







栈
一、栈的逻辑结构和操作
1.1 栈的定义
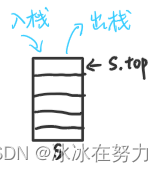
- 只允许在一端进行插入或删除操作的线性表
- 栈顶:允许进行插入删除的一端
- 栈底:固定的一端
1.2 栈的性质
- 操作特性:先进后出
- 数学特性:n个不同元素进栈,出栈元素的不同排列的个数为 1 n + 1 C 2 n n \frac{1}{n+1} C_{2n}^{n} n+11C2nn (卡特兰数)
1.3 栈的操作
| 操作 | 作用 |
|---|---|
| InitStack(SqStack &S) | 构造空栈 |
| DestroyStack(SqStack &S) | 销毁栈 |
| ClearStack(SqStack &S) | 清空栈 |
| StackEmpty(SqStack S) | 判断是否为空栈 |
| StackLength(SqStack S) | 返回栈元素个数 |
| GetTop(SqStack S,SElemType &e) | 读栈顶元素 |
| Push(SqStack &S,SElemType e) | 入栈 |
| pop(SqStack &S,SElemType &e) | 出栈 |
StackTraverse(SqStack S,Status (*visit)()) | 从栈底到栈顶visit() |
二、栈的存储结构
2.1 栈的顺序存储结构
2.1.1 顺序栈的定义
- 利用一组地址连续的存储单元存放自栈底到栈顶的数据元素
2.1.2 顺序栈的实现
| 条件 | 实现 |
|---|---|
| 栈顶指针 | S.top,初始时设置S.top=-1 |
| 进栈操作 | 栈不满时,栈顶指针先加1,再送值到栈顶元素 |
| 栈空条件 | S.top==-1 |
| 出栈操作 | 栈非空时,先找栈顶元素值,再将栈顶指针减1 |
| 栈满条件 | S.top==Maxsize-1 |
| 栈长 | S.top+1 |
2.1.2.1 结构体
#define Maxsize 50
typedef struct
{
Elemtype data[Maxsize]; //存放栈中元素
int top; //栈顶指针
} SqStack;
2.1.2.2 初始化
void InitStack(SqStack &S)
{
S.top = -1;
}
2.1.2.3 判栈空
bool StackEmpty(SqStack S)
{
