







首先是参加项目
打开pycharm后点开命令行,
scrapy startproject Qidiancd Qidian
scrapy genspider qidian qidian.com然后打开qidian.py
把start_url修改成我们开始爬的地址
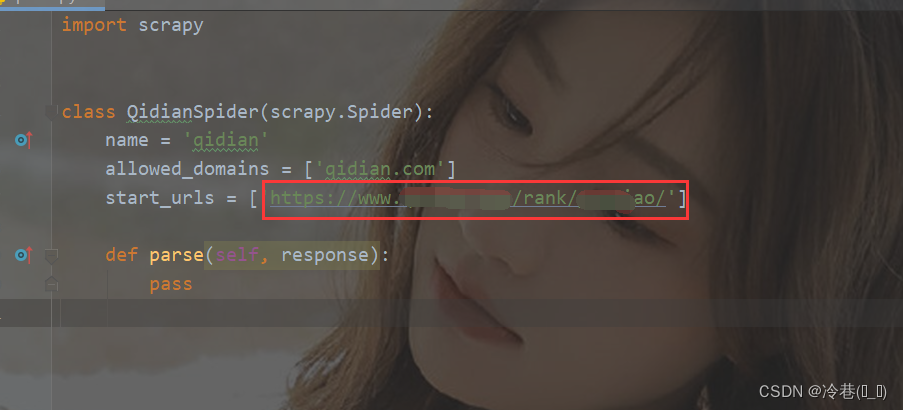
下面的def修改为
