






一、哈希概念
1. 哈希表
哈希表(Hash Table):也叫做散列表。是根据关键码值(Key Value)直接进行访问的数据结构。
哈希表通过「键 key 」和「映射函数 Hash(key) 」计算出对应的「值 value」,把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做「哈希函数(散列函数)」,存放记录的数组叫做「哈希表(散列表)」。
1.1 散列表目的与特性
数组的最大特点:寻址容易,插入和删除困难;
链表的特点正好相反:寻址困难,而插入和删除操作容易。
哈希表的特点:寻址插入和删除操作都容易。
那么如果能够结合两者的优点,做出一种寻址、插入和删除操作同样快速容易的数据结构,那该有多好,这就是哈希表创建的基本思想,哈希表就是这样一个集查找、插入和删除操作于一身的数据结构。
1.2 哈希表的关键思想
哈希表的关键思想是使用哈希函数,将键 key 映射到对应表的某个区块中。我们可以将算法思想分为两个部分:
- 向哈希表中插入一个关键码值:哈希函数决定该关键字的对应值应该存放到表中的哪个区块,并将对应值存放到该区块中。
- 在哈希表中搜索一个关键码值:使用相同的哈希函数从哈希表中查找对应的区块,并在特定的区块搜索该关键字对应的值。
1.3 哈希表的实现
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity
capacity为存储元素底层空间总的大小。

哈希表在生活中的应用也很广泛,其中一个常见例子就是「查字典」。
比如为了查找 赞 这个字的具体意思,我们在字典中根据这个字的拼音索引 zan,查找到对应的页码为 599。然后我们就可以翻到字典的第 599 页查看赞字相关的解释了。

在这个例子中:
存放所有拼音和对应地址的表可以看做是「哈希表」。
赞字的拼音索引zan可以看做是哈希表中的「关键字 key」。
根据拼音索引zan来确定字对应页码的过程可以看做是哈希表中的「哈希函数 Hash(key)」。
查找到的对应页码599可以看做是哈希表中的「哈希地址 value」。
1.4 什么是 key
key :就是关键值的意思,在哈希表中的 key 值是不允许重复的,就说明它是唯一的,可以通过唯一的 key 来查找相应的 value 值。
key - value:哈希表中的一对键值对;
一对键值对通过哈希函数获得对应下标并映射到表中;

2. 哈希函数
哈希函数(Hash Function):将哈希表中元素的关键键值映射为元素存储位置的函数。
哈希函数是哈希表中最重要的部分。一般来说,哈希函数会满足以下几个条件:
- 哈希函数应该易于计算,并且尽量使计算出来的索引值均匀分布。
- 哈希函数计算得到的哈希值是一个固定长度的输出值。
如果Hash(key1)不等于Hash(key2),那么 key1、key2 一定不相等。
如果Hash(key1)等于Hash(key2),那么 key1、key2 可能相等,也可能不相等(会发生哈希碰撞)。
在哈希表的实际应用中,关键字的类型除了数字类,还有可能是字符串类型、浮点数类型、大整数类型,甚至还有可能是几种类型的组合。一般我们会将各种类型的关键字先转换为整数类型,再通过哈希函数,将其映射到哈希表中。
而关于整数类型的关键字,通常用到的哈希函数方法有:直接定址法、除留余数法、平方取中法、基数转换法、数字分析法、折叠法、随机数法、乘积法、点积法等。
2.1 直接定址法
直接定址法:取关键字本身 / 关键字的某个线性函数值 作为哈希地址。
即:Hash(key) = key 或者 Hash(key) = a * key + b,其中 a 和 b 为常数。
这种方法计算最简单,且不会产生冲突。适合于关键字分布基本连续的情况,如果关键字分布不连续,空位较多,则会造成存储空间的浪费。
举一个例子,假设我们有一个记录了从 1 岁到 100 岁的人口数字统计表。其中年龄为关键字,哈希函数取关键字自身,如下表所示。

