






目录
摘要
在《Application of fuzzy time series models for forecasting pollution concentrations》文献中提出使用模糊时间序列模型预测空气污染浓度,该模型将天气等时间序列数据转换为模糊数,以达到更好的污染预测效果。这周对于逻辑回归部分的学习,包括模型的函数构建、决策边界、代价函数、梯度下降推导、过拟合问题。其中回归模型中过拟合问题有多种出现的原因以及解决方法,而将正则化加入到代价函数的优化中,可以在避免过拟合的同时得到使损失最小的最优参数。
Abstract
In the Application of fuzzy time series models for forecasting pollution concentrations, it is proposed to use fuzzy time series models to predict air pollution concentrations. The model converts time series data such as weather into fuzzy numbers to achieve better pollution prediction. This week in the logistic regression part of the study, including model function construction, decision boundaries, cost functions, gradient descent derivation, overfitting problems. There are many reasons and solutions to the overfitting problem in regression models, and regularization can be added to the optimization of cost function to avoid overfitting and get the optimal parameter with the minimum loss.
文献阅读:模糊时间序列模型在污染浓度预测中的应用
title:Application of fuzzy time series models for forecasting pollution concentrations
https://doi.org/10.1016/j.eswa.2012.01.023
研究背景
目前,污染浓度的预测无论从社会角度(包括告知超标情况)还是从工业角度(包括预测研究地区购买单位的消耗量)都起着重要作用。正确预测、实施和使用庞大数据库的模型使正确预测变得更加容易。预测污染浓度的常用方法有:统计模型、基于推理规则的方法、神经网络、时间序列过滤、支持向量机、聚类分析等。这些方法有可能发现集中收集的数据之间的新依赖关系,但近年来,污染浓度预测更多的是基于数据挖掘方法,如何使得所有不精确、混沌、不确定的数据都可以被利用起来,从多方面数据进行预测成为了关键。
研究目的
本文提出的模型的目的是预测任何污染浓度,特别是:PM10, PM2.5, SO2, NO, CO和O3。该模型比大多数模型更好,因为它根据数据之间的时间步长预测了选定的污染浓度。大多数情况下,时间步长等于1小时,但模型也可以用更小或更大的时间步长进行预测,例如10分钟、1小时、1天。此外,模型可以预测未来某一天到另一天的污染情况,条件是我们有该天的天气预报,例如从2010年1月27日开始的48小时的污染预报,时间步长为1小时。为了做出这个预测,我们需要从2010年1月27日开始的天气预报,以及未来48小时的天气预报,最好使用相同的时间步长。
创新点
1、将时间序列转换为模糊数算法(SFN)
本文提出预测PM10、PM2.5、SO2、NO、CO和O3等颗粒物浓度的模型。该方法需要大量时间点的历史数据,特别是天气预报数据、实际天气数据和污染数据。通过将预报数据与历史数据集中类似的预报数据相匹配,就有可能获得实际的天气数据,并通过这些得到污染数据。
为了将由距离函数确定的预报数据相似的时间点聚集在一起,从预报数据生成模糊数,包括预报数据和实际数据。将序列转化为模糊数的算法分为两步,第一步将数列转化为离散模糊数,第二步将离散模糊数转化为隶属函数定义形式的模糊数。
2、空气污染预测模型(APFM)
该模型在拥有当日天气预报的情况下,可以预测任何选定日(通常为翌日)或数小时的污染浓度,例如微粒PM10、PM2.5、SO2、NO、CO、O3等。APFM模型首先对天气预报进行分组,然后将选定的气象情况转化为模糊集。其次,用模糊数的形式描述模糊集。然后用模糊分组法得到一组污染浓度。最后,采用标准化的方法,得到了空气质量形势预报。
