






目录
2.和重新训练(retrain from scratch)不损耗太大的性能
(2) BEKM(Balanced Embedding k-means)
Putting Things Together: GraphEraser
1.重新训练Scratch(retrain/train from scratch)
动机
数据保护最近引起了越来越多的关注,已经提出了一些法规来保护个人用户的隐私,例如欧盟的通用数据保护条例(GDPR),加州的加州消费者隐私法(CCPA),加拿大的个人信息保护和电子文档法(PIPEDA),《巴西通用数据保护法》(LGPD)。这些法规中最重要也是最有争议的条款之一是被遗忘权,它赋予数据主体从存储数据的实体中删除其数据的权利。在机器学习(ML)的背景下,研究人员认为,在被遗忘权的要求下,模型提供者有义务消除所有者要求被遗忘的数据的任何影响,这被称为machine unlearning(机器遗忘)
挑战
一个确定的机器遗忘方法包括删除想撤销的样本并从头开始重新训练ML模型。但当数据集很大时,这种方法在计算上的代价难以接受。许多近似的机器遗忘方法中,SISA(Sharded,Isolated,Sliced,and Aggregated)是最通用的解决方案,SISA的基本思想是将训练数据集随机分割成几个不相交的分片,并分别训练每个分片模型。模型提供者在接收到遗忘请求后,只需要重新训练相应的分片模型
然而,许多重要的现实世界数据集以图形的形式表示,例如社交网络,金融网络,生物网络,推荐系统和交通网络。为了利用图中包含的丰富信息,最近提出了一种新的ML模型,即图神经网络(GNN)。GNNs的核心思想是通过聚集来自相邻节点的特征信息将图数据转换为低维向量。然而,像SISA中那样随机地将节点划分为子图可能会严重损害最终的模型性能。因此,迫切需要一种新的方法来在GNN的背景下遗忘数据样本
贡献
首先确认在GNN中两种常见类型的机器遗忘需求,即节点遗忘(node unlearning)和边遗忘(edge unlearning)
然后,提出了一个通用的GNN模型中的框架GraphEraser用于机器遗忘。在框架中,提出了平衡图划分的目标,并提出两个平衡图划分算法,还提出了一种基于学习的聚合方法
在五个真实世界的图数据集和四个最先进的GNN模型上进行了广泛的实验,说明GraphEraser的时间效率和模型性能
图unlearning问题定义
本文定义两种GNN中机器遗忘的场景,即节点遗忘和边遗忘
1. 节点遗忘(node unlearning)
在节点遗忘中,遗忘u的数据时,这意味着模型提供者应该从GNN的训练图中遗忘u的节点特征及其与其他节点的链接。以社交网络为例,节点遗忘意味着需要从目标GNN的图中删除用户的个人资料信息和社交联系。
2. 边遗忘(edge unlearning)
在边遗忘中,数据主体希望撤销其节点u和另一个节点v之间的一条边。使用社交网络作为示例,边遗忘意味着社交网络用户想要隐藏他们与另一个人的关系
通用unlearning目标
1.High Unlearning Efficiency 高的时间效率
2.Comparable Model Utility 和重新训练(retrain from scratch)不损耗太大的性能
本文提出在GNN中unlearning的目标
1.平衡图划分
每个分片中的节点数量应该相似,这样每个分片的retrain时间是相似的,提高了整个图unlearning过程的效率。