比如我们想要查询 25 岁的人有多少,则只要查询表中第 25 项即可。
优点:以关键码key的某个线性函数值为哈希地址,不会产生冲突;
缺点:要占用连续地址空间,空间效率低。
2.2 除留余数法
除留余数法:假设哈希表的表长为 m,取一个不大于 m 但接近或等于 m 的质数 p,利用取模运算,将关键字转换为哈希地址。即:Hash(key) = key % p,其中 p 为不大于 m 的质数。
这也是一种简单且常用的哈希函数方法。其关键点在于 p 的选择。根据经验而言,一般 p 取素数或者 m,这样可以尽可能的减少冲突。
比如我们需要将 7 个数 [ 432, 5, 128, 193, 92, 111, 88 ] 存储在 11 个区块中(长度为 11 的数组),通过除留余数法将这 7 个数应分别位于如下地址:
特点:以关键码除以p的余数作为哈希地址。
技巧:若设计的哈希表长为m,则一般取p≤m且为质数 (也可以是不包含小于20质因子的合数)。
eg: 432 % 11 = 3

2.3 平方取中法
平方取中法:先通过求关键字平方值的方式扩大相近数之间的差别,然后根据表长度,取关键字平方值的中间几位数为哈希地址。
- 理由:因为中间几位与数据的每一位都相关。
- 例:2589的平方值为6702921,可以取中间的029为地址。
这种方法因为关键字平方值的中间几位数和原关键字的每一位数都相关,所以产生的哈希地址也比较均匀,有利于减少冲突的发生。
3. 哈希冲突
哈希冲突(Hash Collision):不同的关键字通过同一个哈希函数可能得到同一哈希地址,即 key1 ≠ key2,而 Hash(key1) = Hash(key2),这种现象称为哈希冲突。
理想状态下,我们的哈希函数是完美的一对一映射,即一个关键字(key)对应一个值(value),不需要处理冲突。但是一般情况下,不同的关键字 key 可能对应了同一个值 value,这就发生了哈希冲突。
设计再好的哈希函数也无法完全避免哈希冲突。所以就需要通过一定的方法来解决哈希冲突问题。常用的哈希冲突解决方法主要是两类:「开放地址法(Open Addressing)」 和 「链地址法(Chaining)」。
4. 哈希冲突解决办法
4.1 开放地址法
开放地址法(Open Addressing):指的是将哈希表中的「空地址」向处理冲突开放。当哈希表未满时,处理冲突时需要尝试另外的单元,直到找到空的单元为止。
当发生冲突时,开放地址法按照下面的方法求得后继哈希地址:H(i) = (Hash(key) + F(i)) % m,i = 1, 2, 3, ..., n (n ≤ m - 1)。
- H(i) 是在处理冲突中得到的地址序列。即在第 1 次冲突(i = 1)时经过处理得到一个新地址 H(1),如果在 H(1) 处仍然发生冲突(i = 2)时经过处理时得到另一个新地址 H(2) …… 如此下去,直到求得的 H(n) 不再发生冲突。
- Hash(key) 是哈希函数,m 是哈希表表长,对哈希表长取余的目的是为了使得到的下一个地址一定落在哈希表中。
- F(i) 是冲突解决方法,取法可以有以下几种:
线性探测法
二次探测法
伪随机数序列
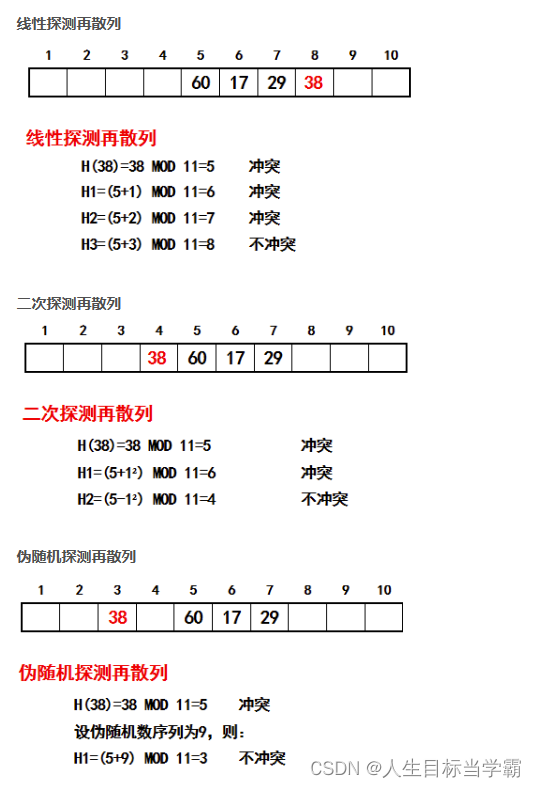
举个例子说说明一下如何用以上三种冲突解决方法处理冲突,并得到新地址 H(i)。例如,在长度为 11 的哈希表中已经填有关键字分别为 28、49、18 的记录(哈希函数为 Hash(key) = key % 11)。现在将插入关键字为 38 的新纪录。根据哈希函数得到的哈希地址为 5,产生冲突。接下来分别使用这三种冲突解决方法处理冲突。
4.1.1 使用线性探测法:得到下一个地址 H(1) = (5 + 1) % 11 = 6,仍然冲突;继续求出 H(2) = (5 + 2) % 11 = 7,仍然冲突;继续求出 H(3) = (5 + 3) % 11 = 8,8 对应的地址为空,处理冲突过程结束,记录填入哈希表中序号为 8 的位置。
4.1.2 使用二次探测法:得到下一个地址 H(1) = (5 + 1*1) % 11 = 6,仍然冲突;继续求出 H(2) = (5 - 1*1) % 11 = 4,4 对应的地址为空,处理冲突过程结束,记录填入哈希表中序号为 4 的位置。
4.1.3 使用伪随机数序列:假设伪随机数为 9,则得到下一个地址 H(1) = (9 + 5) % 11 = 3,3 对应的地址为空,处理冲突过程结束,记录填入哈希表中序号为 3 的位置。
使用这三种方法处理冲突的结果如下图所示:

