






主讲人:萧小奎
隐私保护挑战
匿名化,粗粒度依然有可能被攻击住重构出部分数据
直接发布统计数据容易被重构算法攻击,那么发布一个机器学习模型呢?
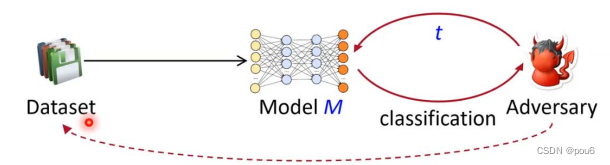
仍然有可能泄露隐私,模型对于原数据的元组可能跟其他元组上的表现不一样

差分隐私原理: 略
差分隐私不同噪声机制:拉普拉斯、随机化问答,或者根据不同场景设计差分隐私的方法
差分隐私数据库:略
差分隐私机器学习
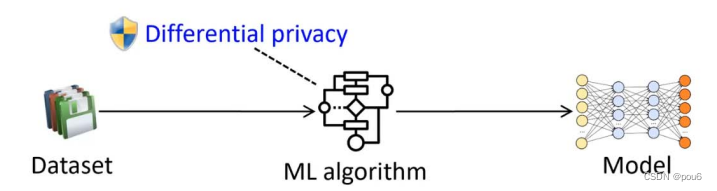

在神经网络计算梯度的时候加入噪声,这个梯度是用来更新权重参数的(因为只有计算梯度的时候需要加载源数据)
差分隐私数据采集:略
差分隐私数据合成:略
展望:
隐私和准确性的平衡
对于差分隐私机器学习:1.准确度 2.不能很好处理复杂模型如GAN(训练时每一步加噪声,经过很多步训练,隐私开销巨大)
差分隐私过于保守(默认攻击者清楚n-1个人的信息),不够贴近现实,有不少人改进差分隐私但是太复杂,差分隐私本身有优雅简洁的数学表达
满足差分隐私不等于满足法律条文,从法律条文出发设计隐私保护模型并借鉴差分隐私思想


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