2.和重新训练(retrain from scratch)不损耗太大的性能
为了在节点分类任务中达到相当的模型效用和高预测精度,每个分片都应该保持训练图的结构属性。
GraphEraser框架
GraphEraser有三个核心部分
数据划分->子模型训练->子模型聚合
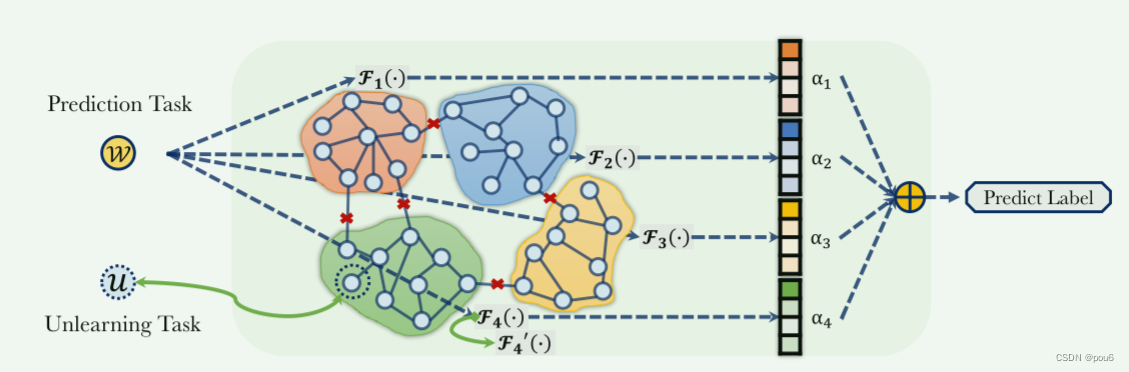
当需要进行数据遗忘时,只需要重新训练被遗忘数据所在的某个子模型
1.数据划分
本文提出两种平衡图划分策略
(1) BLPA(Balanced LPA)
只考虑结构信息,并尽可能地保留它。一个可靠方法是依靠社群检测 ,其目的是将图划分为内部具有密集连接而组之间具有稀疏连接的节点组。已经提出了一系列社群检测方法中,LPA具有计算开销小、性能上级的优点。因此,依靠LPA来设计的图划分算法
LPA流程如下图:
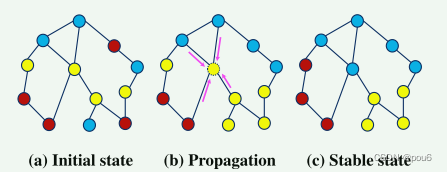
每个节点都被分配了一个随机的分片标签(图a)。在标签传播阶段(图b →图c),每个节点发送自己的标签,并将其标签更新为从其邻居接收的大多数标签。标签传播过程多次迭代所有节点,直到收敛(没有节点更改其标签)。
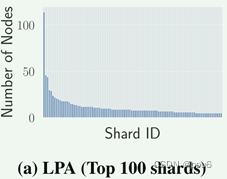
然而,直接应用经典的LPA会导致高度不平衡的图划分。如下图,最大的分片包含113个节点,而最小的分片只包含2个节点,不满足平衡图划分的目标
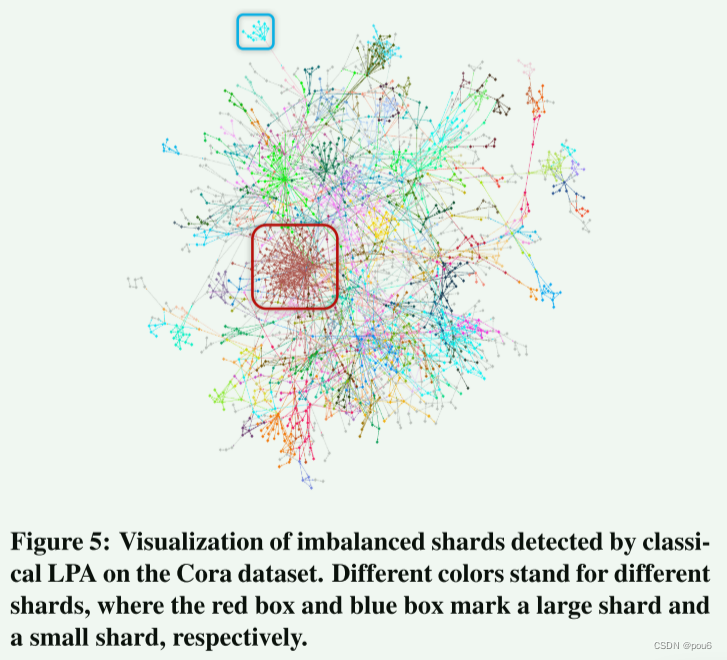
下图显示了Cora数据集上经典LPA检测到的碎片的可视化,其中不同的颜色代表不同的碎片。使用红框和蓝框来标记一个大碎片和一个小碎片。可以观察到两个碎片的明显不相等的大小。(附录B)
为实现平衡图划分,在LPA基础上改进成BLPA。给定所需的分片数k和最大分片大小δ。每个节点对每个分片都有一个偏好值,偏好值定义为目标分片的邻居数量,按照偏好值对节点分片对进行排序。对于偏好降序排列的每一对如果目标分片中的当前节点数不超过δ,则将该节点分配给目标分片。不断迭代,直到达到最大迭代T,或者分片不改变
详细步骤:
BLPA算法input输入:
所有节点的集合V
邻接矩阵A
分片数k
每个分片中最大节点数δ
最大迭代次数T
output输出:分片
1.将每个节点随机分配到k个分片之一,得到
2.计算每个节点u的信息组tuple,
和
分别是u当前分片和目标分片,
是
的邻居节点数量,计算所有其他分片的邻居节点数量,每个节点u有多组tuple,都储存在
中
3.对按
降序排列得到
(邻居数量越多越靠前)
4.对于中的信息组tuple,如果目标碎片
的大小没有超过给定的阈值δ,将节点u添加到目标分片,并将其从当前分片中删除,然后从
删除所有包含u的tuples
5.重复2-4步,直到达到最大迭代T,或者分片不改变
(2) BEKM(Balanced Embedding k-means)
同时考虑结构信息和节点特征。首先将节点特征和图结构表示为低维向量,即节点嵌入,然后将节点嵌入聚类到不同的分片中。
首先使用预训练的GNN模型来获得所有节点嵌入embedding,然后对得到的节点嵌入执行聚类。关于聚类,可使用的k-means算法,该算法由三个阶段组成:重新分配,节点重新分配和质心更新。初始化阶段,随机采样k个质心,它们代表每个碎片的“中心”。在节点重新分配阶段,每个节点被分配到其“最近”的碎片,根据与质心的欧几里得距离。在质心更新阶段,新的质心被重新计算为其对应分片中所有节点的平均值。与LPA方法的情况类似,直接使用kmeans也会产生高度不平衡的分片。