例子:
例如表长为11的哈希表已经填有关键字为17、60、29的记录,现将一关键字为38的新记录填入哈希表,利用上述三种方法得到的过程与结果分别如下:
4.2 链地址法
链地址法(Chaining):将具有相同哈希地址的元素(或记录)存储在同一个线性链表中。
链地址法是一种更加常用的哈希冲突解决方法。相比于开放地址法,链地址法更加简单。
我们假设哈希函数产生的哈希地址区间为 [0, m - 1],哈希表的表长为 m。则可以将哈希表定义为一个有 m 个头节点组成的链表指针数组 T。
- 这样在插入关键字的时候,我们只需要通过哈希函数 Hash(key) 计算出对应的哈希地址 i,然后将其以链表节点的形式插入到以 T[i] 为头节点的单链表中。在链表中插入位置可以在表头或表尾,也可以在中间。
- 在查询关键字的时候,我们只需要通过哈希函数 Hash(key) 计算出对应的哈希地址 i,然后将对应位置上的链表整个扫描一遍,比较链表中每个链节点的键值与查询的键值是否一致
举个例子来说明如何使用链地址法处理冲突。假设现在要存入的关键字集合 keys = [ 88, 60, 65, 69, 90, 39, 07, 06, 14, 44, 52, 70, 21, 45, 19, 32 ]。再假定哈希函数为 Hash(key) = key % 13,哈希表的表长 m = 13,哈希地址范围为 [ 0, m - 1 ],即[ 0 , 12 ]。将这些关键字使用链地址法处理冲突,并按顺序加入哈希表中(图示为插入链表表尾位置),最终得到的哈希表如下图所示:

相对于开放地址法,采用链地址法处理冲突要多占用一些存储空间(主要是链节点占用空间)。但它可以减少在进行插入和查找具有相同哈希地址的关键字的操作过程中的平均查找长度。这是因为在链地址法中,待比较的关键字都是具有相同哈希地址的元素,而在开放地址法中,待比较的关键字不仅包含具有相同哈希地址的元素,而且还包含哈希地址不相同的元素。
4.3 降低冲突率
冲突率:新放入一个元素,它的冲突概率
负载因子:哈希表中已有的元素 / 哈希表的长度 (刚开始的时候没有元素,不会冲突,随着放入的元素越来越多,只要一直放入,总会让冲突率达到 100%)
所以要把负载因子控制在一个阈值之下
- 负载因子 size / length ,我们要想将其控制到一个阈值之内,要么减少 size,要么增大 length,但是减少 size 的情况我们一般不去考虑,那么就只有增加 length 这个方法,那么就要对哈希表进行扩容;
- 一般将负载因子为 3 / 4 作为扩容的临界点;

