







LoRA LOW-RANK ADAPTATION 论文笔记
不懂的问题
线性代数基础
根据线性代数的性质:
-
若 B ∈ R 512 × 4 B \in \mathbb{R}^{512 \times 4} B∈R512×4 和 A ∈ R 4 × 512 A \in \mathbb{R}^{4 \times 512} A∈R4×512,则矩阵乘积 Δ W = B A \Delta W = B A ΔW=BA 的最大秩 rank ( Δ W ) \text{rank}(\Delta W) rank(ΔW) 由 B B B 和 A A A 的秩中较小的那个决定:
rank ( Δ W ) ≤ min ( rank ( B ) , rank ( A ) ) \text{rank}(\Delta W) \leq \min (\text{rank}(B), \text{rank}(A)) rank(ΔW)≤min(rank(B),rank(A)) -
在 LoRA 的低秩分解中:
- B B B 的列数是 4,其秩最多为 4。
- A A A 的行数是 4,其秩最多为 4。
- 因此, Δ W = B A \Delta W = B A ΔW=BA 的秩最多为 4。
-
虽然 Δ W \Delta W ΔW 的尺寸是 512 × 512 512 \times 512 512×512,但它的 列空间维度(rank) 被限制在 4,即列向量最多线性独立的维度是 4。
假设我们有一个 512 × 512 512 \times 512 512×512 的矩阵更新:
- 如果直接更新 Δ W \Delta W ΔW 的每个元素(完整微调),那么矩阵的秩可以达到最大值 512。
- LoRA 的假设是任务适配过程中权重更新的本质维度较低,因此可以用 4 个基向量(来自 B B B 的列空间) 和它们的线性组合来近似表示更新。
这意味着即使 Δ W \Delta W ΔW 的尺寸是 512 × 512 512 \times 512 512×512,其独立的方向(秩)是受 r = 4 r = 4 r=4 的限制的。
所以这正是为什么通过调整 r r r 可以控制 LoRA 的表达能力: r r r 越大,权重更新的潜在方向越多,表达能力越强;当 r r r 接近 512 时,LoRA 的表达能力接近完整微调。
摘要
问题
模型越来越大,全参数 SFT 变的不可行
作者的工作
LORA:该方法冻结预训练模型的权重,并将可训练的秩分解矩阵注入到Transformer架构的每一层,极大地减少了下游任务的可训练参数数量。
结果
- 与使用Adam微调的GPT-3 175B相比,LoRA可以将可训练参数的数量减少10,000倍,并将GPU内存需求减少3倍。
- 尽管可训练参数较少,训练吞吐量更高,并且与适配器不同,不会增加额外的推理延迟,LoRA在RoBERTa、DeBERTa、GPT-2和GPT-3的模型质量上表现与微调持平或更好
引言
- 问题:模型越来越大,全参数 SFT 变的不可行
- 现有解决方法:针对不同任务添加一些参数或者适配器
- 好处:只需要存储和加载少量的任务特定参数,除了每个任务的预训练模型外,极大地提高了部署时的操作效率。
- 缺点:适配器会增加推理了延迟、无法与达到微调基础,在效率和质量直接由权衡
LoRA
- 灵感:LoRA 的灵感来源于研究表明,过参数化的模型其实存在于一个低维空间。也就是说,在模型适应(fine-tuning)过程中,权重的变化可以用一个低秩结构表示(即低秩分解)。
- 核心思想:
- 冻结预训练模型权重:只优化特定层的“变化部分”。
- 低秩分解:通过优化某些密集层变化的低秩分解矩阵(如图中提到的矩阵 AAA 和 BBB),实现模型适应。
- 例如,GPT-3 175B 预训练模型中的一个矩阵,其原始秩(rank)为 12,288,LoRA 只需优化秩 r=1r=1r=1 或 r=2r=2r=2 的矩阵就能完成 fine-tuning。
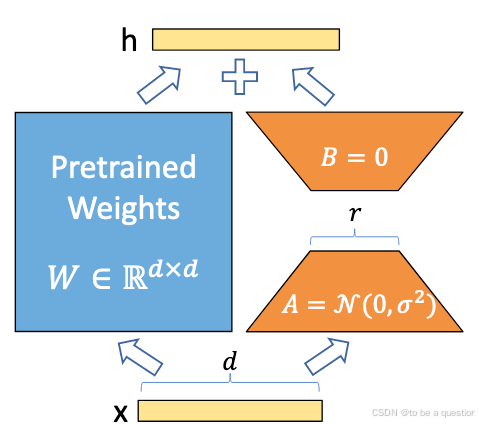
这张图是 LoRA(Low-Rank Adaptation) 方法的关键机制示意图,展示了如何对预训练模型中的权重矩阵 W ∈ R d × d W \in \mathbb{R}^{d \times d} W∈Rd×d 进行低秩分解和优化。
图中元素解释
-
Pretrained Weights W W W:
- W W W 是预训练模型中的一个权重矩阵,其维度为 d × d d \times d d×d。
- 在 LoRA 方法中,这个矩阵 保持冻结(不更新)。
-
输入 x x x 和输出 h h h:
- 输入 x x x 是特征向量,其维度为 d d d。
- 输出 h h h 是经过 LoRA 适配后的向量,作为网络的输出,维度同样为 d d d。
-