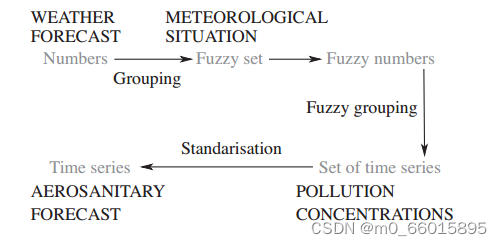
APFM模型分为以下步骤:
- 数据准备:输入数据包括时间范围、时间步长、气象数据数据库、选择我们将进行污染浓度预测的日期。输出数据包括天气预报集、气象情况集、污染浓度集。
- 定义一组相似的天气预报。输入为步骤1得到的天气预报集,输出为一组相似的天气预报集。
- 定义类似气象情况的子集。输入为步骤1的气象情况集和步骤2的天气预报集,输出为一组类似步骤1的气象情况集的子集。
- 定义气象情况子集的模糊数。输入为步骤3的输出,输出为气象情况子集的模糊数。
- 确定气象情况子集与模糊数的隶属等级,并定义相似气象情况的集合。输入为步骤4的气象情况子集的模糊数和步骤1的气象情况集。
- 定义一组类似的空气质量情况。输入为步骤5得到的权重以及步骤1的污染浓度集。
- 计算预测输出。输入为步骤6得到的空气质量情况以及步骤5的权重,输出为预测污染浓度:平均值(ua),最大值(um), a-标准化(ug), ab-标准化(uh)。
研究实验
1、数据集
COSMO LM模型的天气预报数据集,包括气压、风速、风向、地面温度、不同海拔高度温度、云量、地雾、降雨量、降雪量。 气象情况数据集,包括云量、风速、站位气压、2米高度温度、水汽压、湿度。污测量的染浓度数据集包括PM10。实验使用的天气预报从2002年1月开始收集,气象情况从2004年1月开始收集。在波兰,有15个地区进行测量。从各种数据集中收集气象数据,然后对其进行适当安排(模型的第1步),并对所有天气预报进行归一化。
2、误差测量
误差表示观测值与预测值之间的差值。误差测量采用波段误差法,将PM10的取值范围分为七个波段。PM10波段为[1,54]、[55,154]、[155,254]、[255,354]、[355,424]、[425,504]、[505,604]。选择这种间隔系统是因为它是空气质量报告的首选方法。例如,在波段误差法中,PM10的实际和预报对(54,55)被报告为+1波段,因为54属于第一个区间,55属于第二个区间。
3、实验结果
利用APFM模型对污染浓度PM10进行了模拟实验。实验为期365天。APFM模型的时间范围设为T = 36 h,时间步长设为Dt = 1 h。比较了大气污染指标波段的观测值和预测值,报告了出现错误的日子。
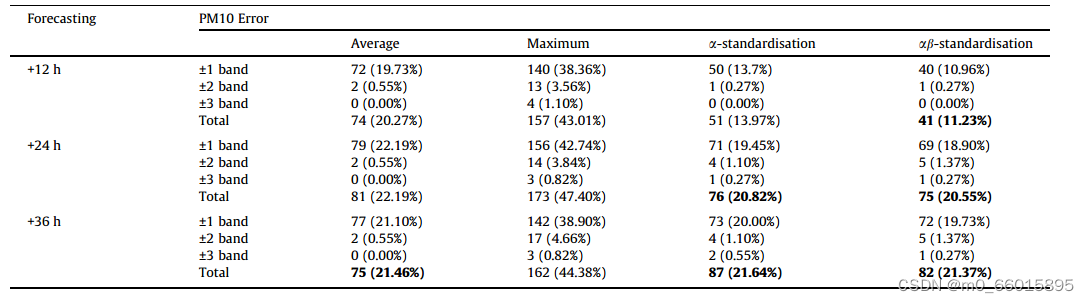
采用平均法预测PM10时,+12、+24和+36 h的误差分别为20.27%、22.19%和21.46%。结果表明,+12 h预测效果最佳,每12 h误差分布(±1、±2、±3个波段),最大误差在+12、+24、+36 h分别为43.01%、47.40%、44.38%。采用a-标准化方法,+12、+24和+36 h的误差分别为13.97%、20.82%和21.64%。最后,采用ab-标准化方法,+12、+24和+36小时的误差分别为11.23%、20.55%和21.37%。因此可以得出+12 h预报效果较好,但±1波段范围包含了大部分误差。预测未来12小时PM10的最佳方法是ab-标准化方法。预测未来12 - 24小时PM10的最佳方法是:a-标准化和ab-标准化方法。并对PM10进行24-36 h的预报,误差的最低值可以在平均值法、a-标准化法、ab-标准化法取得。
研究贡献
本文提出了预测PM10、PM2.5、SO2、NO、CO和O3等颗粒物浓度的模型,该模型的建立使得所有不精确、混沌、不确定的数据都可以被利用。在波兰,气象研究所和水管理研究所以及省环境保护监察员都在使用该模型。它预测了波兰所有地区的选定污染浓度。
逻辑回归
逻辑回归函数
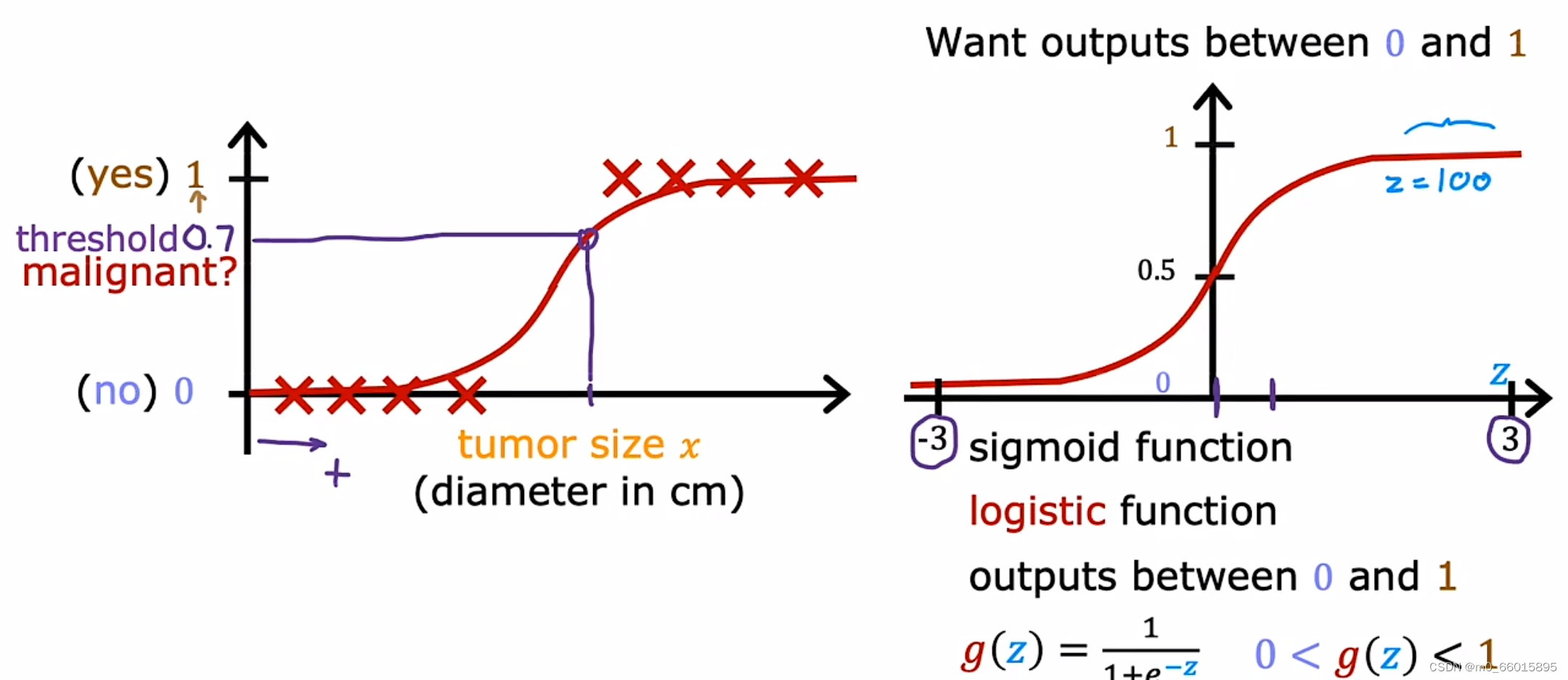
对于肿瘤分类问题,在数据集图表上,水平轴代表肿瘤的大小,垂直轴仅取值0和1,而显然线性回归无法去拟合这样的数据集,而选用逻辑回归解决分类问题,实际是拟合一条看起来像S形的曲线。对于这个例子,肿瘤的大小取值是一个连续的范围值,例如选取一个X值对应的算法输出为0.7,表明它接近或更可能是恶性,但输出标签只有0和1,为了构建逻辑回归算法,会用到一个重要的数学函数,即Sigmoid函数,有时也成为逻辑函数。Sigmoid函数的输出值是介于0到1之间,当很大的时候,
的值将非常接近1。
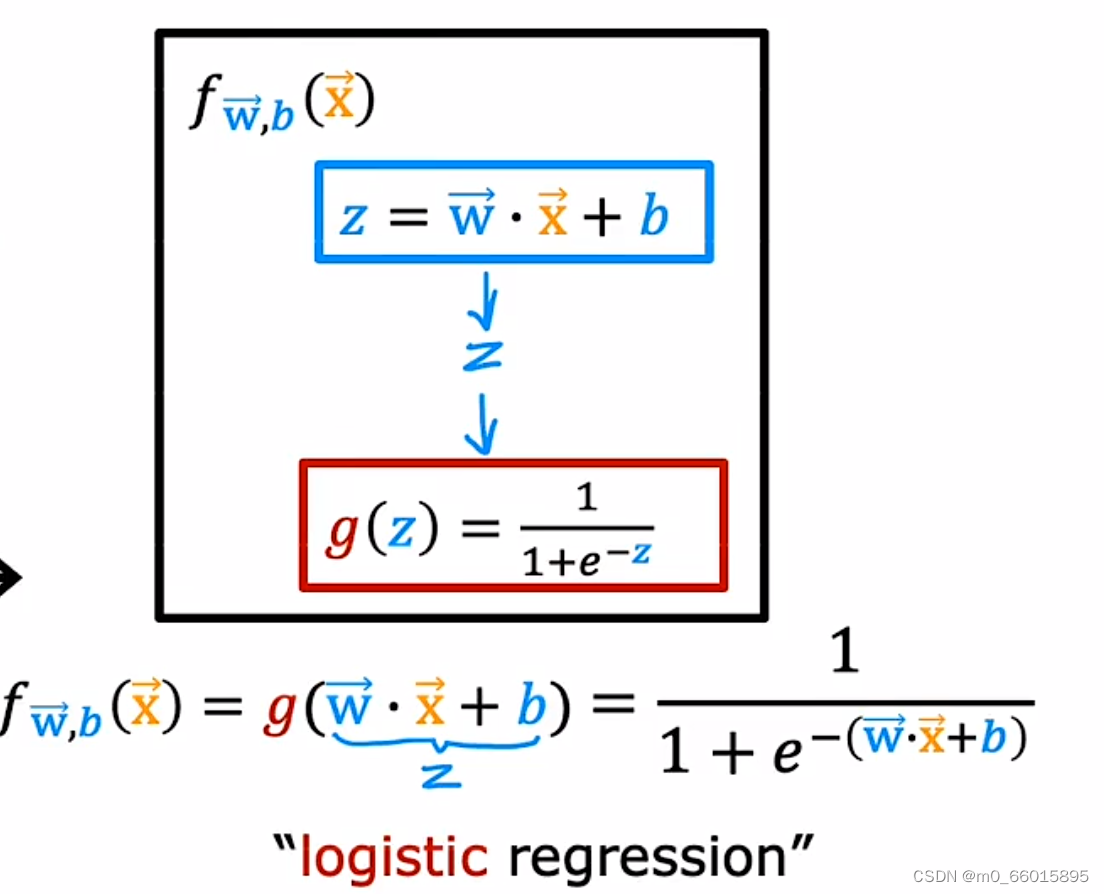
使用Sigmoid函数构建逻辑回归函数可以分为两步,第一步:定义一个类似于线性回归函数的直线函数,即。第二步:获取
的值,并将其传递给Sigmoid函数,得到
的值,即一个0到1范围的数值。将这两步结合即得到逻辑回归函数
。
Q:如果输入X值的输出为0.7,在逻辑回归中我们可以理解为它有70%的可能是属于1标签的。我们知道输出值必须为0或1,如果y有70%的机会为1,那么它为0的机会有多大呢?