5. 哈希表总结
哈希表(Hash Table):通过键 key 和一个映射函数 Hash(key) 计算出对应的值 value,把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
哈希函数(Hash Function):将哈希表中元素的关键键值映射为元素存储位置的函数。
哈希冲突(Hash Collision):不同的关键字通过同一个哈希函数可能得到同一哈希地址。
哈希表的两个核心问题是:「哈希函数的构建」 和 「哈希冲突的解决方法」。
常用的哈希函数方法有:直接定址法、除留余数法、平方取中法、基数转换法、数字分析法、折叠法、随机数法、乘积法、点积法等。
常用的哈希冲突的解决方法有两种:开放地址法 和 链地址法。
6.比较对象相等时,hashCode与equals关系
a.hashCode相同他们的equals一定相同吗:false
不同的key值可能对应相同的hash值,有哈希冲突,此时对象的equals是不相等的。
b.equals相同的对象,他们的hashCode的值一定相同吗:true
equals同,key值同,所以hash的值肯定相同。
7. 哈希表的结构
JDK1.8以前哈希表是由数组+链表组成
JDK1.8开始哈希表是由数组+链表+红黑树组成
加入红黑树的好处:
链表的特点是增删快,查询慢。所以链表越长就会导致查询越慢,而红黑树恰好解决这一问题。
数组长度:未定义数组长度会创建一个初始化长度为16的数组。
8. 哈希表的扩容
哈希表的底层数组会在一下两种情况下扩容:
- 当同一索引值下的元素超过8个且数组长度小于64;
- 数组的索引值占有率超过0.75时(0.75为加载因子,加载因子是可以自己设置的,0.75是默认值)。
扩容后的新容量就等于旧容量的二倍
可以借助下面的图来理解:

如图所示,当数组长度为16,索引值0下面的元素超过8个,数组就会扩容,数组长度变为32,而索引值0会与索引值16平分索引值0下的元素。直到数组长度达到64,那么此时,索引值0会与索引值32平分,索引自16会与索引值48平分。
当数组的长度大于64且同一索引值位置下元素超过8