基于上述问题,提出BEKM(Balanced Embedding k-means),类似BLPA,定义所需分片的数量k、每个分片中的节点嵌入的最大数量δ,将偏好定义为所有节点-分片对的节点嵌入与分片质心之间的欧氏距离。较短的距离意味着较高的优先级。不断迭代,直到最大迭代次数T或质心不变

详细步骤:
BEKM算法input输入:
所有节点的嵌入embedding集合
分片数k
每个分片中最大节点数δ
最大迭代次数T
output输出:分片
1. 随机选择k个质心
2. 计算所有节点嵌入和所有质心之间的欧式距离,从而产生n×k个嵌入-质心对。这些对存储在
中
3. 对按欧式距离升序排列得到
(距离越小越靠前)
4.对于中的每个嵌入质心对,如果
的大小小于δ,我们将节点i分配给分片
行。之后,我们从
中删除所有剩余的包含节点i的元组。最后,新的质心被计算为其对应分片中所有节点的平均值。
5.重复步骤2-4,直到达到最大迭代T,或者质心不变
2.子模型训练:
本文中的GraphEraser只是一个基于图模型的框架,中间的子模型自定义,本文使用四个图模型SAGE,GCN,GAT和GIN
3.子模型聚合:
LBAggr(Learning-based Aggregation)
提出了一种基于学习的聚合方法LBAggr。我们为每个分片模型分配一个重要性分数,可以根据以下损失函数进行深度学习。

是节点w的特征向量
是节点w的邻居
y是w真实标签
是分片模型i
是
的权值
m是分片总数
是交叉熵损失
优化问题
可以用梯度下降法寻找最优α来解决优化问题。但是,直接运行梯度下降可能会导致α中的负值。为了解决这个问题,在每次梯度下降迭代之后,将负权值映射回0(projected gradient descent的思想 PGD)。此外,权值的总和可能偏离1。使用每次迭代中当前分数的总和来归一化重要性分数;然而,经验发现,在不同的时期,损失可能非常不稳定。因此,在每次迭代中使用Softmax函数进行归一化。
权值被遗忘问题
注意到,被用来学习权值的节点也可能被unlearning,那么此时就要重新学习分片的权值,该学习时间被计为非学习时间的一部分,为了减少这种重新学习时间,我们建议只使用训练图中的一小部分随机节点进行重新学习。通过下面实验,在训练图中只使用10%的节点可以实现与使用所有节点相当的性能。从这个意义上说,当要unlearning的节点不用于训练LBAggr时,重新学习分片的权值是不必要的。
Putting Things Together: GraphEraser

GraphEraser的整体工作流程如下
如果使用的GNN是GCN(图卷积神经网络),调用算法BLPA来划分;否则,使用算法BEKM来划分
然后对子模型训练
最后,我们从中随机抽取一些节点
来训练每个分片模型的重要性得分α。
当一些节点或边被unlearning时,只需要重新训练相应的分片模型。
实验
数据集
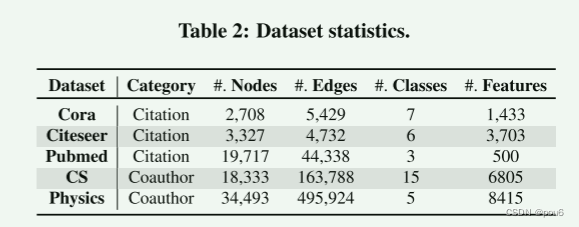
Cora、Citeseer和Pubmed是引文数据集,其中节点代表出版物,如果一个出版物引用另一个出版物,则两个出版物之间存在边。CS和Physics是共同作者数据集,如果两个作者在至少一篇论文上合作,则他们是连接的。
子模型
SAGE,GCN,GAT和GIN