A:因为y必须是0或1,那么这两个数字为0或1的概率必须相加为1或100%的概率,即
。因此y为1的概率为70%,那么它为0的概率必须为30%
如何将模型输出的非0或1的数值映射到预测y实际是0还是1呢?在预测中,需要假设在什么情况下预测的概率为1或者为0。如果预测值也就是时,也就是
,可以看出在sigmoid函数中,当z为0的时候,取值正好是0.5。如果我们判断
时属于标签1,
时属于标签0,那么就可以把z>=0和z<0作为判断的标准,z对应wx+b。这就是决策边界的问题

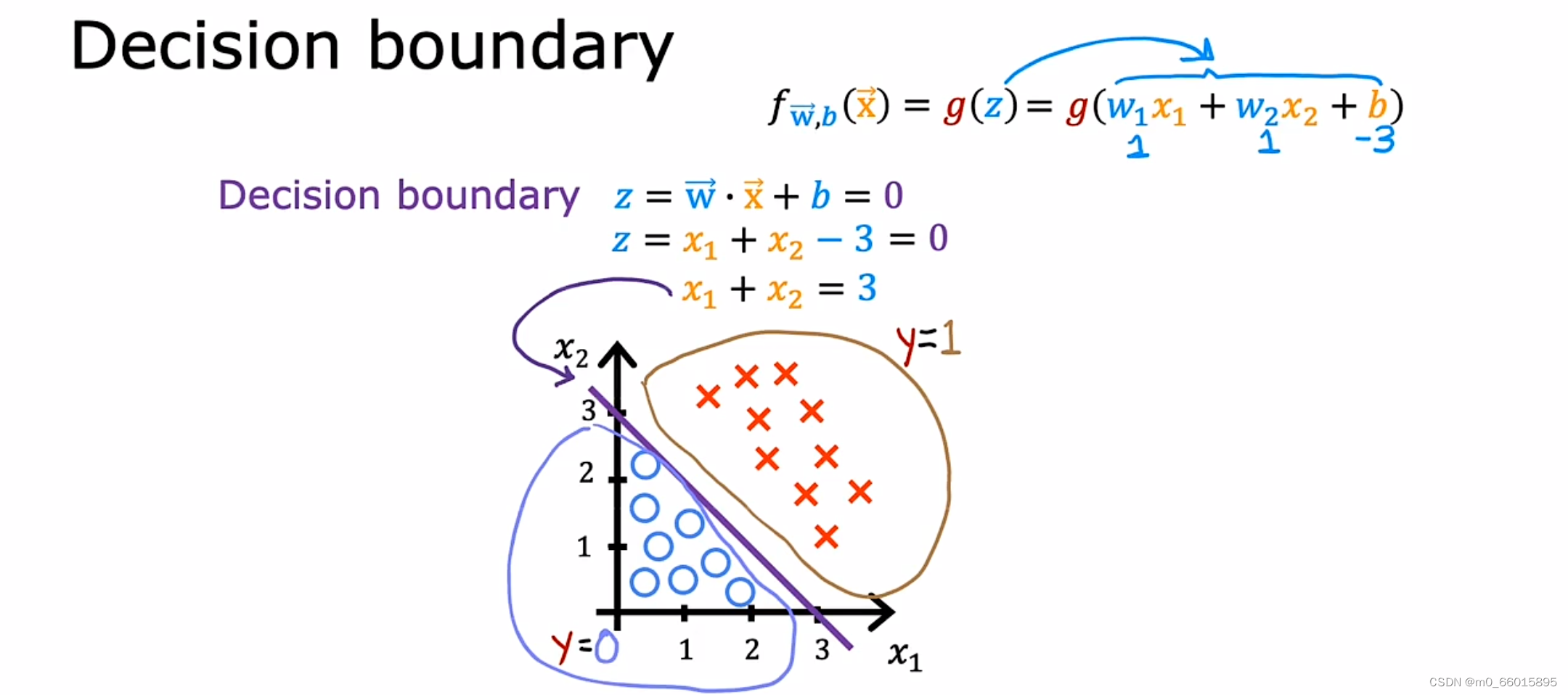
决策边界
1.直线
假设逻辑回归函数有两个特征,设定w1和w2都为1,b为3,通过计算可得到直线方程,这就是决策边界,可以看出通过这条直线将划y=0和y=1两种情况划分开来,其中红色×代表1,蓝色●代表0,因此当预测值落在决策边界上方则可以判定其属于y=1的情况,落在决策边界下方则可以判定其属于y=0的情况。
2.曲线
不同的参数将得到不同的决策边界。对于更加复杂的例子,决策边界则不再是一条直线。例如使用多项式特征时,得到的决策边界则是曲线。使用这些多项式特征,可以获得非常复杂的决策边界,也就是说逻辑回归可以拟合非常复杂的数据。

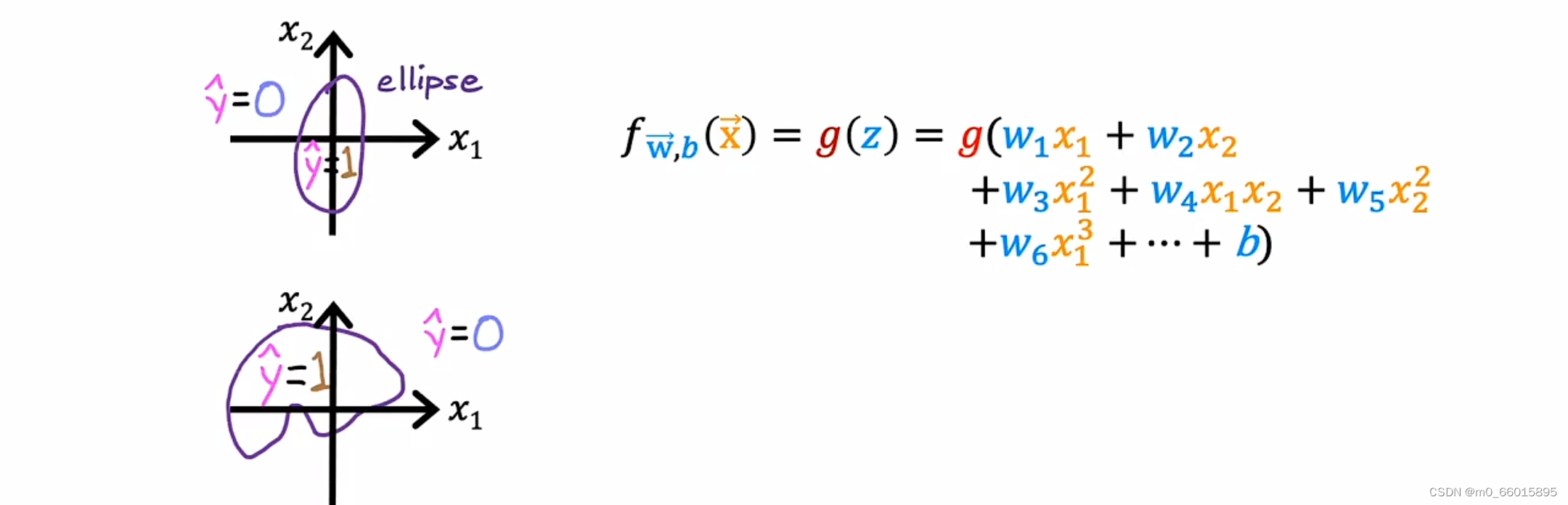
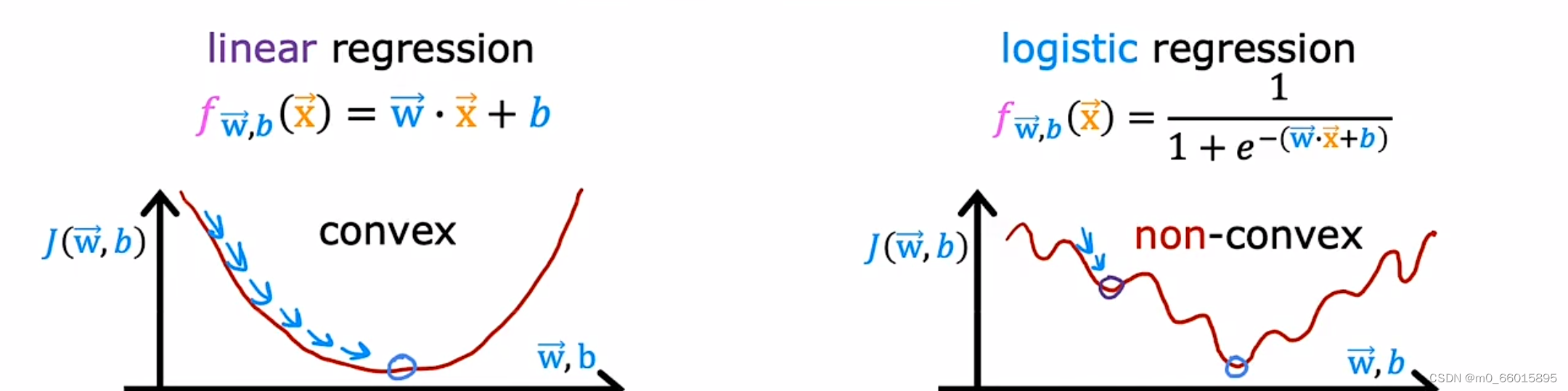
逻辑回归代价函数
回顾线性回归方程定义的代价函数是所有模型误差的平方和,得到的图像是一个凸函数或者碗形,通过梯度下降一步一步可以得到一个全局最小值。理论上来说,我们也可以对逻辑回归模型沿用这个定义,但是问题在于,当我们将Sigmoid函数带入到定义的代价函数中时,我们得到的代价函数将是一个非凸函数(non-convexfunction)。这就意味着如果使用梯度下降,则会有很多局部最小值,就会被卡住无法继续下去,因此对于逻辑回归函数来说平方误差并不是一个好的选择。