def parse(self, response):
print(response.text)
然后新建一个py文件,
from scrapy.cmdline import execute
execute('scrapy crawl qidian'.split())
右键运行
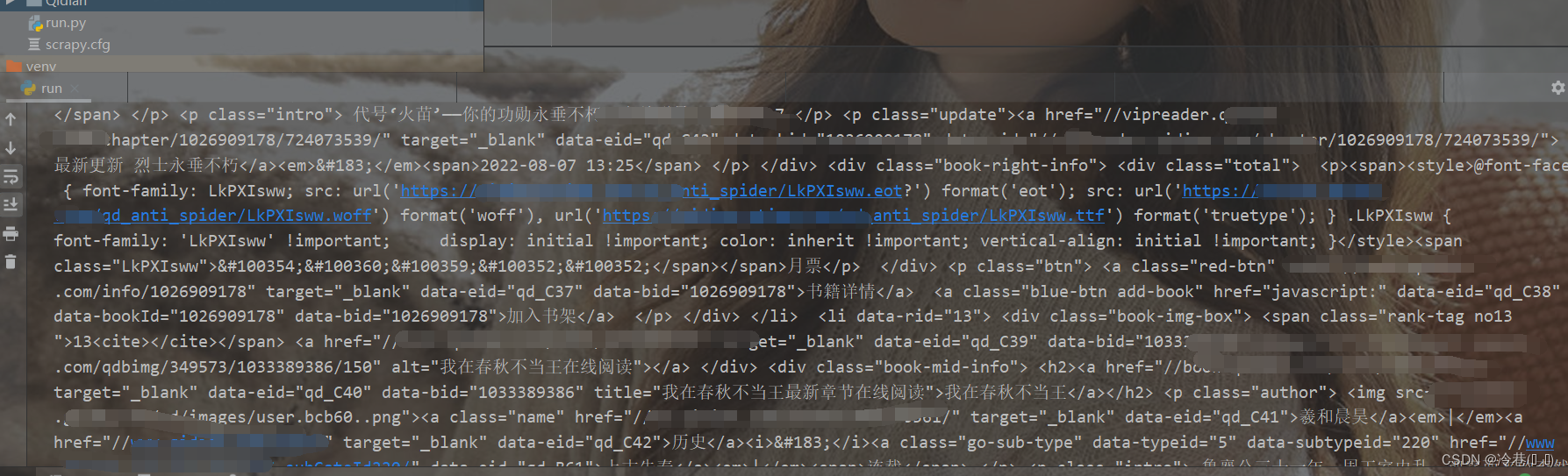
可以看到结果已经出来了