对于每个GNN模型,我们堆叠两层GNN模块。所有的模型都是用PyTorch Geometric2库实现。本文中考虑的所有GNN模型(包括碎片模型)都经过了100个epoch的训练。使用Adam优化器,并将默认学习率设置为0.01,权重衰减为0.001。
评价指标
1. 时间效率Unlearning Efficiency
由于分片的多样性,直接测量一个unlearning请求的unlearning时间是不准确的。因此,计算了100个独立遗忘请求的平均遗忘时间。具体来说,从训练图中随机抽取100个节点/边,记录其对应分片模型的再训练时间,并计算平均再训练时间。
2.模型性能Model Utility
使用Micro F1分数(对每类F1分数计算算术平均值)来衡量模型效用,该分数被广泛用于评估GNN模型对多类分类的预测能力
Baselines
1.重新训练Scratch(retrain/train from scratch)
Scratch方法可以获得较好的模型性能,但其时间效率较低
2.随机划分图Random
Random方法可以获得较好的时间效率,但其模型性能较低
实验设置
对于每个数据集,我们将整个图随机分为两个不相交的部分,其中80%的节点用于训练GNN模型,20%的节点用于评估模型性能。注意,图划分算法仅应用于训练图。默认情况下,我们将Cora、Citeseer、Pubmed、CS和Physics的分片数量k分别设置为20、20、50、30和100,这确保了每个分片都在合理数量的节点和边上进行训练。每个分片δ中的最大节点数被设置为。在附录G中验证了该设置的有效性。BLPA和BEKM的最大迭代次数T都被设置为30,因为根据经验表明T = 30可以保证两种算法的收敛性。此外,我们设置BEKM的嵌入维数为32。注意如果嵌入维数很大,降维方法可能会有所帮助。
实验结果
1.时间效率Unlearning Efficiency
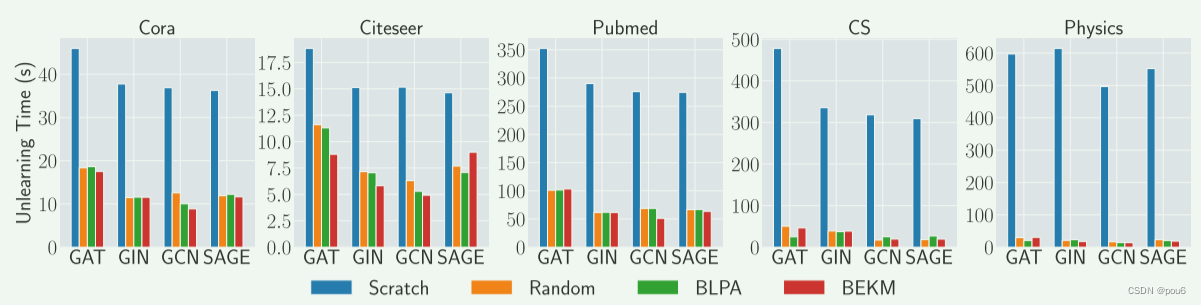
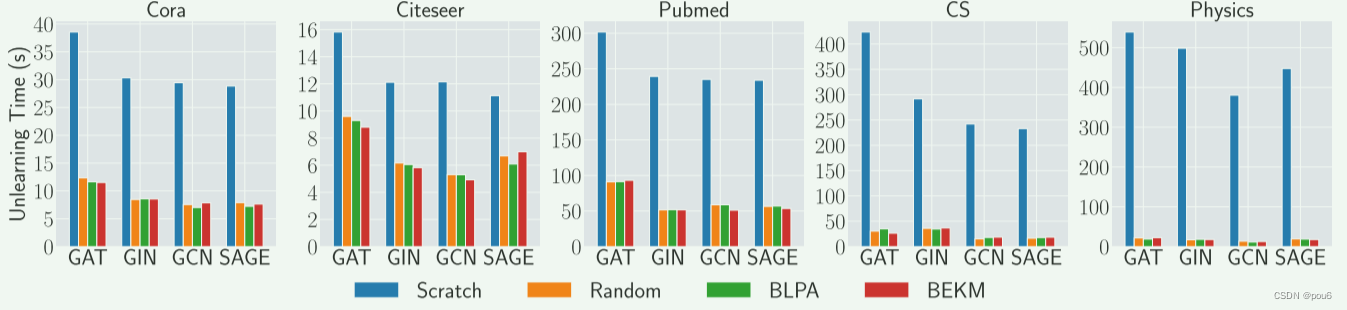
每个遗忘请求的时间成本由两部分组成:重新训练分片模型和用LBAggr重新学习权值
由上图不论是在节点遗忘还是边遗忘,与Scratch方法相比,基于分片的遗忘方法可以显着提高遗忘的时间效率。对于所有四个GNN模型,可观察到时间效率的提升。此外,较大数据集(Pubmed,CS和Physics)的相对时间效率的改善比较小数据集(Cora和Citeseer)更显著。比较不同的基于分片的方法,观察到GraphEraser-BLPA和GraphEraser-BEKM具有与Random相似的学习时间
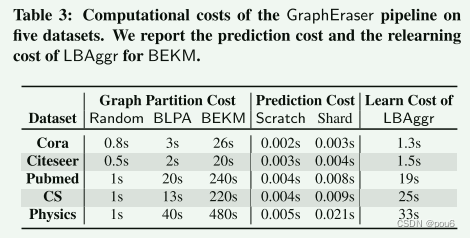
上文提到仅使用训练图中的一小部分节点来学习权值,所有数据集上LBAggr的平均重新学习时间显示在Ta的最后一列中,结果表明,对于大多数数据集,重新学习时间小于30 s,与重新训练子模型相比,这是可以忽略不计的。
由图可知除了遗忘代价外,GraphEraser中还有两个额外的代价:图划分代价(Graph Partition Cost)和预测代价(Prediction Cost),
对于图划分代价(Graph Partition Cost),观察到BLPA和BEKM的图划分成本高于Random。这是预期的,因为BLPA和BEKM都需要多次扫描以保留结构信息。一旦图划分完成,我们就保持这个固定不变。从这个意义上说,可以容忍这个时间成本,因为它只执行一次。根据附录F中实验验证,使用固定分区不会导致GraphEraser的模型性能明显下降。