代价函数与损失函数
将线性回归的代价函数改写为蓝框内的形式 (即把1/2提到后面去),蓝框内的公式则刚好是逻辑回归的cost function。

代价函数只是平均损失,是m个样本的整个训练集的平均值,所以它是从样本1到m的损失总和再除以m。上图蓝框的损失函数 loss function 是在一个训练样本的表现,把所有训练样本的损失加起来得到的代价函数 cost function,才能衡量模型在整个训练集上的表现。
逻辑回归的损失函数
我们把逻辑回归的损失函数定义为两种对数函数,分别为y=0和y=1两种情况。
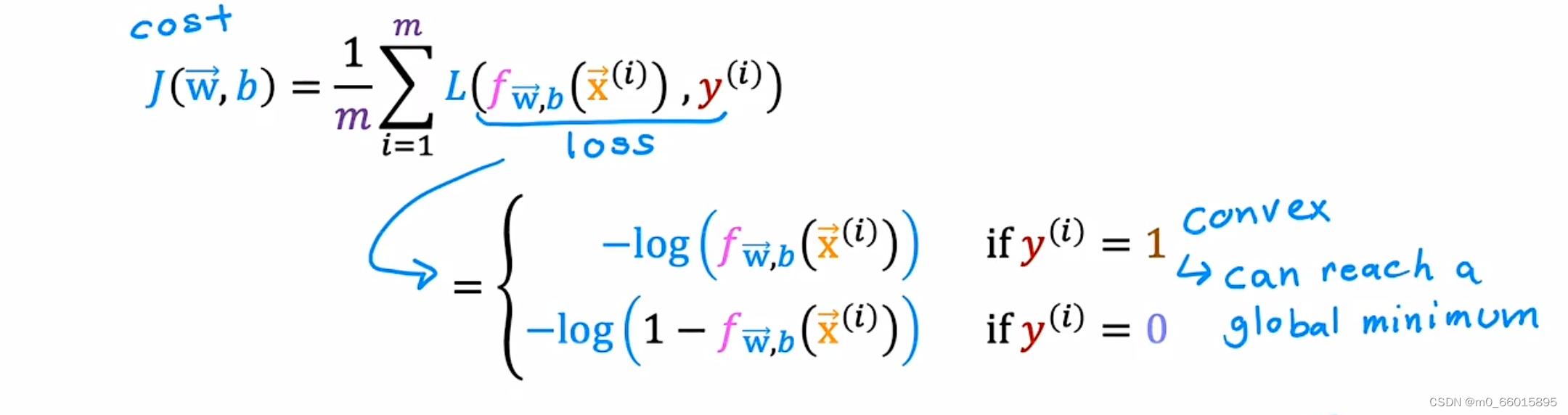
首先研究第一个对数函数,预测y=1时的损失函数。因为逻辑回归函数fw, b(x)的输出总是在0和1之间(因为f(x)其实是g(z),它的函数形式是一个Sigmoid函数,限制了f(x)输出在0到1之之间),所以可以画出损失函数f取值是0到1之间的一部分图像。(如下左图所示,把横坐标0到1间的函数图像拿出来)。当的值趋向于0的时候,这是loss的值趋向于无穷大,说明损失函数很大;当
的值为1的时候,这时loss为0,也就是说这个损失函数保证了当预测值是1的时候,损失是最小的。我们训练的目的是让损失函数最小,如果这个损失函数较大的话,模型就大概率不会把它预测为1。
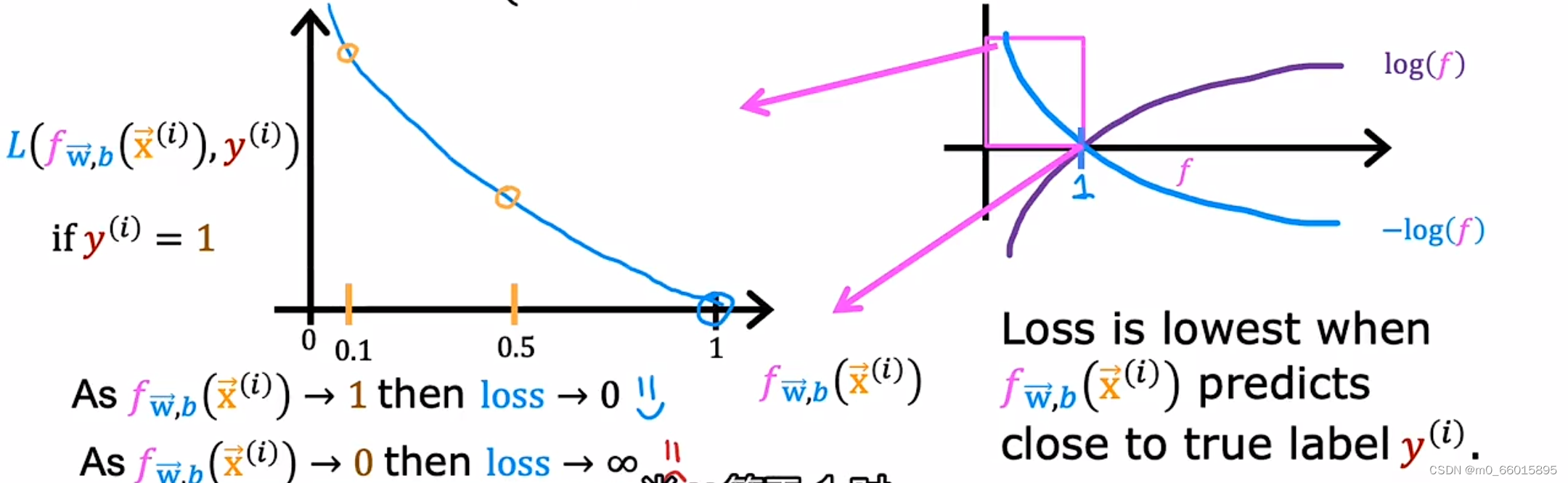
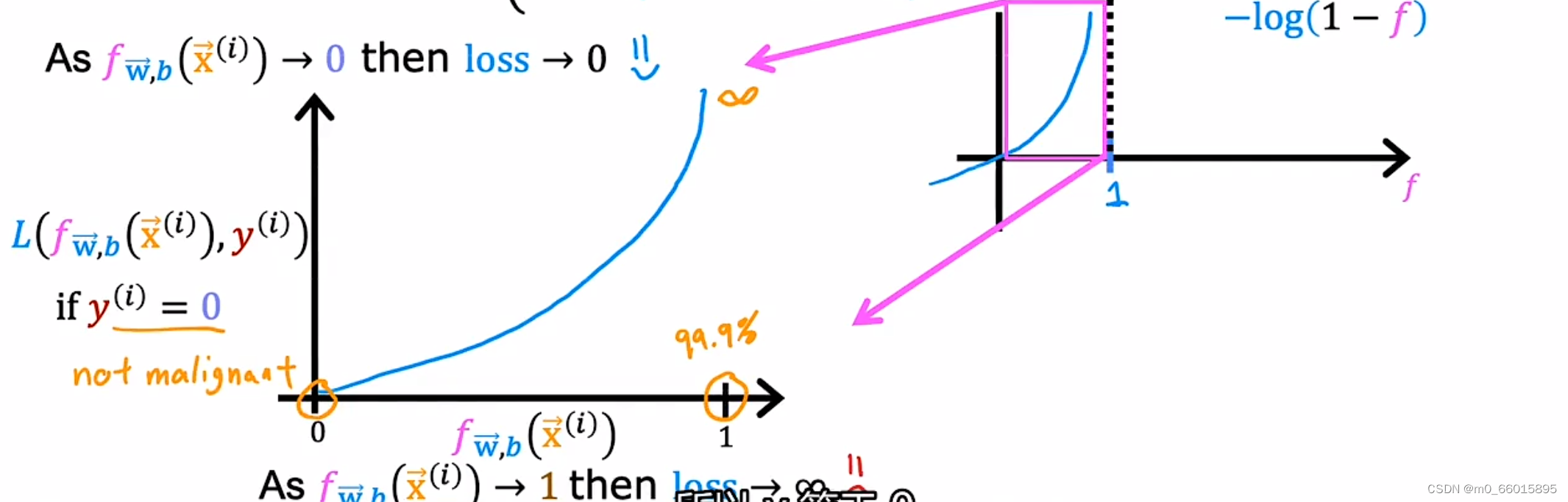