低秩分解矩阵 A A A 和 B B B:
- LoRA 引入两个小规模的低秩矩阵 A ∈ R d × r A \in \mathbb{R}^{d \times r} A∈Rd×r 和 B ∈ R r × d B \in \mathbb{R}^{r \times d} B∈Rr×d,其中 r ≪ d r \ll d r≪d(例如 r = 1 r=1 r=1 或 r = 2 r=2 r=2)。
- A A A 和 B B B 的作用是近似描述 W W W 的变化(即微调时需要的调整量 Δ W \Delta W ΔW)。
- 在初始化时:
- A A A 通常从高斯分布 N ( 0 , σ 2 ) \mathcal{N}(0, \sigma^2) N(0,σ2) 中随机采样。
- B B B 初始化为零矩阵。
-
模型调整机制:
- 微调时,仅优化 A A A 和 B B B 的参数,而不改变 W W W。
- 输入 x x x 经过计算后产生一个调整量:
Δ h = B ⋅ ( A ⋅ x ) \Delta h = B \cdot (A \cdot x) Δh=B⋅(A⋅x) - 最终输出为:
H = W ⋅ x + Δ h H = W \cdot x + \Delta h H=W⋅x+Δh - 这表明模型输出是预训练权重 W W W 的结果加上一个低秩调整项。
LoRA 优势
-
共享和高效任务切换:
- 模块化:预训练模型可以用于多个任务。LoRA 通过替换不同的低秩矩阵 AAA 和 BBB,实现了高效的任务切换。
- 减少存储需求:因为只需要存储这些小的矩阵,而不是整个模型参数。
-
提高训练效率:
- 降低硬件门槛:相比传统方法,LoRA 只优化小规模矩阵,因此显著减少计算量。根据文中描述,可以将所需的硬件资源减少到原来的三分之一。
-
零推理延迟:
- LoRA 的设计可以在部署时将优化的矩阵与预训练权重合并,因此不会增加推理延迟。
-
方法的通用性和组合性:
- LoRA 独立于其他方法,如前缀微调(prefix-tuning),并且可以与这些方法组合使用以增强效果。
术语约定
- 关于 Transformer 的术语和维度
-
d model d_{\text{model}} dmodel:
- 表示 Transformer 模型中某一层的输入和输出向量的维度。
- 在 Transformer 的每一层中,所有的输入和输出张量都会使用这个维度。
-
投影矩阵(Projection Matrices):
- W q W_q Wq:用于生成 query(查询向量)的投影矩阵。
- W k W_k Wk:用于生成 key(键向量)的投影矩阵。
- W v W_v Wv:用于生成 value(值向量)的投影矩阵。
- W o W_o Wo:表示 输出投影矩阵。
- 这些矩阵都位于 自注意力模块(self-attention module) 内,是 Transformer 的核心部分。
-
- 权重的定义
-
W W W 或 W 0 W_0 W0:
- 代表 Transformer 中某一层的 预训练权重矩阵,这些矩阵通过预训练模型获得,在微调时被冻结(即不被更新)。
-
Δ W \Delta W ΔW:
- 代表 LoRA 在微调过程中累计更新的权重变化量。
- LoRA 的核心思想是通过优化这个权重变化量,而不是直接修改原始的权重矩阵 W W W。
-
- LoRA 的秩(Rank) r r r
- r r r:
- 表示 LoRA 中低秩分解矩阵的秩(rank)。
- r r r 通常远小于 d model d_{\text{model}} dmodel,用来表示矩阵分解的低维度,从而降低优化问题的计算复杂度。
- r r r:
- 优化方法和架构设置
-
优化方法:
- 作者采用了 Adam 优化器,这是一个在深度学习中常用的自适应学习率优化算法(参考:Loshchilov & Hutter, 2019 和 Kingma & Ba, 2017)。
-
MLP 维度设置:
- Transformer 中多层感知机(MLP)的隐藏层维度定义为:
D ffn = 4 × d model D_{\text{ffn}} = 4 \times d_{\text{model}} Dffn=4×dmodel - 意味着 MLP 的隐藏层通常比输入输出的维度大 4 倍,用于增强模型的非线性表达能力。
- Transformer 中多层感知机(MLP)的隐藏层维度定义为:
-
问题陈述
LoRA 不涉及 loss 的设计,而是专注于语言建模任务的优化方法
1. 背景:预训练模型
假设我们有一个预训练的自回归语言模型(autoregressive language model):
P Φ ( y ∣ x ) P_\Phi (y|x) P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