if (S.top == -1)//栈空
return true;
else
return false;
}
2.1.2.4 进栈
bool Push(SqStack &S, ElemType x)
{
if (S.top == Maxsize - 1) //栈满
return false;
S.data[++S.top] = x return ture;
}
2.1.2.5 出栈
bool Pop(SqStack &S, ElemType &x)
{
if (S.top == -1) //栈空
return false;
S.data[S.top--] = x return ture;
}
2.1.2.6 读栈顶的元素
bool GetTop(SqStack S, ElemType &x)
{
if (S.top == -1)//栈空
return false;
x = S.data[S.top] return ture;
}
2.1.3 共享栈
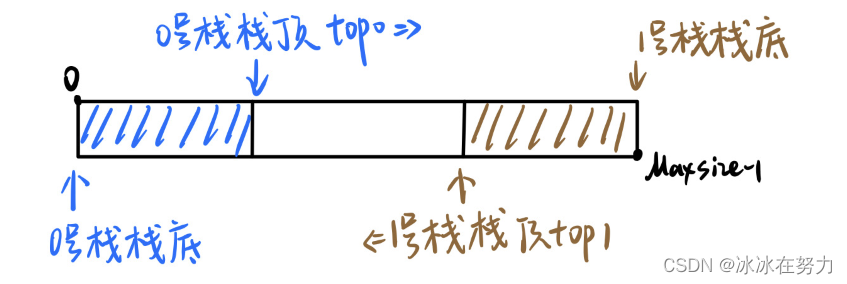
2.1.3.1 共享栈的定义
- 利用栈底位置相对不变的特性,可让两个顺序栈共享一个一维数组空间
- 将两个栈的栈底分别设置在共享空间的两端,两个栈顶向共享空间的中间延伸
2.1.3.2 共享栈的特点
- t o p 0 = − 1 top0=-1 top0=−1,0号栈为空 t o p 1 = M a x s i z e top1=Maxsize top1=Maxsize,1号栈为空
- t o p 1 − t o p 0 = 1 top1-top0=1 top1−top0=1时,栈满
- 0号栈进栈,top0先加 1,再赋值,1号栈进栈,top1先减 1,再赋值
2.1.3.3 共享栈的目的
- 更有效地利用存储空间
- 两个栈的空间相互调节,只有在整个存储空间都被占满时才发生上溢
2.2 栈的链式存储结构
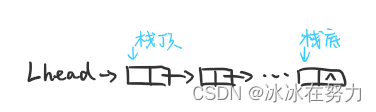
2.2.1 链栈的定义
2.2.2 链栈的优点
- 便于多个栈共享存储空间和提高其效率,且不存在栈满上溢的情况
2.2.3 链栈的特点
- 通常采用单链表实现,并规定所有操作都是在单链表的表头进行的
- 这里规定链栈没有头结点,Lhead指向栈顶元素
2.2.4 链栈的实现
typedef struct Linknode
{
Elemtype data; //存放栈中元素
struct Linknode *next; //栈顶指针