同理可知,在y=0的情况下,当的值趋向于1的时候,这是loss的值趋向于无穷大,说明损失函数很大;当
的值为0的时候,这时loss为0,也就是说这个损失函数保证了当预测值是0的时候,损失是最小的。我们训练的目的是让损失函数最小,如果这个损失函数较大的话,模型就大概率不会把它预测为0。
简化代价函数
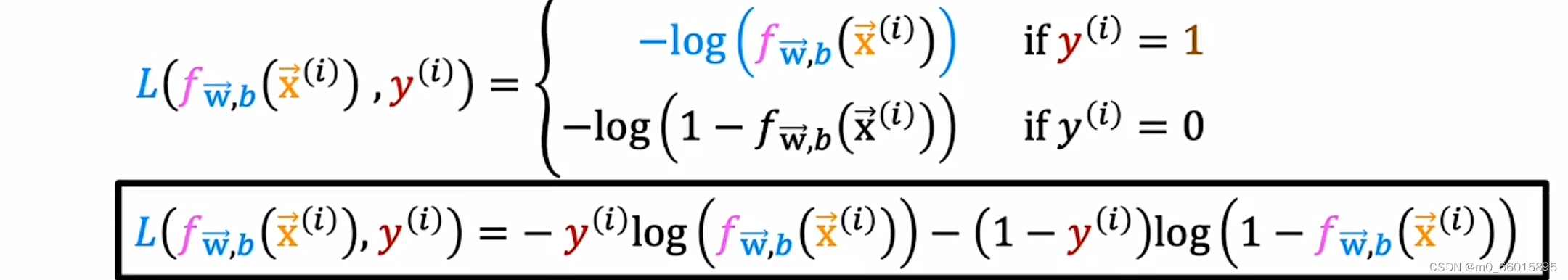

对于为什么会选择这个作为逻辑回归的代价函数这个问题,因为这个代价函数是使用最大似然估计的统计原理从统计中推导出来的。它可以将原本逻辑回归代价函数从非凸函数变成凸函数,可以保证梯度下降收敛到局部最小值。
逻辑回归的梯度下降
为了拟合出逻辑回归的模型,需要找出最佳的和
让代价函数
的值最小。采用梯度下降求逻辑回归函数代价函数最小值时,同样首先利用
分别对
和
求导,然后再更新
和
的值,经过推导可以发现,
对
和
的偏导公式与线性回归中的偏导公式一模一样。

逻辑回归梯度下降求导公式推导:

逻辑回归的梯度下降看似与线性回归的梯度下降相同,但本质不同,因为他们的函数原型是不一样的,只是推导出的最终结果恰好一样。在Function Set中,Logistic Regression模型是在Linear Regression基础上进行Sigmoid Function,因此它的值一定是介于0到1之间的。而Linear Regression的值可以是任何值。

因此,即使更新参数的规则看起来基本相同,但由于假设的定义发生了变化,所以逻辑函数的梯度下降,跟线性回归的梯度下降实际上是两个完全不同的东西。
过拟合
什么是过拟合
在训练一个模型时我们需要用到很多特征,通过学习得到的模型可能能够非常好地适应训练集(代价函数可能几乎为 0),但是将这个训练得到的模型应用到其他新的数据集上进行预测往往却得不到理想的结果。