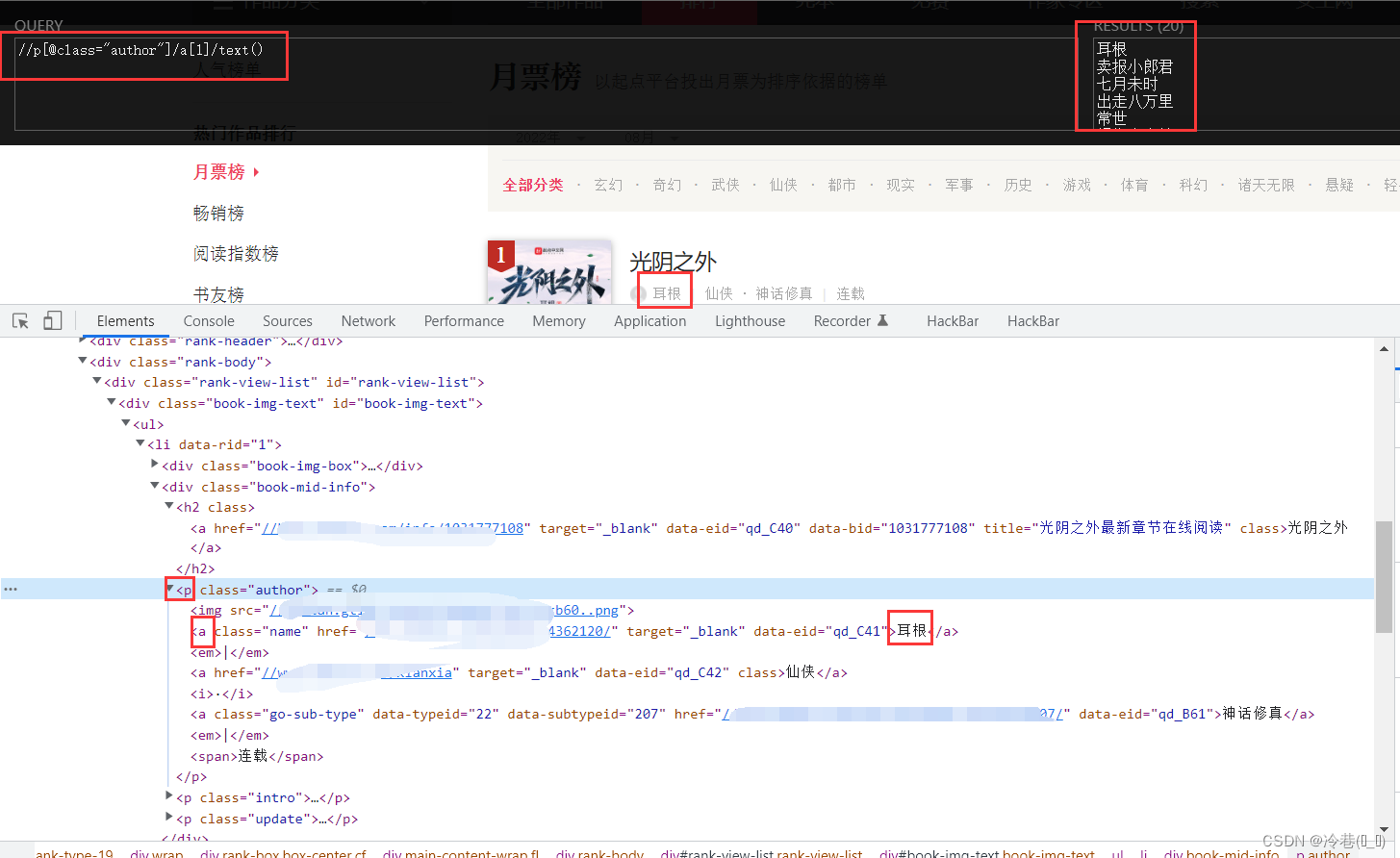
那么回到网站来分析一下,
首先是名字
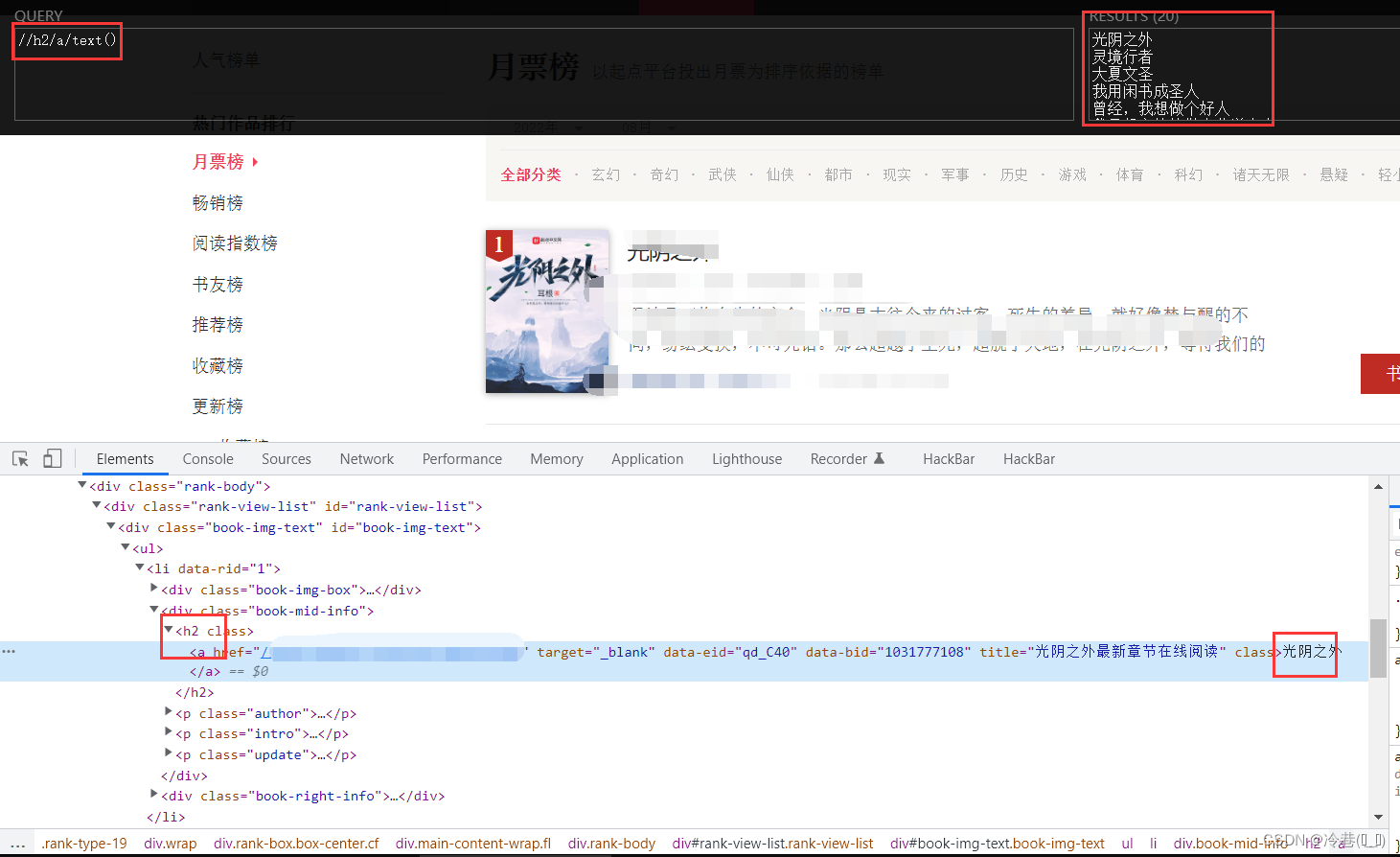
在h2标签下的a标签里面,直接用xpath来定位。
回到pycharm
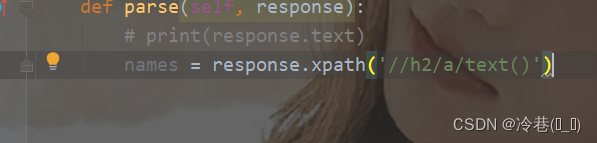
再来找作者