对于预测代价(Prediction Cost),与Scratch方法相比,基于分片的方法稍微耗时,因为我们需要从所有分片模型中获取预测并将其聚合。但是多出来的时间可以忽略不计,因为它们的大多数值都小于0.01秒。
2.模型性能Model Utility
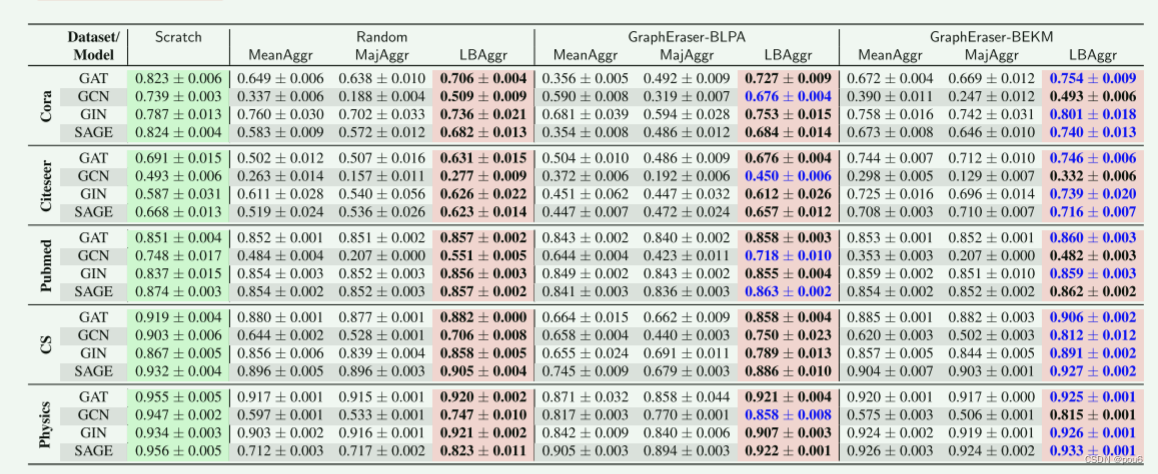
上图是节点遗忘node unlearning的结果
在绿色背景中突出显示Scratch方法,在红色中突出显示本文提出的聚合方法
对于每个图划分策略,用黑色粗体突出显示最佳值
对于每个GNN模型,用蓝色粗体突出显示最佳值
在Cora和Citeseer数据集上,GraphEraser-BEKM和GraphEraser-BLPA与random随机方法相比可以获得更好的F1得分。例如,在Cora数据集上训练的GCN模型上,GraphEraser-BLPA的F1得分为0.676,而Random的相应结果为0.509。对于Pubmed、CS和Physics数据集,Random方法的F1得分与GraphEraser-BEKM和GraphEraser-BLPA相当,在某些设置中甚至可以实现与Scratch方法相似的F1得分。
猜想如果图结构信息对GNN模型的贡献不大,那么Random方法可以实现与GraphEraser-BLPA和GraphEraserBEKM相当的模型性能。
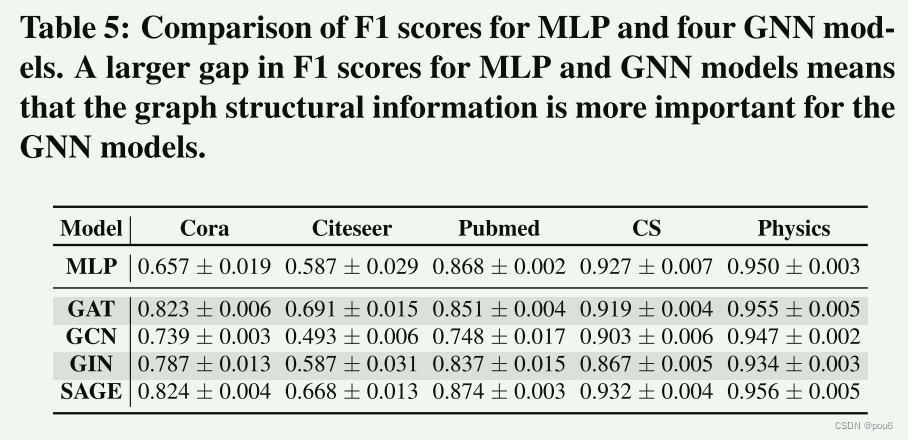
为了验证上述猜想,即图结构信息是否会影响GNN模型在不同数据集之间的性能,我们引入了一个baseline,该基线使用3层MLP(多层感知机)来训练所有数据集的预测模型。只使用节点特征来训练MLP模型,而不考虑任何图结构信息。表5描述了MLP模型和四个GNN模型在五个数据集上的F1得分比较。观察到对于Cora和Citeseer数据集,MLP模型的F1得分显著低于GNN模型,这意味着图结构信息在GNN模型中起着主要作用。另一方面,与Pubmed、CS和Physics数据集上的GNN模型相比,MLP模型可以获得足够的F1分数,这意味着图结构信息在GNN模型中的贡献不大。
总之,图结构信息对GNN模型的贡献可以显著影响基于分片的图unlearning方法。在实践中,建议模型提供者在选择适当的图unlearning方法之前评估图结构的作用。为此,他们可以首先比较MLP和GNN的F1分数,如果MLP和GNN之间的F1分数的差距很小,也就是说图结构信息对GNN模型的贡献不大,则随机方法可以是一个很好的选择,因为它更容易实现并且可以实现与GraphEraser-BLPA和GraphEraser-BEKM相当的模型性能,当然,由于GraphEraser-BLPA和GraphEraser-BEKM具有更好的模型性能,因此也是很好的选择。
关于两种图划分方法之间的选择,即,GraphEraser-BLPA和GraphEraser-BEKM,观察到,如果GNN遵循GCN结构,则可以选择GraphEraser-BLPA,否则,可以采用GraphEraser-BEKM。我们认为这是因为GCN模型需要节点度信息进行归一化,而GraphEraser-BLPA可以保留更多的局部结构信息,从而更好地保留节点度。