过拟合:训练集中错误率很低,但是验证集中错误率比验证集中高很多,方差很大。
欠拟合:训练集中错误率相对比较高,但是验证集的错误率和训练集中错误率差别不大,偏差很大。
偏差和方差都很大: 如果训练集得到的错误率较大,表示不能很好的拟合数据,同时验证集上的错误率甚至更高,表示不能很好的验证算法.这是偏差和方差都很大的情况.
较好的情况:训练集和验证集上的错误率都很低,并且验证集上的错误率和训练集上的错误率十分接近。
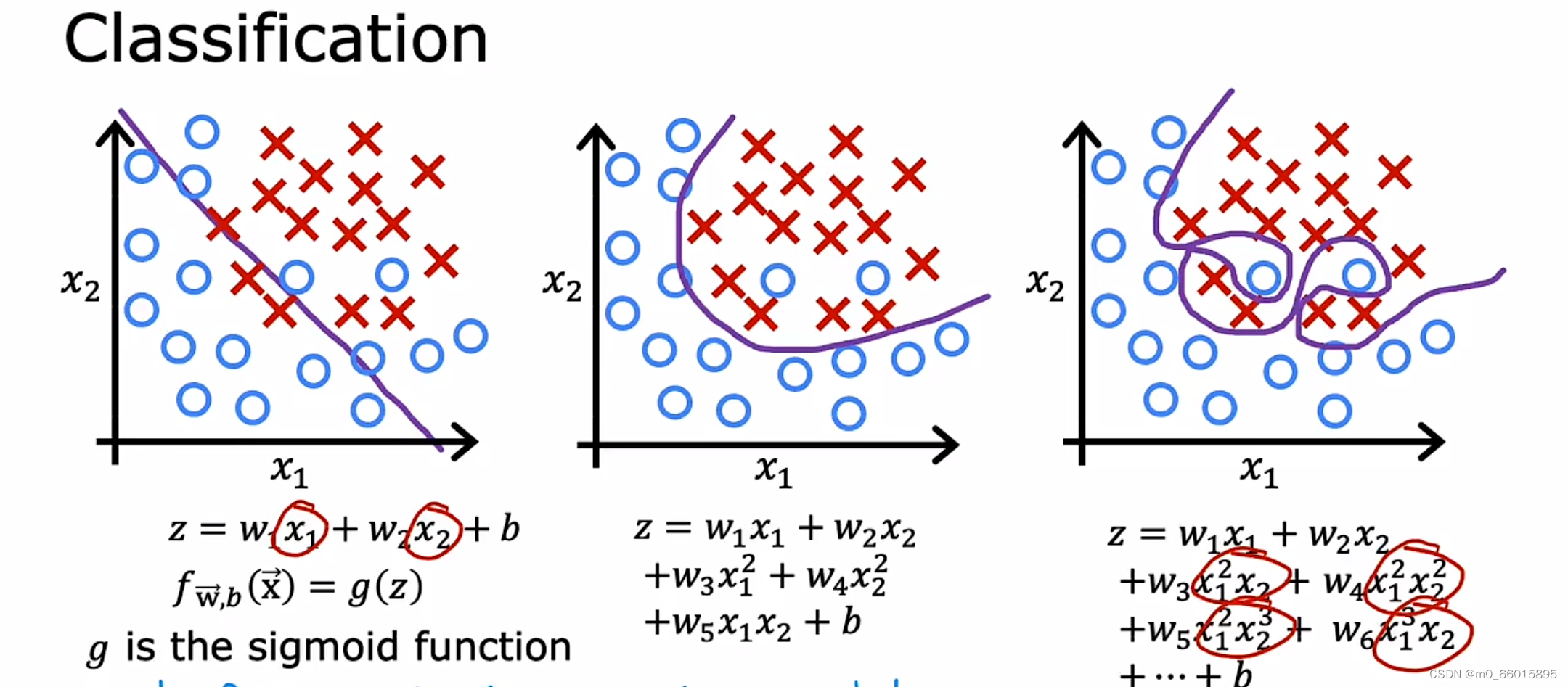
对于线性模型来说,例如图1所示,拟合程度比较低,连训练集的准确率如此低,那么测试集肯定也不高,也就是模型的泛化能力不高在欠拟合的情况下。而在过拟合情况下例如图3,拟合程度非常高,但这并不是合适的,我们的数据集中无法避免的存在着许多噪声,而在理想情况下,我们希望噪声对我们的模型训练的影响为0。而如果模型将训练集中每一个点都精准描述出来,显然包含了许许多多噪声点,在后续的测试集中得到的准确率也不高。另一方面,太过复杂的函数直接导致函数形状并不平滑,而会像图中那样拐来拐去,并不能起到预测的作用,“回归”模型也丧失了其预测能力(也就是模型泛化能力),显然这也不是我们想要的。
图2展现的是最适合的拟合程度,函数不过于复杂或过于简单,并且能够直观的预测函数的走向。虽然它在测试集的中准确列不及图三高,但在测试集中我们得到的准确率是最高的,同时泛化能力也是最强的。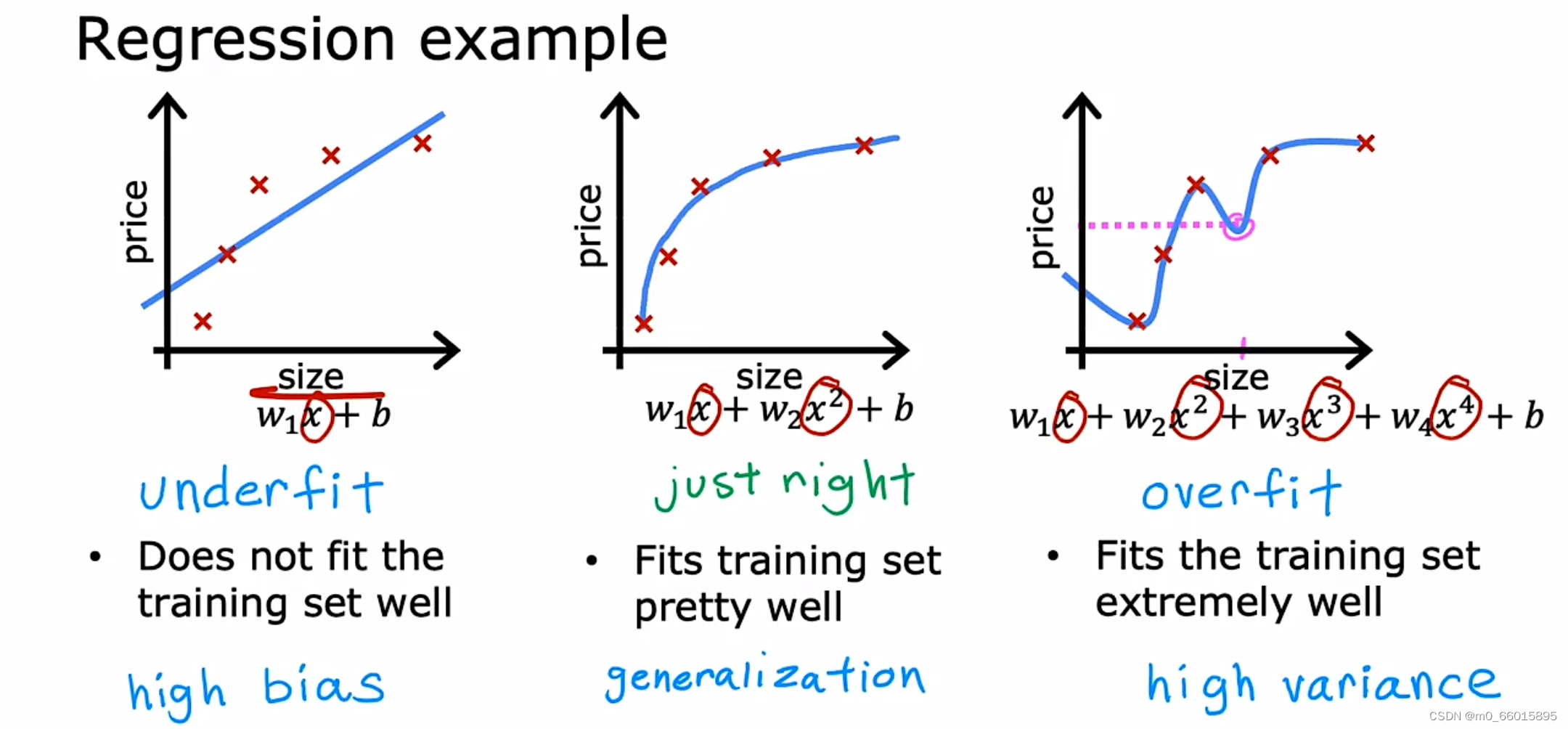
对于逻辑回归模型,分类问题也存在过拟合和欠拟合问题。根据决策边界画出分割线。就以多项式理解,𝑥 的次数越高,拟合的越好,但相应的预测的能力就可能变差。
解决过拟合的方法
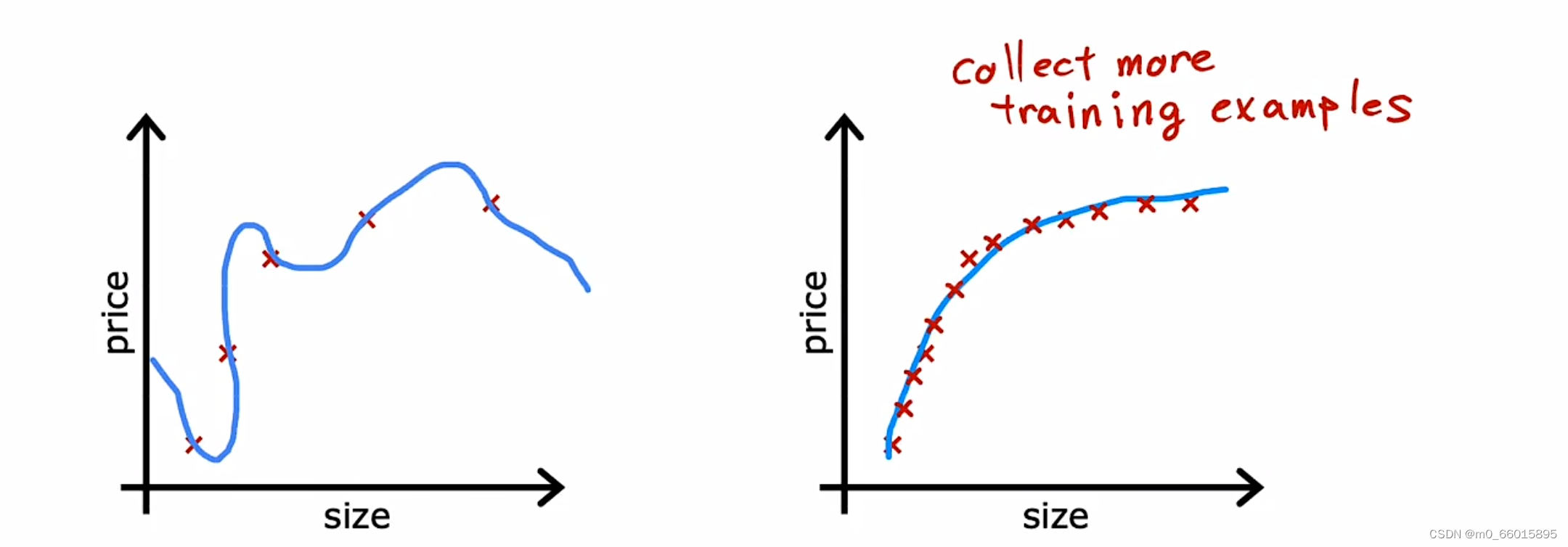