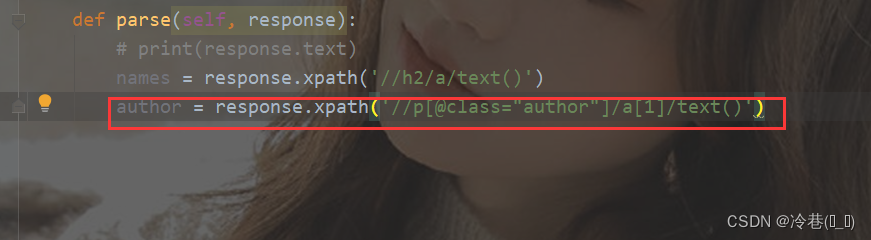
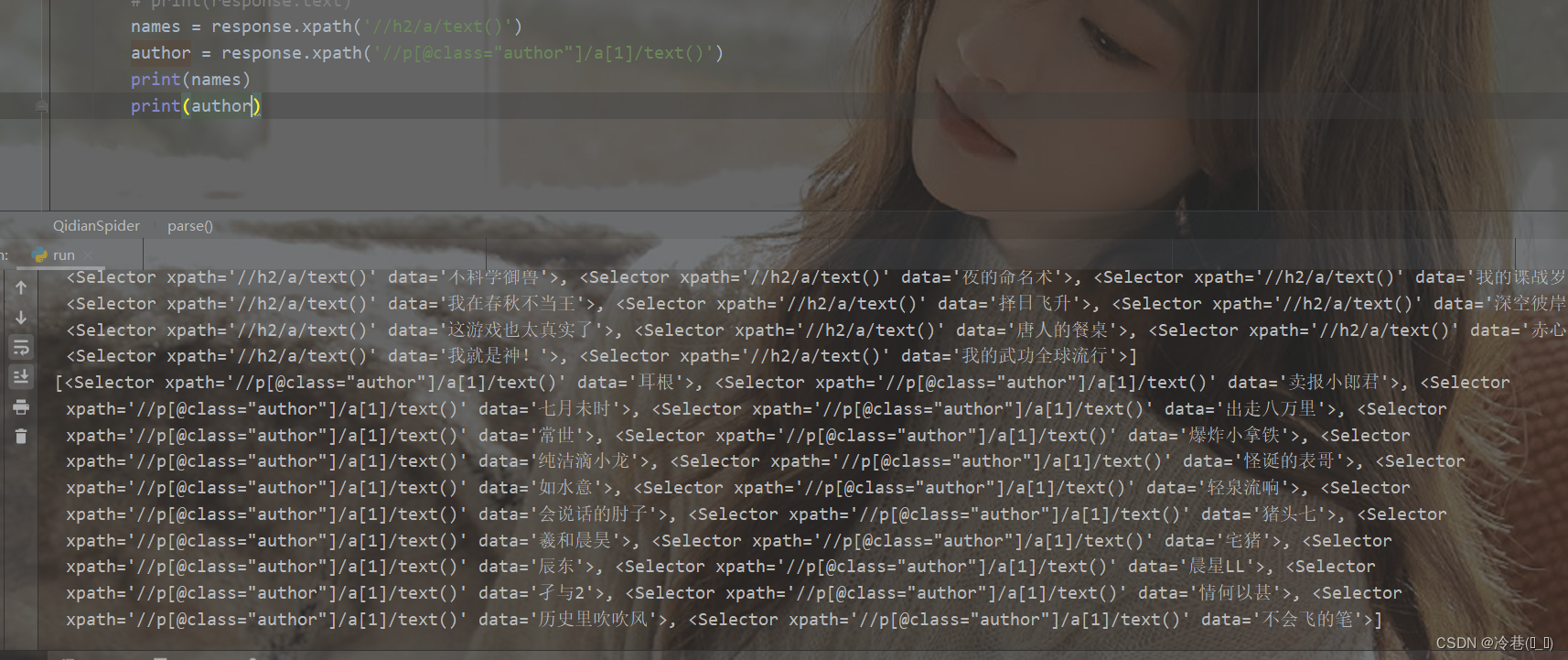
运行一下
加个extract来提取一下
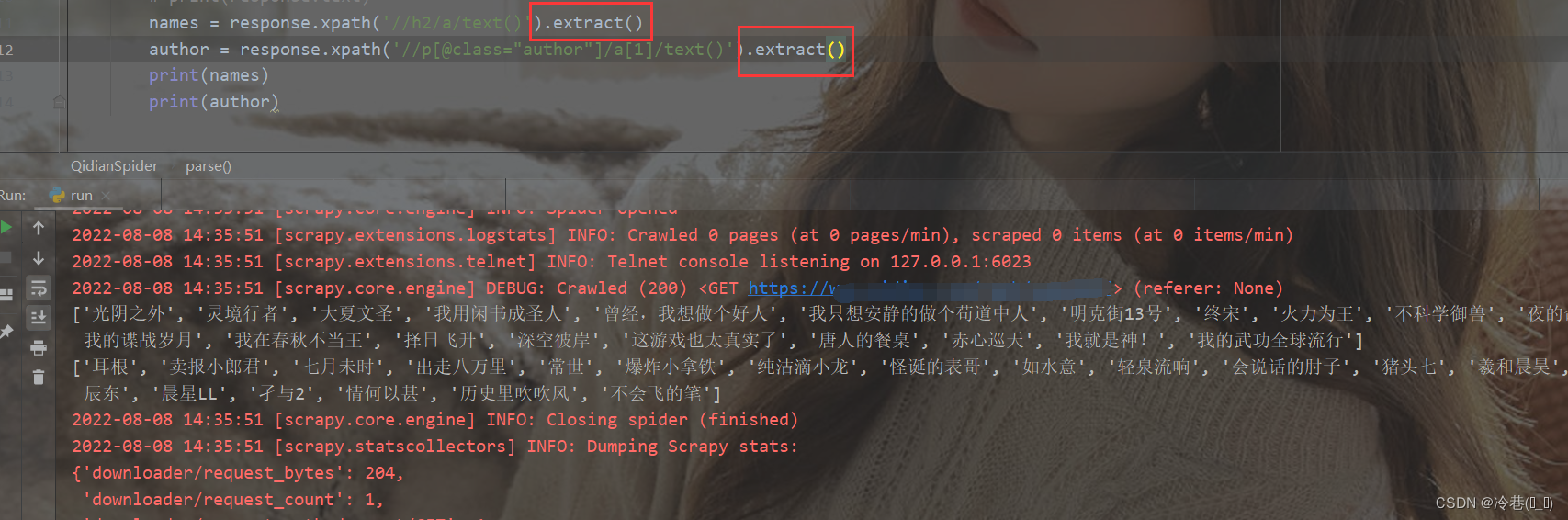
还记得 scrapy生成格式导出如:JSON,CSV和XML 吗
我们回到pycharm修改一下