} * LiStack;
三、栈的应用
3.1 数制转换
3.1.1 实现逻辑
十进制数N和其他d进制数的转换
- 算法原理:N=(N div d)×d+N mod d
- div:整除,mod:求余
例子: ( 1348 ) 10 = ( 2504 ) 8 (1348)_{10}=(2504)_{8} (1348)10=(2504)8
| N | N div 8 | N mod 8 |
|---|---|---|
| 1348 | 168 | 4 |
| 168 | 21 | 0 |
| 21 | 2 | 5 |
| 2 | 0 | 2 |
3.1.2 实现代码
void conversuon(){
InitStack(S);
scanf("%d",&N);
while(N){
Push(S,N%8);
N = N/8;
}
while(!StackEmpty(S)){
Pop(S,e);
printf("%d",e);
}
}
3.2 括号匹配
3.2.1 括号匹配的实现逻辑
- 初始化一个空栈,顺序读入括号
- 若是右括号则与栈顶元素进行匹配(若匹配,则弹出栈顶元素并进行下一元素;若不匹配,则该序列不合法)
- 若是左括号,则压入栈中
- 若全部元素遍历完毕,栈中仍然存在元素,则该序列不合法
3.3 行编辑程序
3.3.1 行编辑程序的实现逻辑
一个简单的行编辑程序的功能是:接收用户从终端输入的程序或数据,并存入用户的数据区。
当用户发现刚刚键入的一个字符是错的时,可补进一个退格符“#”,以表示前一个字符无效
如果发现当前键入的行内错误较多或难以补救,则可以键入一个退行符“@”,以表示当前行中的字符均无效。
例如:假设从终端接收了这样的两行字符:
whil##ilr#e(s#*s)
outcha@ putchar(*s=#++);
则实际有效的是下列两行:
while(*s)
putchar(*s++);
3.4 迷宫求解
3.4.1 迷宫求解的实现逻辑
迷宫求解在求解时使用“穷举法”,容易一个点按照上右下左走,走到死胡同就回溯到上一个方块。
为了保证在任何位置上都能沿原路退回(称为回溯),需要保存从入口到当前位置的路径上走过的方块,由于回溯的过程是从当前位置退回到前一个方块,体现出后进先出的特点,所以采用栈来保存走过的方块。
算法中应保证试探的相邻可走方块不是已走路径上的方块,不然可能会发生死循环。
3.5 表达式求解
算术表达式是由操作数(运算数)、运算符(操作符)、和界线符(括号)三部分组成
3.5.1 前缀表达式
3.5.1.1 前缀表达式的定义