一、增大训练数据集
获得更多的数据可以训练出更加适合的模型,在一定程度上可以对抗过拟合,但是这并不一定总是有效的,因为很多实际情况并没有那么多的训练数据。
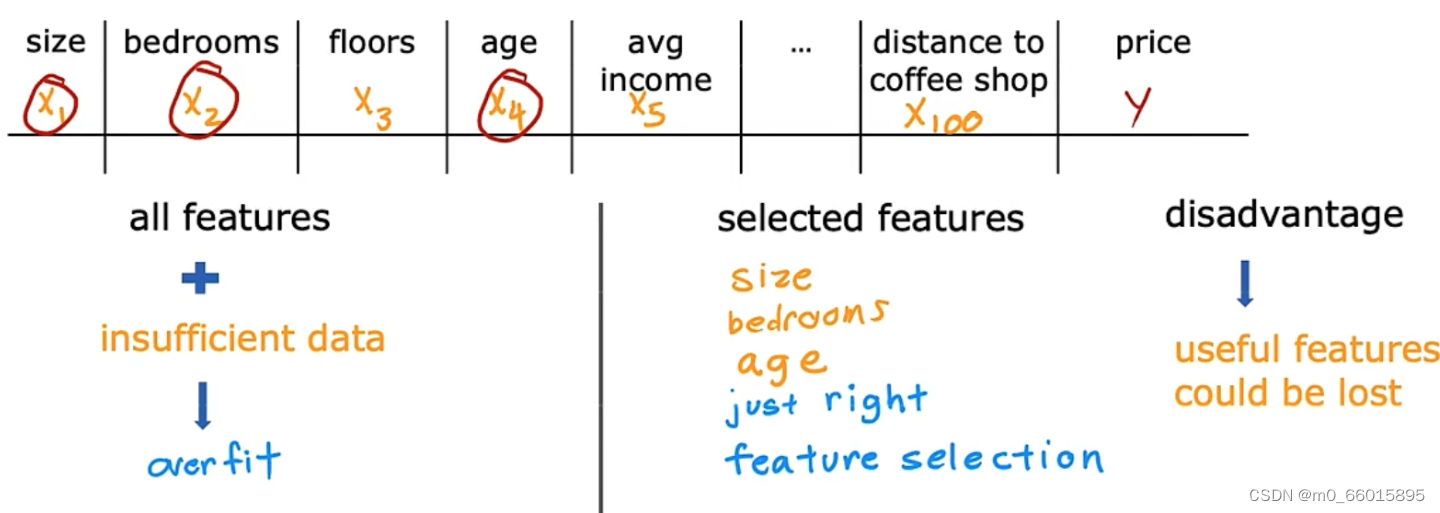
二、特征选择(即减少特征数量)
第二种方法是减少特征的选择,如果使用全部特征(此时可能会用高阶多项式来拟合)再加上不足够的数据,就可能会出现过拟合。如果选择部分最符合的特征,会带来不错的效果。但是但大部分特征都比较重要的时候,就会导致一些重要特征被丢弃。
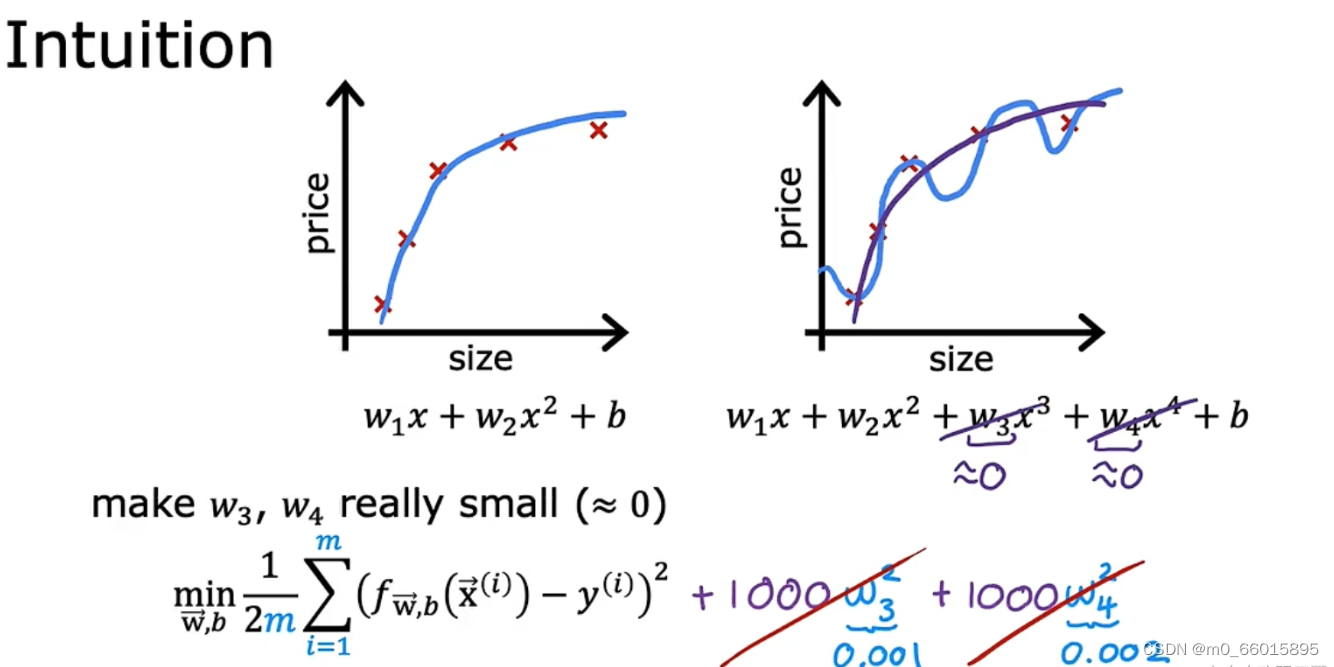
三、使用正则化减少参数的大小
在第二种方法中,我们是直接去掉某些特征(把参数w设置为0),那么这样会导致我们缺少对信息的一些了解。因此对于那些不重要的特征,我们可以把这个特征的参数尽可能减少以防止对模型有过大的影响(例如把w参数设置为0.0001),而不是直接去掉该特征。
正则化
从模型的过拟合例子中可以看出,很多情况下高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于 0 的话,我们就能很好的拟合了。
我们在方程中增加了两个限制条件,分别对和
进行限制,不能让他们过高。很直观的看出,要想使
最小化,不仅仅需要
足够拟合
,同时还需要减少
和
的值。一方面要使得L(w)的取值最小,必然w的绝对值会取到很大,这样模型才能完美拟合训练样本点;另一方面,当w的绝对值很大时,||w||的值又会变得很大,因此为了权衡,只有使得w取值适当,才能保证值取到最优。这样得到的拟合曲线平滑很多,因此具有泛化能力。这就是正则化存在的意义,能帮助我们在训练模型的过程中,防止模型过拟合。
怎么对模型做正则化?
