 拼在一个请求中,通过语义区分 例如:当前三个内容
- 你是谁
- 我是谁
- 谁才是唯一的神龙尊者
拼凑出:以下有3个互不相干问题,你需要分别解释:第一个…
结果:
- 你是谁: 我是ChatGPT,一个由OpenAI开发的语言模型,专门设计用于与用户进行对话、回答问题和提供帮助。我被训练来理解和生成自然语言文本,但没有自己的身份或个性,我只是一个程序。
- 我是谁: 这个问题是关于你的身份的询问,而我无法直接知道你是谁。只有你自己才能回答这个问题。你可以回顾你的个人信息、经历、角色和责任来确定自己的身份。
- 谁才是唯一的神龙尊者: 这个问题可能是基于某个特定的背景或故事设定。在一些神话故事或游戏世界中,可能会有一个被称为神龙尊者的角色,但在现实世界中,并没有唯一的神龙尊者。这个问题的答案取决于相关的虚构世界或故事情节。
通过语义尝试拆分结果,但由于结果未必规范,很明显并不可靠
解决的思路2:多准备几个账号,将上层的请求轮询下层的账号来实现每个账号的请求存在间隔
遭遇的问题1:Kimi的并发限制提示如下
request reached max request: 3, please try again after 1 seconds’
我本以为只要间隔在1s以上就不会报错,结果并非这么简单;测试发现有时候sleep了2s,5s还无法保证能够通过,并且kimi后台似乎有算法,使得越是频繁访问的账号访问成功率越低
于是我想通过自旋 + 超时的方式确保成功访问
遭遇的问题2:python脚本中注册好了n个账号,但是执行脚本的线程并不知道哪个账号是长时间没使用的,哪个是刚刚使用过的;我的做法是:需要上层来决定使用哪个账号——Java代码中维护一个自增的序列对应发往脚本的请求,每次发送批量请求时将此数带上
确实选择可用的账号这个逻辑应该由脚本层面负责,暂时标识为TODO
代码:
python脚本
import logging
import time
from openai import OpenAI
import sys
index = int(sys.argv[1])
nums = sys.argv[2]
content = []
for i in range(int(nums)):
content.append(sys.argv[3 + i])
client1 = OpenAI(
api_key="第一个key",
base_url="https://api.moonshot.cn/v1",
)
client2 = OpenAI(
api_key="2",
base_url="https://api.moonshot.cn/v1",
)
client3 = OpenAI(
api_key="3",
base_url="https://api.moonshot.cn/v1",
)
client = [client1, client2, client3]
ans = []
for con in content:
targetClient = client[index % len(client)]
index += 1
while (True):
try:
completion = targetClient.chat.completions.create(
model="moonshot-v1-8k",
messages=[
{"role": "system",
"content": "你是 Kimi,由 Moonshot AI "
"提供的人工智能助手,你更擅长"
"中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI "
"为专有名词,不可翻译成其他语言。"},
{"role": "user", "content": con}
],
temperature=0.3,
)
ans.append(completion.choices[0].message.content)
break
except Exception as e:
# print("被拦截,尝试自旋")
time.sleep(1)
print(ans)
后台主要修改代码:(不明掘金为什么会吞掉缩减)
@GetMapping("/queryFromKimi")
public String queryFromKimi(@RequestParam String content) throws InterruptedException {
currentRequestByKimi.put(content);
result.put(content, "_");
long time;
synchronized (currentRequestByKimi) {
if (lastTimeKimi - (lastTimeKimi = System.currentTimeMillis()) < -1000) {
Object[] execRequests = currentRequestByKimi.toArray();
if (execRequests.length != 0) {
PythonEngine.execPythonScript(execRequests, AIModules.KIMI);
for (int i = 0; i < execRequests.length; i++) {
currentRequestByKimi.poll();
}
}
}
}
while (result.get(content).equals("_")) {
}
return result.get(content);
}
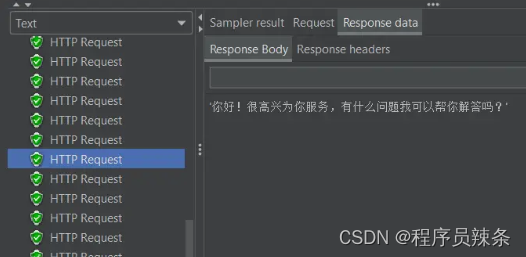
jmeter测试:(现版本QPS和账号数量挂钩)
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 4749
4749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