如果是在两个操作数之前,那么这个表达式就是前缀表达式,又称波兰表达式
3.5.1.2 前缀表达式的实现逻辑
从右至左扫描表达式,遇到数字时,将数字压入堆栈,遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算,注意先后
栈顶元素 op 次顶元素
并将结果入栈;重复上述过程直到表达式最左端,最后运算得出的值即为表达式的结果
3.5.2 中缀表达式
3.5.2.1 中缀表达式的定义
如果是跟在两个操作数之间,那么这个表达式就是中缀表达式
3.5.2.2 中缀表达式的实现逻辑
先乘除后加减,有括号先算括号内的。
同一优先级运算,从左向右依次进行。
设置两个栈,一个数字栈numStack,用于存储表达式中涉及到的数字,一个符号栈operatorStack,用于存储表达式中涉及到的运算符
逐个分析栈内字符
1.如果是数字,再看下一个是不是数字,连一起,直到遇到运算符,连完放数字栈内。
2.如果是运算符,符号栈空直接压,不空进行优先权判断1.当前运算符优先级大于等于栈顶运算符则直接压入栈中
2.优先级低于栈顶运算符,则从数字栈中取出两个数据,将当前栈顶运算符弹出进行运算,将结果压入数字栈中,将当前运算符也压入运算符栈中,遇到左括号,直接入操作符栈,遇到右括号,则直接出栈并计算,直到遇到左括号。3.此时数字与运算符都已经压入栈中,此时运算符栈中均为优先级相同的运算符,需要进行收尾操作,如果运算符栈不为空,则依次从数字栈中弹出两个数据,与当前栈顶的运算符进行运算。将结果压入数字栈中。最后数字栈中的数字就是所要求解的结果
3.5.3 后缀表达式
3.5.3.1 后缀表达式的定义
如果每个操作符跟在它的两个操作数之后,那么这个表达式就是后缀表达式,又称为逆波兰表达式
3.5.3.2 后缀表达式的实现逻辑
- 与前缀表达式类似,只是顺序是从左至右
- 从左至右扫描表达式,遇到数字时,将数字压入堆栈,遇到运算符时,弹出栈顶的两个数,其中先出栈的是右操作数,后出栈的是左操作数,用运算符对它们做相应的计算(次顶元素 op 栈顶元素),并将结果入栈
- 重复上述过程直到表达式最右端,最后运算得出的值即为表达式的结果
3.5.4 相互转换
中缀表达式:
(a+b)*c+d-(e+g)*h
前缀表达式:-+*+abcd*+egh
后缀表达式:ab+c*d+eg+h*-
3.5.4.1 中缀表达式转前、后缀表达式
以下全为手算思路,机算参考:中缀/后缀/前缀表达式C代码实现
3.5.4.1.1 加括号法