可以观察到GraphEraser-BEKM在某些情况下的性能略好于Scratch。例如,在Cora数据集和GIN模型上,GraphEraser-BEKM的F1得分为0.801,而Scratch的相应F1得分为0.787。这种现象可能有两个原因。首先,采样通常可以消除数据集中的一些“噪音”,这与其他人研究的观察结果一致。其次,GraphEraser通过聚合所有子模型的结果来进行最终预测,从这个意义上说,GraphEraser执行了一个集成,这是另一种提高模型性能的方法
考虑到节点学习和边学习的结论在时间效率和模型性能方面是相似的,结果可以在附录H中找到
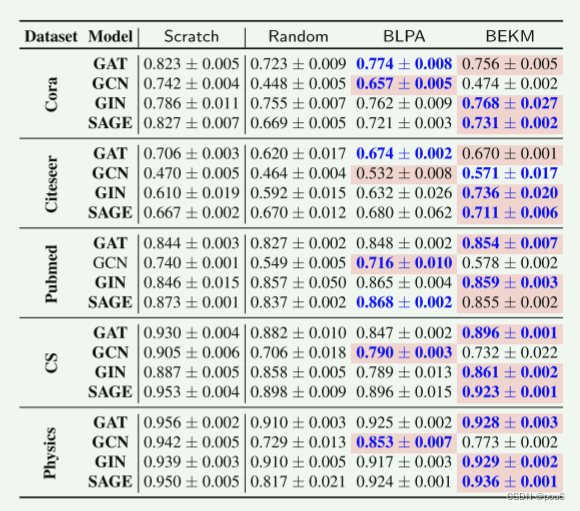
边遗忘edge unlearning结果
3.聚合方法LBAggr的有效性
一般来说,与MeanAggr和MajAggr相比,LBAggr在绝大多数情况下可以有效提高F1评分。还观察到MajAggr方法在大多数情况下执行最差。认为这是因为MajAggr忽略了从每个分片模型中获得的后验信息。具体来说,如果分片模型的后验对多个类的置信度很高,而不是对单个类的置信度很高,那么MajAggr方法将丢失排名第二的类的信息,从而导致模型性能变差。
比较不同的GNN模型,在LBAggr中,GCN受益最大,而GIN受益最小。就模型性能而言,GraphEraser-BLPA方法从LBAggr中受益最大。我们推测这是因为BLPA划分方法可以捕获局部结构信息,同时丢失训练图的一些全局结构信息。使用LBAggr通过为分片模型分配不同的重要性分数,有助于更好地捕获全局结构信息。
关于训练节点数量的影响:
上文讲到为了进一步提高遗忘时间效率,可以使用训练图中的一小部分节点来学习权重。这样做可以有效地减少LBAggr的重新学习时间。本文在三种不同的情况下进行了实验:随机抽样10%的节点,随机抽样固定数量的1000个节点,以及使用训练图中的所有节点。

观察到,使用10%的节点和使用固定数量的1000个节点都可以获得与使用所有节点相当的模型性能。在实践中,建议模型提供者采用最低10%和1000来计算权重。换句话说,模型提供者可以为小图形使用10%,为大图形使用1000。对于GraphEraser-BLPA,结论也是一样的。
4.与现有平衡图划分解决方案的比较
这些算法可以大致分为三类:
第一类只考虑图的结构信息,并依赖于社群检测比如 GraphEraser-BLPA
第二类考虑图的结构信息,而不依赖于社群检测
第三类考虑结构信息和节点特征,如GraphEraser-BEKM
对于每个类别,选择一个最具代表性的方法作为竞争对手
1.BLPA-LP
该方法通过约束标签传播过程来实现平衡的图分区。一般的想法是将标签传播过程公式化为具有个变量和
个约束的线性规划问题,其中n和k分别是节点数和分片数。当图的大小和分片的数量很大时,求解线性规划问题是耗时的。
2.METIS
在最小边数的情况下得到平衡图划分
3.BEKM-Hungarian
将节点重新分配步骤表示为匹配问题,并通过Hungarian算法近似求解
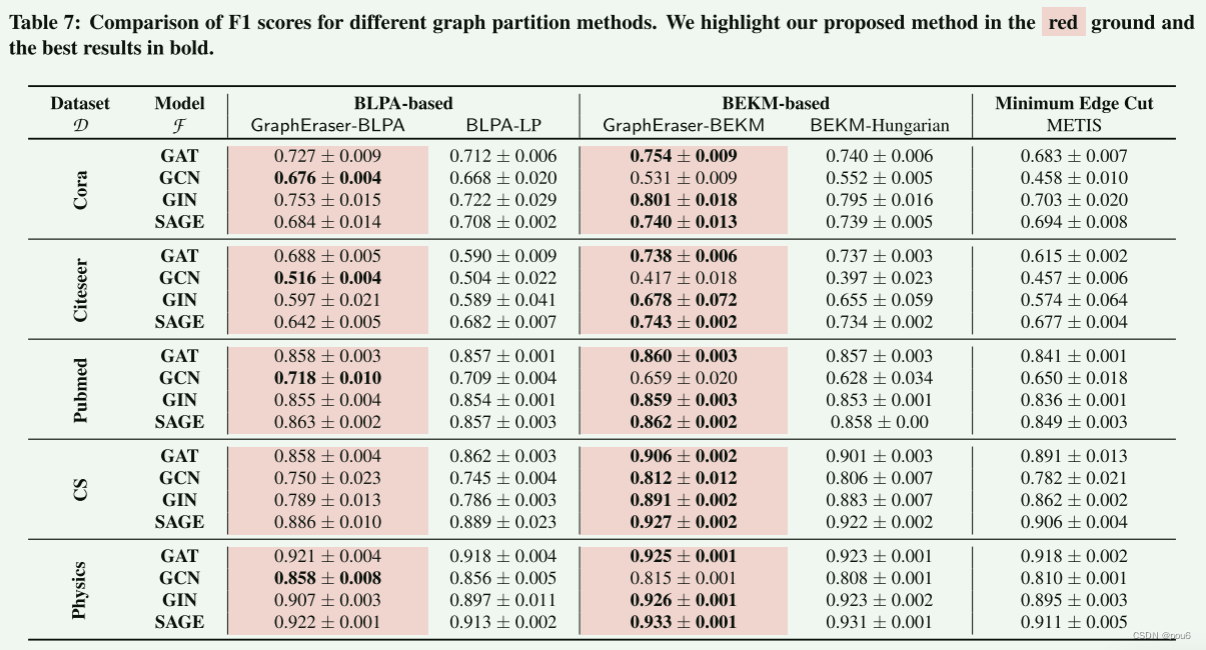
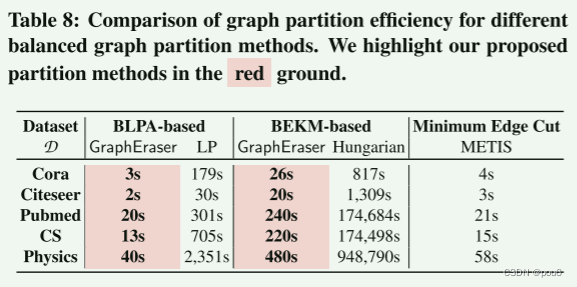
图划分方法依赖于图结构信息和节点特征。也就是说,GraphEraserBEKM和BEKM-Hungarian,在模型为GAT、GIN和SAGE时达到最佳模型性能,这与上文结论一致。比较GraphEraser-BEKM和BEKM-Hungarian,观察到它们实现了相似的模型性能;然而,BEKM-Hungarian的计算复杂度(O(n3))远高于GraphEraser-BEKM(O(k · n))。