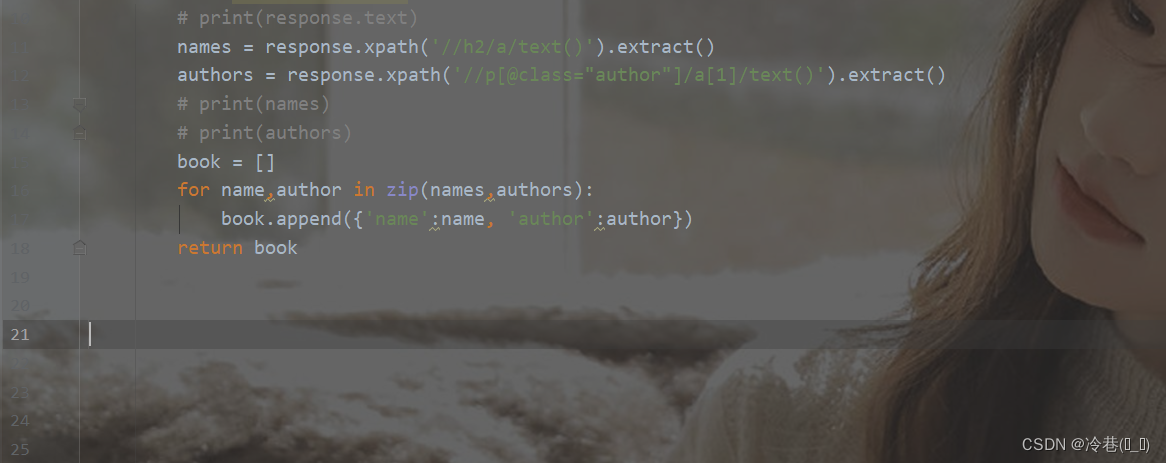
这里的话直接运行是没什么效果的,要到命令行执行
scrapy crawl qidian -o book.json 
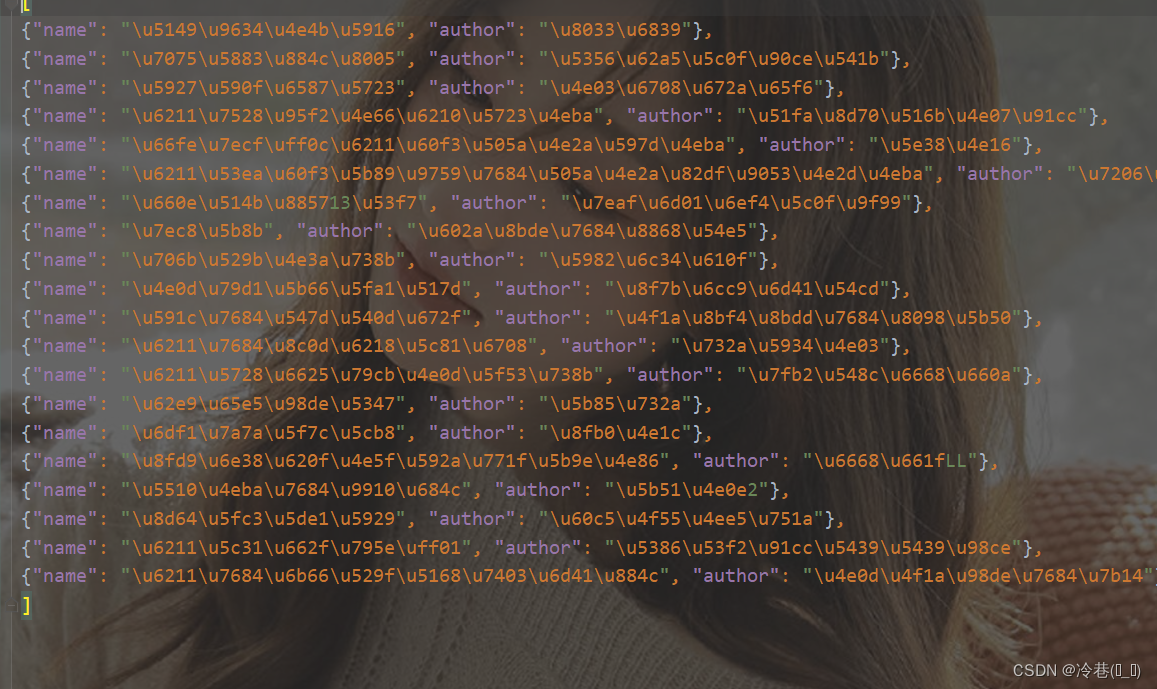
打开之后是编码
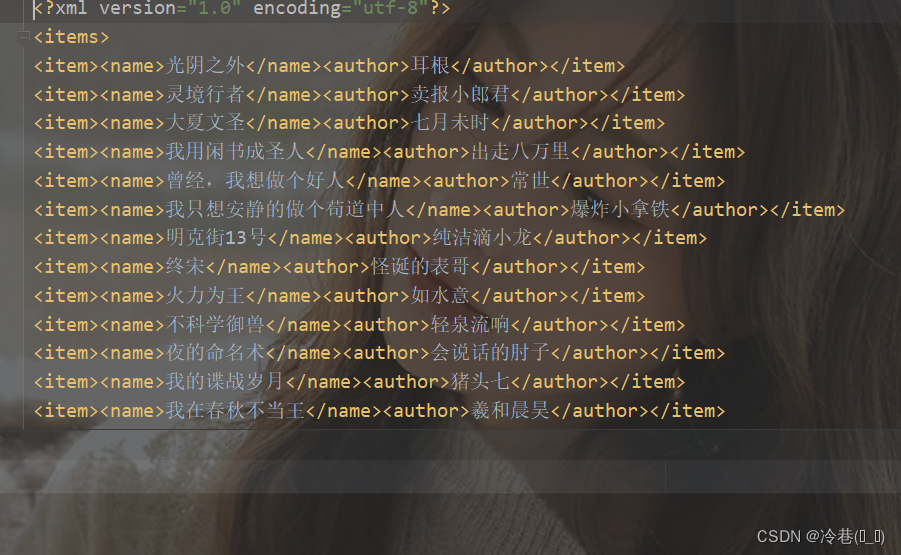
如果点一个xml的话就是文字,
而改成CSV的话,就舒服了
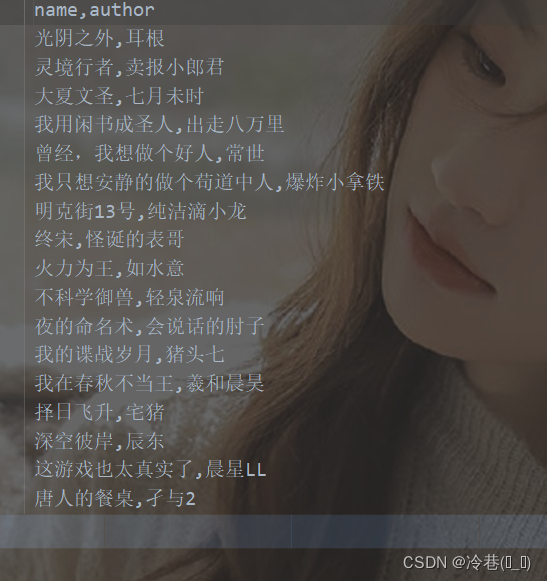
通过这个小小的案例就会发现,用scrapy来爬可比平时一点一点来爬方便多了!















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