中缀表达式:
(a+b)*c+d-(e+g)*h
- 加括号:
((((a+b)*c)+d)-((e+g)*h))- 符号提前是前缀中转式,符号放后是后缀中转式
前缀中转式:-(+(*(+(ab)c)d)*(+(eg)h))
后缀中转式:((((ab)+c)*d)+((eg)+h)*)-- 去括号
前缀表达式:-+*+abcd*+egh
后缀表达式:ab+c*d+eg+h*-
3.5.4.1.2 遍历树
中缀表达式:
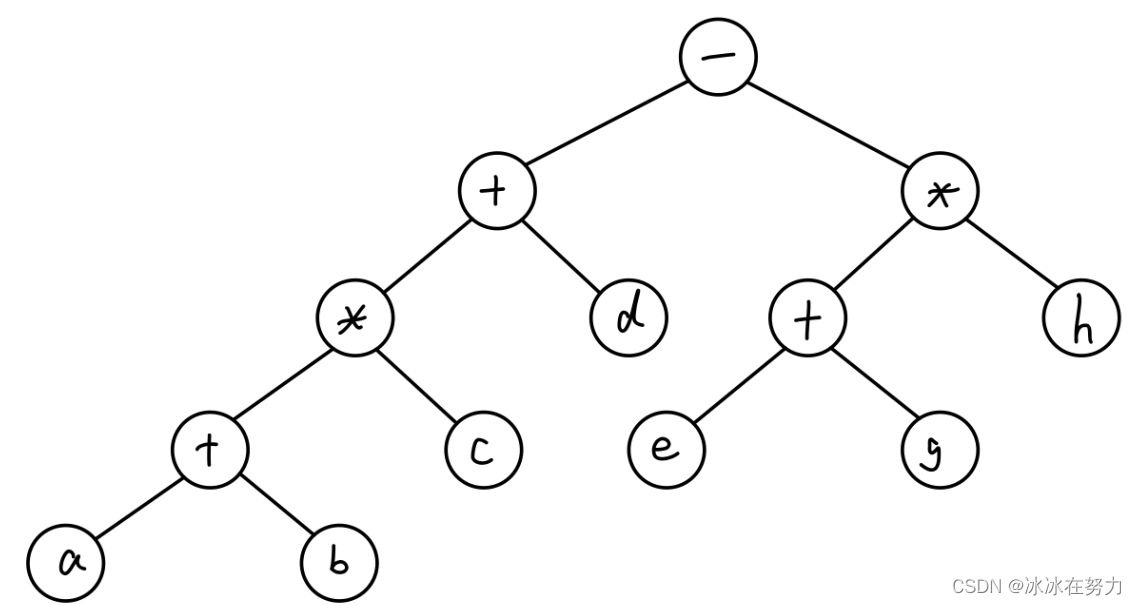
(a+b)*c+d-(e+g)*h
- 写表达式树
- 先序遍历是前缀表达式,后序遍历是后缀表达式
3.5.4.1.3 入栈法
- 扫描中缀表达式
中缀转后缀:从左到右扫描
中缀转前缀:从右到左扫描
- 遇到操作数直接写
- 遇到操作符入栈,和栈顶比较
中缀转后缀:优先级小于等于, 则栈顶出栈
中缀转前缀:优先级小于,则栈顶出栈,所得结果逆序
- 左括号相当于部分栈底, 右括号相当于部分栈顶, 均直接入栈出栈
3.5.4.2 前、后缀表达式转中缀表达式
3.5.4.2.1 先加后去括号法
前缀表达式:
-+*+abcd*+egh
后缀表达式:ab+c*d+eg+h*-
- 扫描方式
前缀转中缀:从右到左扫描
后缀转中缀:从左到右扫描
- 遇到连续两个表达式加一个运算符的组合,就处理,相当于有一个数值栈
- 后缀转中缀:
(a+b)c*d+eg+h*-
((a+b)*c)d+eg+h*-
(((a+b)*c)+d)eg+h*-
(((a+b)*c)+d)(e+g)h*-
(((a+b)*c)+d)((e+g)*h)-
((((a+b)*c)+d)-((e+g)*h))
- 适当去无用括号:
(a+b)*c+d-(e+g)*h
3.5.4.2.2 扫描推栈法建树
前缀转中缀:从右到左扫描
后缀转中缀:从左到右扫描
遇到运算符建单点树
3.5.4.3 后、前缀表达式转前、后缀表达式
3.5.4.3.1 先加再移后去括号法
在去括号前,把符号移动括号前
本质:中缀过渡
3.5.4.3.2 扫描推栈法建树
重新遍历树
3.5.4.3.2 栈计算法
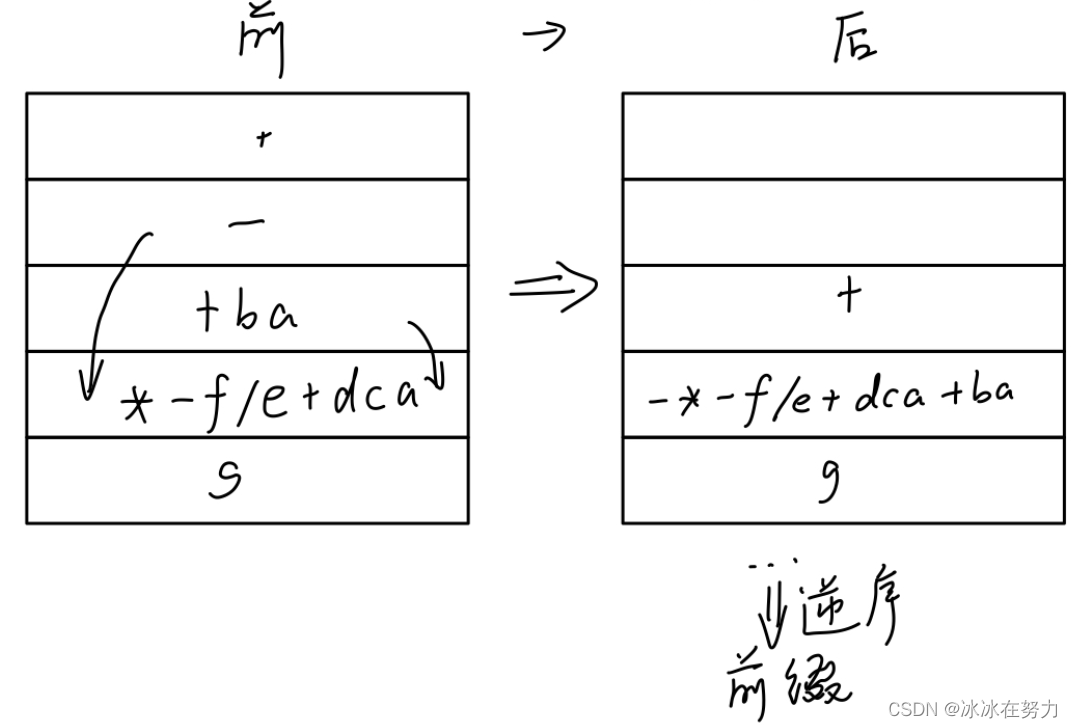
后缀转前缀, 从前到后扫描, 遇到一运算符两子表达式形式则符号前移, 中间表达式后移
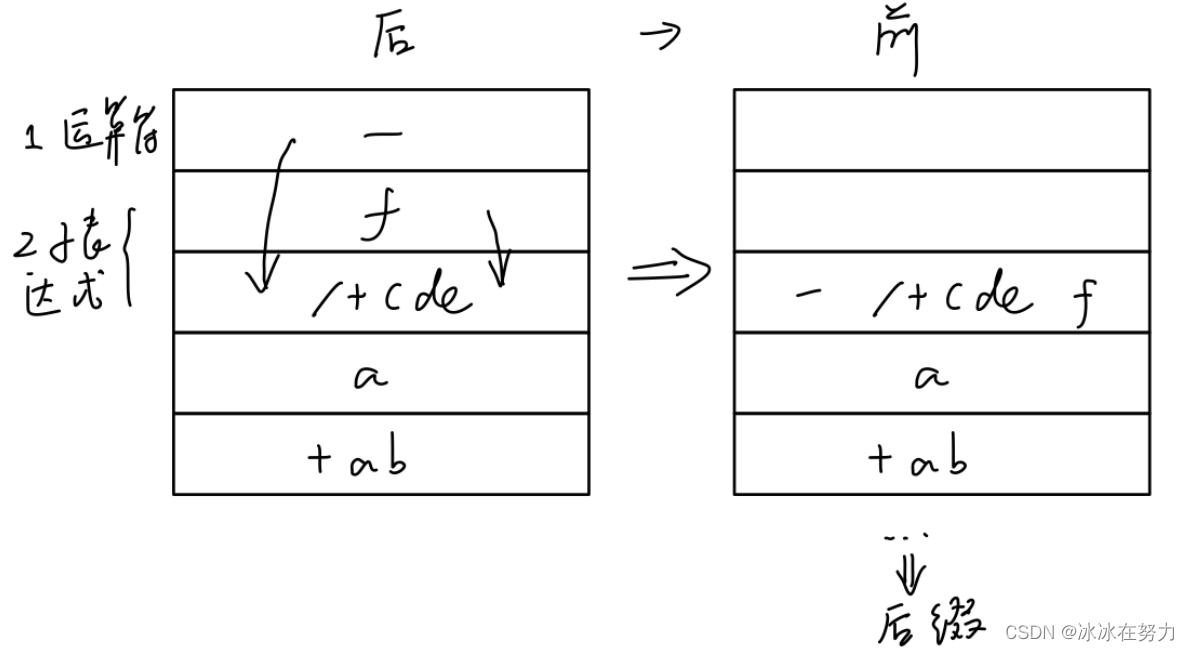
前缀转后缀, 从后到前扫描, 遇到一运算符两子表达式形式同样符号前移, 中间子表达式后移, 最后结果逆序