从表8中,还观察到BEKM-Hungarian不能扩展到大型图。
当目标模型为GCN时,基于社群检测的方法,即,GraphEraser-BLPA和BLPA-LP,比METIS实现了更好的性能。我们怀疑这是因为GCN模型需要节点度信息进行归一化,而基于社群检测的方法可以保留更多的局部结构信息,从而更好地保留节点度。GraphEraser-BLPA比BLPA-LP更快(参见表8),同时实现了相当的模型性能。
5.GraphEraser面对攻击的性能
由于我们的方法是高度经验性的,因此我们采用了最先进的针对机器学习的攻击来量化当图没有重新分区时GraphEraser的额外信息泄漏。特别是,Chen等人表明,攻击者使用增强的成员推断攻击,可以确定目标样本是否存在于原始模型中,并且当他们可以访问原始模型和未学习模型时,从未学习模型中撤销。
M. Chen, Z. Zhang, T. Wang, M. Backes, M. Humbert,and Y. Zhang. When Machine Unlearning Jeopardizes Privacy. In ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 896–911.ACM, 2021. 6, 12, 13
在这里,我们将GraphEraser的额外信息泄漏量化为确定unlearning和GraphEraser unlearning之间的性能差异。
1.GraphEraser unlearning
通过直接从对应的分片图中删除被撤销的节点来获得未学习的模型,并重新训练对应的分片模型。这就是GraphEraser生成未学习模型的方式。
2.deterministic unlearning
从头开始重新训练(重新划分图,并训练一组新的分片模型)这种类型的unlearning确定性地unlearn每个组件,但它非常耗时。
将这两种场景分别表示为和
,额外的信息泄漏是
和
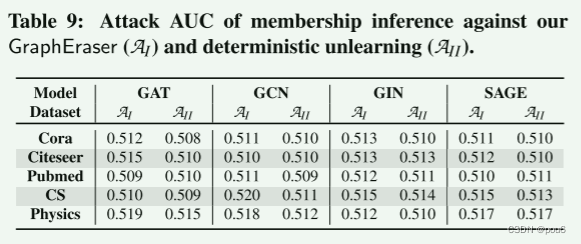
之间的AUC之差。表9中的实验结果表明,
和
的攻击AUC都接近0.5,这意味着GraphEraser不会泄露太多额外的信息。这也与chen的观察结果一致,即基于SISA的方法在成员推理上表现不佳,因为聚合减少了特定样本对其全局模型的影响。
附录部分内容
图神经网络细节
coming soon
BLPA 和 BEKM迭代次数T
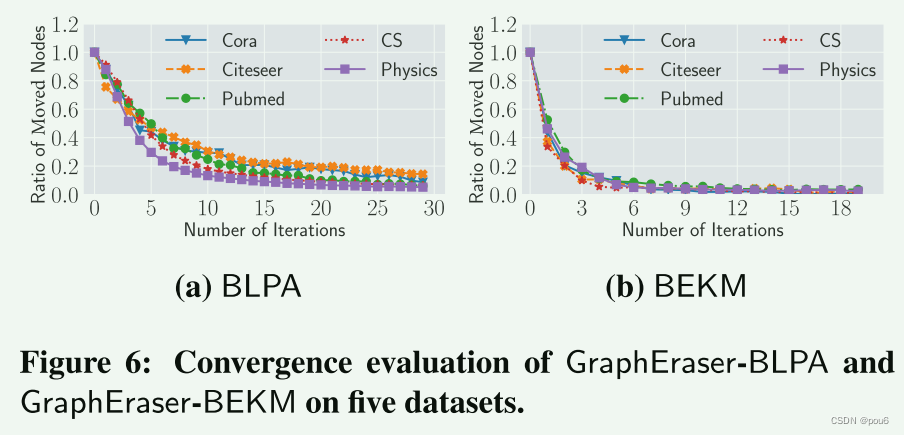
上图展示了每次迭代中节点改变的比率。实验结果表明,在所有5个数据集上,两种算法在30次迭代内移动节点的比率逐渐接近于零。因此,我们将所有实验的迭代次数T设置为30。
分片权值与分片属性之间的相关性
分片的F1得分与其权值之间的相关性
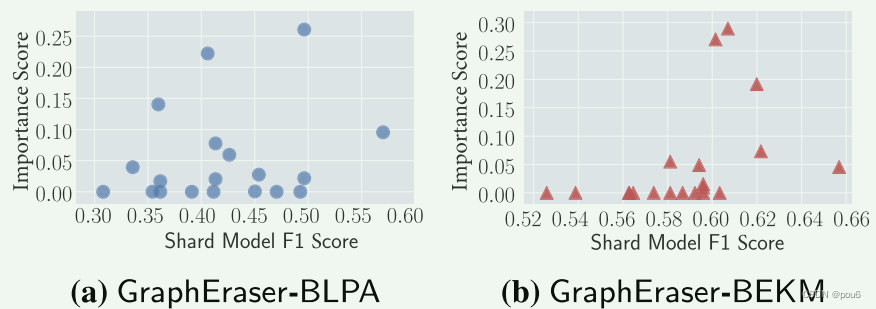
通常,预测更准确的分片模型被分配了更重要的重要性分数 (????BLPA没看出来)
分片的图形属性与权值的关系
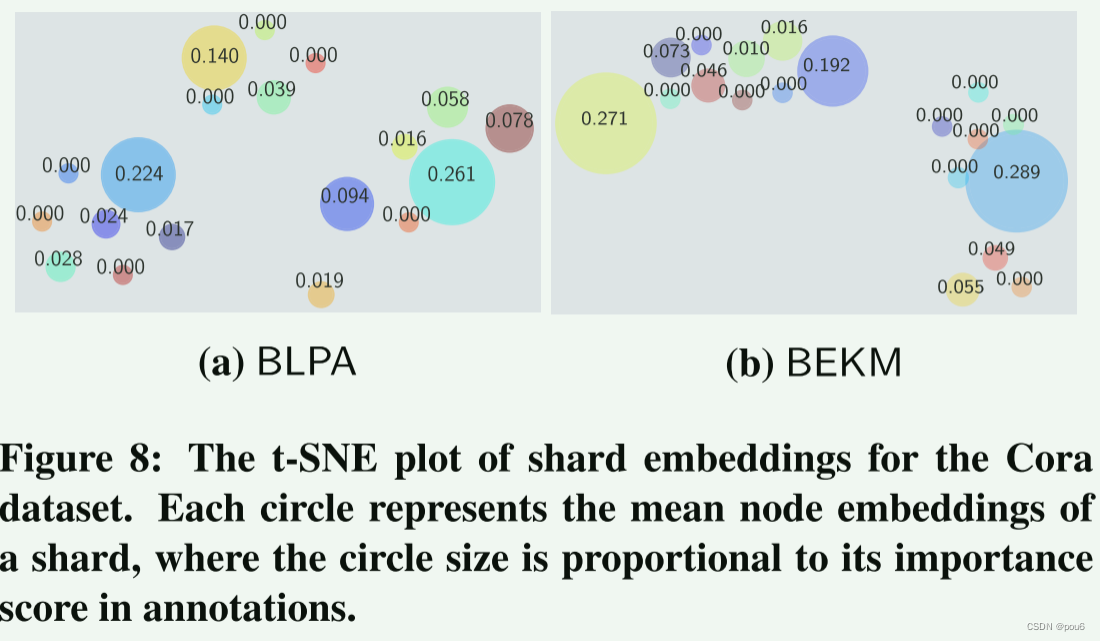
通过对从预训练的GNN模型中获得的所有节点嵌入进行平均来提取每个分片的嵌入,并使用t分布随机邻居嵌入(t-SNE)将分片嵌入投影到二维空间中