假如我们现在有100个特征,我们可能不知道哪些特征是最重要的,哪些特征不那么重要,因此不知道惩罚哪个能获得更好拟合的结果,正则化的典型实现方式是惩罚所有的特征,或者说是惩罚所有的参数。

使用统一的正则化参数而不是针对每个特征使用不同的参数,有以下原因:
1. 简化模型:使用统一的正则化参数可以简化模型的训练和推断过程,统一的正则化参数使模型更简单,减少了参数数量和计算负担。
2. 特征相关性:不同特征之间可能存在相关性。如果针对每个特征使用不同的正则化参数,这可能会导致参数之间的不一致性。
3. 公平性:使用统一的正则化参数可以确保模型对所有特征都有相似的约束力度。
4. 超参数调整:使用统一的正则化参数使得模型的超参数调整更加简单。如果为每个特征使用不同的正则化参数,那么模型将有更多的超参数需要调整,增加了调优的难度。而统一的正则化参数只有一个超参数,更易于优化和选择。
引入正则化项,统一惩罚参数以得到较为简单的函数。统一惩罚能得到简单结果是因为,受到同样的惩罚,相对于低阶项而言,高阶项的惩罚效果会更强,反映在图像上就是其影响被削弱得更明显。
因此将正则化加入代价函数中,第一项是平方误差项,第二项为正则化项,其中 λ称为正则化参数(Regularization Parameter),当参数越大,则对其惩罚(规范)的力度也就越大,越能起到规范的作用。但是要注意,λ并不是越大越好的!有时候也会把b的惩罚加进来,但是大部分情况下只有w。第一项的平方误差是为了更加拟合数据集。第二项 Regularization term,即想要参数尽量小。
对于正则化参数λ 大小设置问题,从两个极端例子来看:
1. 若 λ 设置为0,相当于没有进行正则化,容易出现过拟合。
2. 若 λ 设置为很大的值(例如10的10次方),即对参数得的惩罚程度过大,导致每一项都接近于0,最后假设模型只剩一个f(x) = b,则会出现欠拟合情况。
因此对于正则化,我们要取一个合理的 𝜆 的值,这样才能更好的应用正则化选择拟合的模型。
用于逻辑回归的正则方法
机器学习中经常会在损失函数中加入正则项,称之为正则化(Regularize)。它是为了防止模型过拟合,它的原理是在损失函数上加上某些规则(限制),使参数尽可能地小,从而减少求出过拟合解的可能性。对于逻辑回归,我们也给代价函数增加一个正则化的表达式,得到代价函数:
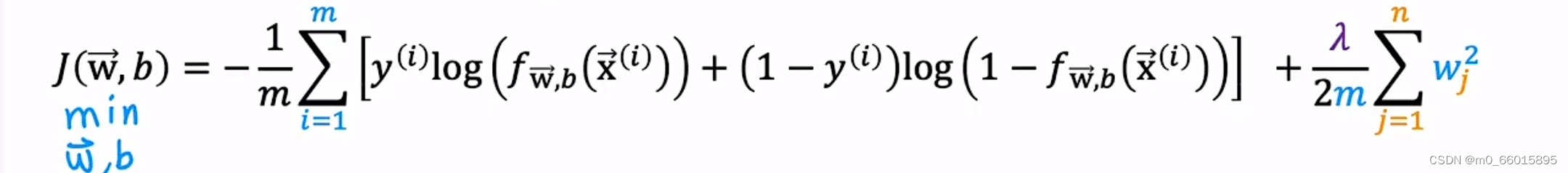
正则化之后的梯度下降算法:
代价函数的极小值点本质上就是
的最终收敛结果,因此在后面添加正则化项后,为了使代价函数取值较小就只能把相应的w值减小,添加正则化项后,代价函数对w的偏导即
变大,所以w更新时,
,因此最终呈现的结果就是w变小了。
逻辑回归的梯度下降实现
使用两个特征数据集,其中X_train代表特征值和y_train代表输出标签,绘制此数据。带标签的数据点y=1示为红叉,而带有标签的数据点y=0显示为蓝色圆圈。
X_train = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y_train = np.array([0, 0, 0, 1, 1, 1])
#绘制数据集的图像
fig,ax = plt.subplots(1,1,figsize=(4,4))
plot_data(X_train, y_train, ax)
ax.axis([0, 4, 0, 3.5])
ax.set_ylabel('$x_1$', fontsize=12)
ax.set_xlabel('$x_0$', fontsize=12)
plt.show()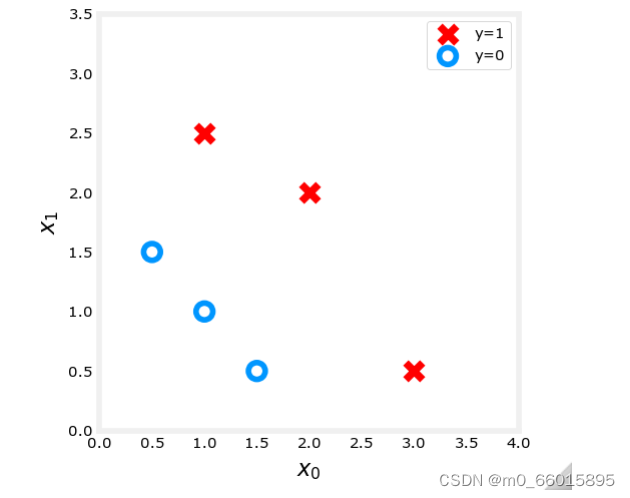
计算代价函数对参数w和b的偏导
(1)
(2)
def compute_gradient_logistic(X, y, w, b):
m,n = X.shape
#初始化变量dj_dw和dj_db,用以保存代价函数对参数w和b的偏导值
dj_dw = np.zeros((n,))
dj_db = 0.
#其中m为样例数,计算每个样例的误差值
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b) #逻辑回归函数f(w,b)=sigmoid(wx+b)
err_i = f_wb_i - y[i] #误差:f(w,b)-y
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j] #计算累计和
dj_db = dj_db + err_i
dj_dw = dj_dw/m #累计和除以样例数,得公式(1)
dj_db = dj_db/m #累计和除以样例数,得公式(2)
return dj_db, dj_dw
更新参数w和b的值,公式为
(1)
(2)
def gradient_descent(X, y, w_in, b_in, alpha, num_iters):
J_history = [] #保存代价函数的历史值
w = copy.deepcopy(w_in)
b = b_in
#num_iters为迭代次数
for i in range(num_iters):
# 计算梯度并更新参数
dj_db, dj_dw = compute_gradient_logistic(X, y, w, b)
w = w - alpha * dj_dw
b = b - alpha * dj_db
# 在每次迭代后保存J的值
if i<100000:
J_history.append( compute_cost_logistic(X, y, w, b) )
return w, b, J_history 将数据集X_train和y_train 进行梯度下降,得到使得代价函数最小的w和b,即w_out, b_out。
w_tmp = np.zeros_like(X_train[0])
b_tmp = 0.
alph = 0.1
iters = 10000
w_out, b_out, _ = gradient_descent(X_train, y_train, w_tmp, b_tmp, alph, iters)
print(f"\nupdated parameters: w:{w_out}, b:{b_out}")
绘制梯度下降结果,包括原始数据集和决策边界
其中w为[5.28 5.08],b为-14.2224,带入
得决策边界直线,其中x0 = -b_out/w_out[1],x1 = -b_out/w_out[0]。
fig,ax = plt.subplots(1,1,figsize=(5,4))
# plot the probability
plt_prob(ax, w_out, b_out)
#绘制原始数据集
ax.set_ylabel(r'$x_1$')
ax.set_xlabel(r'$x_0$')
ax.axis([0, 4, 0, 3.5])
plot_data(X_train,y_train,ax)
#绘制决策边界
x0 = -b_out/w_out[1] #计算横轴坐标值
x1 = -b_out/w_out[0] #计算纵轴坐标值
ax.plot([0,x0],[x1,0], c=dlc["dlblue"], lw=1)
plt.show()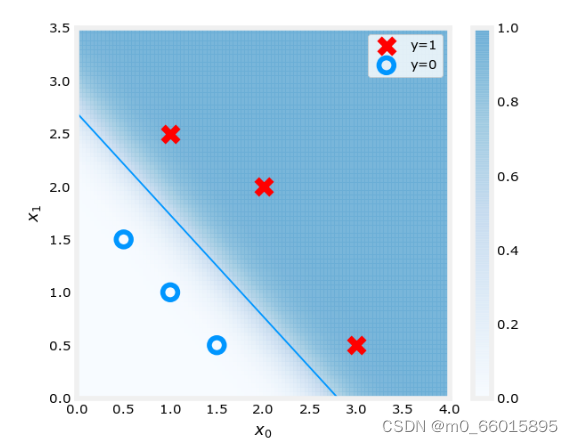
总结
这周学习了监督学习中用以处理分类问题的逻辑回归,与线性回归模型不同的是,逻辑回归函数是在线性函数的基础上加上了逻辑函数,即sigmoid函数,将模型的输出控制在0到1之间,因此更适合用来处理分类问题。在采用梯度下降寻找代价函数最小值的适合,发现逻辑回归的梯度下降看似与线性回归的梯度下降相同,但是它们的本质不同,因为他们的函数原型是不一样的,只是推导出的最终结果恰好一样。不管使用线性回归模型还是逻辑回归模型,在拟合数据集的适合都存在过拟合的问题。















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