二、哈希表的实现
1. 哈希表的新增
计算新增元素的哈希值。
用hash%数组长度,计算索引值。
判断该索引值位置是否为空;
如果该索引值为空直接新增;
如果不为空,则判断该索引值位置的元素是否重复;
如果不重复则新增到链表的最后。
如果重复则不新增;
2. 哈希表主要方法实现
首先创建Node 类,代表的是链表的结点;
public class Node {
public String key;
public Long value;
public Node next;
public Node(String key, Long value) {
this.key = key;
this.value = value;
}
}
再创建一个 MyHashMap 类,来存放哈希表的属性以及各种方法的实现
public class MyHashMap {
private static final double THRESHOLD = 0.75; // 扩容的临界值
// 元素类型是链表(以链表的头结点代表)的数组
private Node[] array; // 数组的每个元素都代表一条独立的链表
private int size;
public MyHashMap() {
array = new Node[7];
size = 0;
}
get() 方法
get() 方法是用来查找哈希表中的某个元素;
1.首先获取 key 的 hashCode 值,将 key 转化成一个整型,然后通过哈希,变为一个合法的数组下标 index;
2.根据 index 可以获得一条链表;
3.遍历链表,查找链表中的 key 是否和 传入的 key 相等,若查询到就返回该 key 的 value 值,否则返回 null;
public Long get(String key) {
int n = key.hashCode(); //获取 key 的 hashCode 值
//把 n 这个整型转换成一个合法的数组下标(假设 n >= 0)
int index = n % array.length;
// 我们已经有了 index 这个下标,所以,可以从数组中得到一条链表
// 这个链表的头结点就是 array[index];
Node head = array[index];
//遍历整条链表
for (Node cur = head; cur != null; cur = cur.next) {
// 比较 key 和 cur.key 是否相等
if (key.equals(cur.key)) { // 要用 equals 比较
// 查询到就返回该 key 的 value 值
return cur.value;
}
}
// 说明链表都遍历完了,也没有找到 key,说明 key 不在哈希表中
// 返回 null,表示没有找到
return null;
}
put() 方法
put() 方法就是在哈希表中放入或者修改某个数据的操作;
1.首先获取 key 的 hashCode 值,将 key 转化成一个整型,然后通过哈希,变为一个合法的数组下标 index;
2.根据 index 可以获得一条链表;
3.遍历链表,查找链表中的 key 与 传入的 key 是否相等,相等则将原有的 value 值更新为传入的 value,否则将传入的 key - value 以头插方式放入链表;
4.放入元素后 size++;
5.判断是否需要扩容;
public Long put(String key, Long value) {
// 放入 or 更新
//要求和 get 必须统一
int n = key.hashCode();
//要求和 get 必须统一
int index = n % array.length;
//得到代表链表的头结点
Node head = array[index];
//遍历链表,查找 key 是否存在(如果存在,则是更新操作;否则是放入操作)
for (Node cur = head; cur != null; cur = cur.next) {
if (key.equals(cur.key)) {
// 找到了说明存在,进行更新操作
Long oldValue = cur.value;
cur.value = value;
return oldValue; // 返回原来的 value ,代表是更新
}
}
// 遍历完成,没有找到,则进行插入操作
//把 key、value 装到链表的结点中
Node node = new Node(key, value);
// 使用头插
node.next = array[index];
array[index] = node;
//增加 size
size++;
//扩容
if (1.0 * size / array.length > THRESHOLD) {
growCapacity();
}
//返回 null,代表插入
return null;
}
growCapacity() 扩容方法
growCapacity() 方法就是再负载因子大于 3 / 4 时对哈希表进行扩容来保证冲突率控制在一定范围以下;
1.考虑到扩容以后,数组 length 变大,使得原来的元素的 index 会产生变化,所以需要把哈希表中的每一个 key - value 对重新计算它的 index;
2.遍历数组中的每个元素(每条链表),再遍历每个链表中的每个结点(每对 key - value),重新计算其 index;
3.一个个头插元素,更新它们的 next 属性;
private void growCapacity() {
//扩大 length
Node[] newArray = new Node[array.length * 2];
for (int i = 0; i < array.length; i++) { // 遍历数组中的每个元素(每条链表)
Node next;
for (Node cur = array[i]; cur != null; cur = next) { // 遍历链表中的每个结点
int n = cur.key.hashCode();
int index = n % newArray.length; //重新计算 index
// 按照头插的方式,将结点,插入到 newArray 的 [index] 位置的新链表中
next = cur.next; // 因为要把结点插入到新链表中,所有 next 会变化
// 为了能让老链表继续遍历下去,需要提前记录老的 next
cur.next = newArray[index]; // 头插
newArray[index] = cur;
}
}
array = newArray;
}
remove() 方法
remove() 方法就是再哈希表中查找某个元素并将其进行删除;
1.首先获取 key 的 hashCode 值,将 key 转化成一个整型,然后通过哈希化,变为一个合法的数组下标 index;
2.根据 index 可以获得一条链表;
3.遍历链表,若第一个结点就是要删除的 key,那么直接让头结点变为第一个结点的下一个结点;
4.若不是第一个结点,证明该结点有前驱结点,让 pre.next = cur.next,然后返回删除结点的 value;
5.若没找到 key 那么就返回 null;
public Long remove(String key) {
// 删除
int n = key.hashCode();
int index = n % array.length;
// 如果第一个结点的 key 就是要删除的 key,没有前驱结点
if (array[index] != null && key.equals(array[index].key)) {
Node head = array[index];
array[index] = array[index].next;
return head.value;
}
Node prev = null; //记录前驱结点
Node cur = array[index];
while (cur != null) {
if (key.equals(cur.key)) {
// 删除链表中的结点,需要前驱结点
prev.next = cur.next; // 删除 cur 结点
return cur.value;
}
prev = cur;
cur = cur.next;
}
return null;
}
size() 方法
size() 方法就是获取哈希表中元素个数的操作;
直接返回 size 即可
public int size() {
return size;
}
isEmpty() 方法
isEmpty() 方法是判断哈希表是否为空;
直接判断 size() 是否为 0
public boolean isEmpty() {
return size() == 0;
}















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