具有更大权值的分片通常周具有更小权值的分片。这意味着,对于在类似图上训练的分片(二维空间中类似的分片嵌入),LBAggr会为其中一个分配更高的分数。另一方面,它也会丢弃冗余信息以提高效用。
图结构的重要性
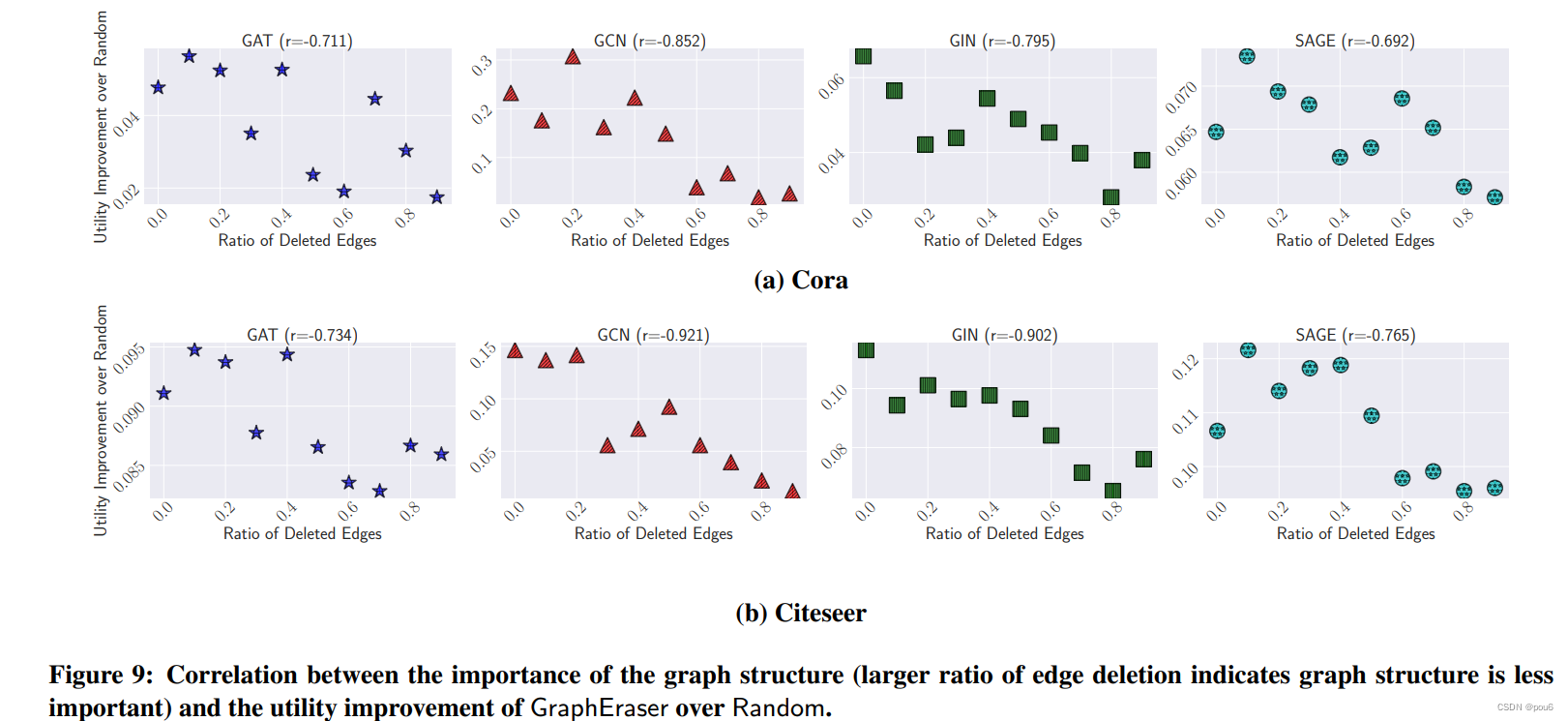
为了更好地说明图结构的重要性与GraphEraser 和 Random(SISA)的性能改进之间的相关性,我们对Cora和Citeseer进行了另一个实验。具体来说,我们从训练图中删除边然后比较GraphEraser和Random之间的性能差距。图9显示了实验结果。我们以10%的步长从0%到90%改变删除边的比率(如x轴所示)。较高的删除率减少更多的图结构信息。y轴代表GraphEraser相对于Random的效用改进。虽然有一些离群值,但总体趋势(通过每个子图上方的Pearson相关性得分来衡量)表明,当图形结构更重要时,GraphEraser相对于Random的效用改进在大多数情况下更显著。
GraphEraser的鲁棒性
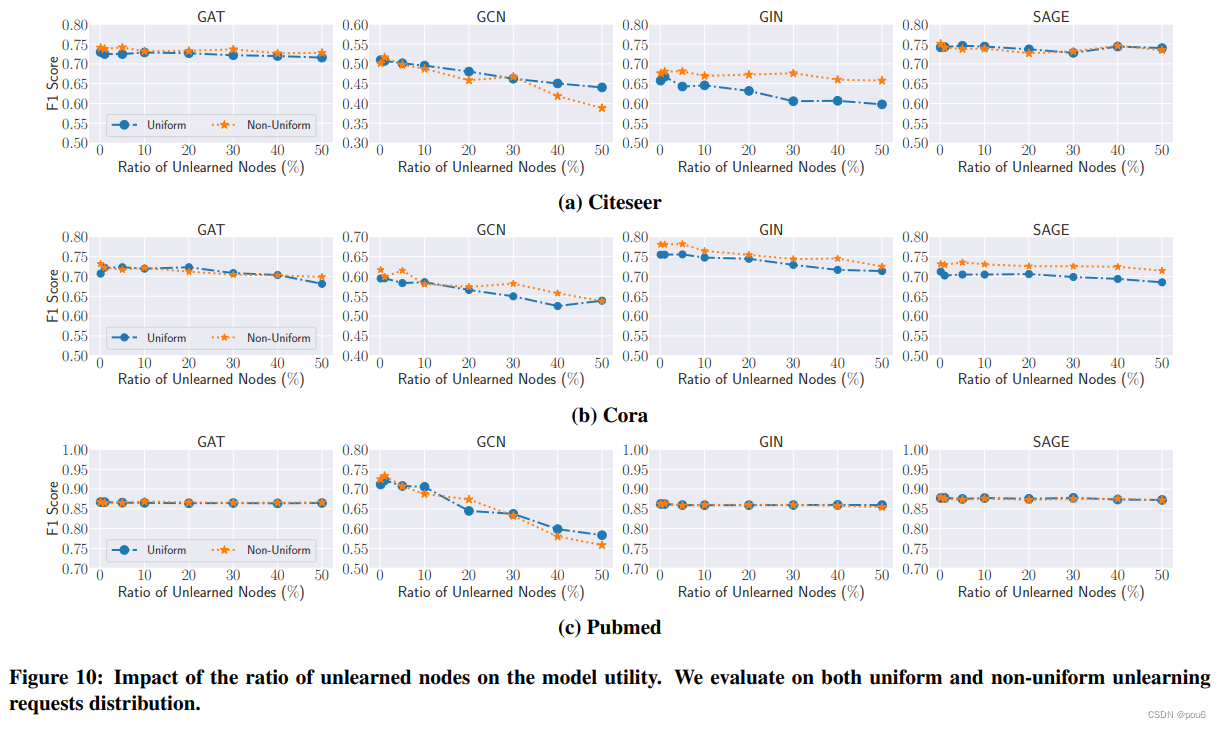
研究unlearning节点的数量对GraphEraser模型效用的影响
考虑节点unlearning请求:均匀和非均匀
对于均匀的unlearning,从所有分片中随机删除节点
对于非均匀unlearning,只从一半大小较大的分片中删除节点
在三个数据集上的实验结果。观察到,当未学习节点的比例小于10%时,GraphEraser的F1分数在大多数设置中不会显著下降。当较大比例的节点被删除时,我们确实观察到在某些情况下性能下降。例如,对于在Pubmed上训练的GCN,当删除节点的比例为50%时,效用从0.72下降到0.56。但是在实践中,不太可能发生50%的节点被删除的情况。总的来说,我们得出结论,GraphEraser是强大的大量节点的删除。比较非均匀和均匀unlearning的结果,观察到删除的分布并不显着影响鲁棒性。
消融研究
分片数量k
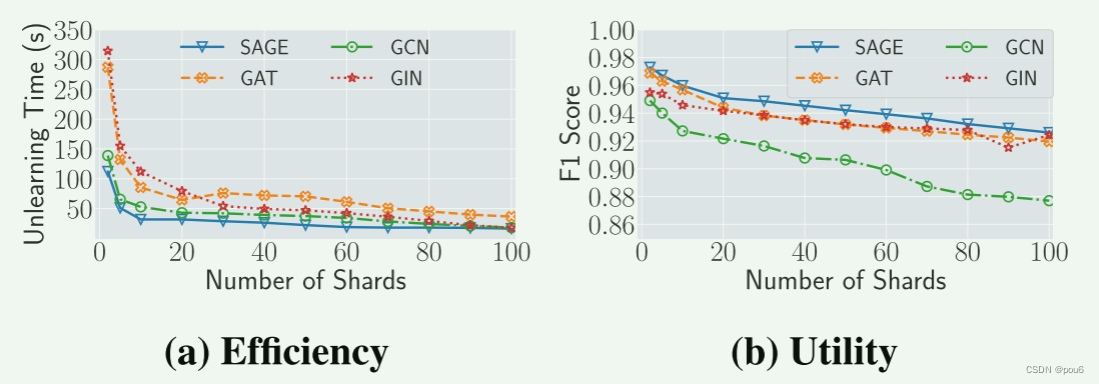
子模型数量增加,unlearning所需时间减少,但是性能下降 ,因为子模型数量太多会打散图中相关联的信息,而其中GCN模型的效用下降最大。怀疑这是因为GCN模型需要节点度信息来进行归一化,而图划分严重减少了节点度信息。
每个分片中的最大节点数δ
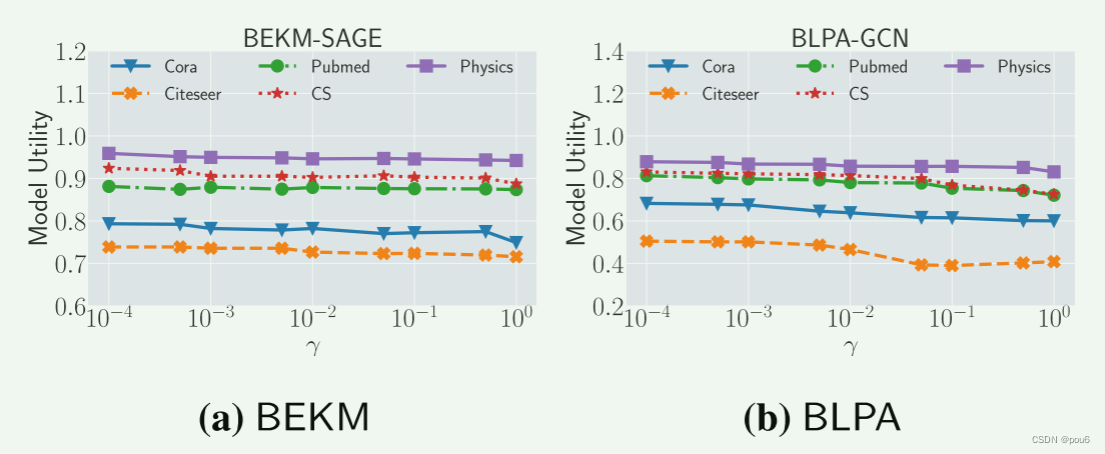
一般来说,我们观察到δ对模型效用只有轻微的影响
社区依赖的删除请求
GraphEraser可以处理来自特定类型社群的遗忘请求,因为它可以被视为社群检测算法的分片大小约束版本,并且特定类型社区中的节点往往被分配到相同的分片中。当社群依赖的请求到来时,只有少数分片模型需要重新训练。
为了进一步验证GraphEraser的鲁棒性,我们使用普通LPA方法(没有社群大小限制)来划分图。然后,我们随机选择一个由普通LPA检测到的社群,并从GraphEraser的碎片模型中逐渐删除相应的节点(在所选社群中具有相同ID)
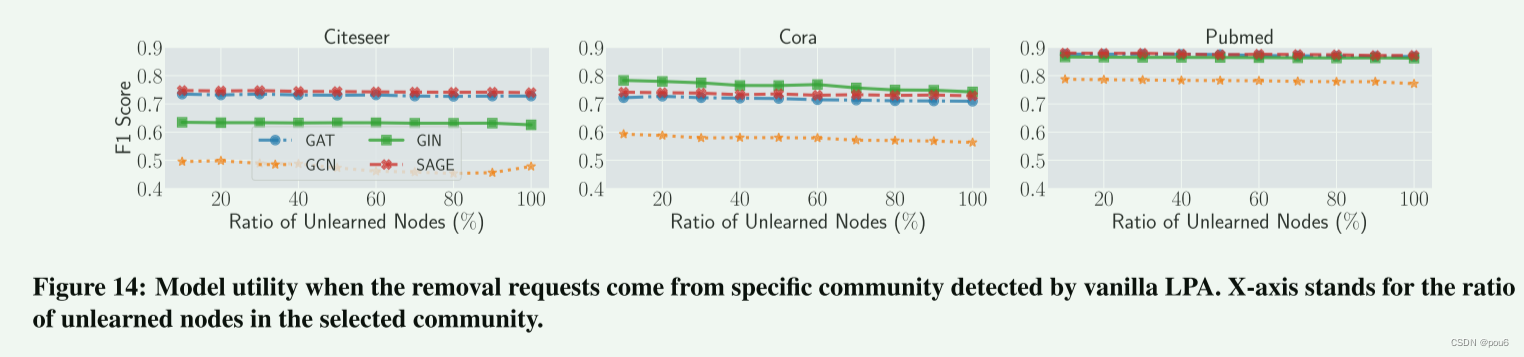
上图说明了当请求来自LPA检测到的特定社区时的模型实用程序。实验结果表明,从单个社区中删除节点不会显著影响GraphEraser的模型效用。

















 1763
1763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