3.6 递归
3.6.1 递归的定义
在递归调用的过程中,系统为每一层的返回点、局部变量、传入实参等开辟了递归工作栈来进行数据存储
递归过程分为两步“递”和“归”,对应着栈的两种操作“进栈”和“出栈”。
- 程序执行一个函数时,就创建一个新的受保护的独立空间(新函数栈)
- 函数的局部变量是独立的,不会相互影响
- 递归必须向退出递归的条件逼近,否则就是无限递归
- 当一个函数执行完毕,或者遇到 return,就会返回,遵守谁调用,就将结果返回给谁
将递归算法转换为非递归算法,通常需要借助栈来实现这种转换,消除递归并不一定需要栈
3.6.2 递归的应用
- 阶乘
- Fibonacci函数
“兔子数列”,其数值为:1、1、2、3、5、8、13、21、34……
方法定义:
F(0)=1
F(1)=1
F(n)=F(n - 1)+F(n - 2)(n ≥ 2,n ∈ N*)
- Ackerman函数
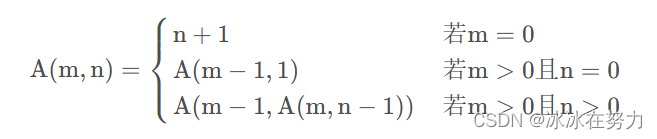
- 猴子吃桃子问题
猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个,第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃前一天剩下的一半零一个。到第10天早上想再吃时,见只剩下一个桃子了。求第一天共摘多少个桃子?
- 汉罗塔问题
给定三根柱子,记为A,B,C,其中柱子上有n个盘子,从上到下编号为0到n-1,且上面的盘子一定比下面的盘子小。问:将A柱上的盘子经由B柱移动到 C柱最少需要多少次?
移动时应注意:
① 一次只能移动一个盘子
②大的盘子不能压在小盘子上
当只有一个盘子时,直接将盘子从A柱子移动到C柱子即可。
当有多个盘子时,可以将问题划分为三个步骤:
- 将上面的n-1个盘子从A柱子移动到B柱子(借 助C柱子)
- 将最底下的一个盘子从A柱子移动到C柱子
- 将B柱子上的n-1个盘子移动到C柱子(借助A柱子)
- 树的遍历
- 树的深度
3.6.3 递归的优缺点
3.6.3.1 递归的优点
- 代码简介
- 便于理解
3.6.3.2 递归的缺点
- 时间和空间消耗大
- 递归次数过多容易造成栈溢
- 效率不高,递归调用过程中包含很多重复的计算
















 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











