







Bias在推荐系统中常见,原因如下
(1)用户行为数据是推荐模型训练的基础但它是观察性的,而不是实验性的(观察就是不对研究对象施加实验因素,只收集结果,实验性简单说就是控制变量)。主要原因是这是用户基于推荐的物品产生行为,使得数据受到系统的推荐机制和用户的自我选择的混淆。
(2)物品在数据中的呈现不均匀,例如,某些物品比其它物品更受欢迎,从而有更多的用户互动。因此,这些受欢迎的物品将对模型训练产生更大的影响,使推荐偏向于它们。同样的情况也适用于用户端。
(3)推荐系统本质是一个反馈回路(feedback loop):推荐系统的推荐机制决定用户行为,这些行为被返回作为推荐系统的训练数据。这种反馈回路不仅产生bias,而且随着时间的推移加剧bias,导致“富人更富”的马太效应。
本文贡献:
1.总结了推荐系统中的七种bias类型,并给出了它们的定义和特征。其中,我们特别提供了基于因果关系的数据bias的解释,以帮助读者更好地理解其本质。
2.进行全面的审查,对现有的推荐debias方法进行了分类,以及讨论他们的优点和缺点。
3.确定开放的挑战,并讨论未来的方向,以激发更多的研究。
2.推荐系统和反馈回路
2.1推荐中的反馈回路(feedback loop)
可以将推荐的生命周期抽象为三个关键组件之间的反馈回路:user用户,data数据和model模型。
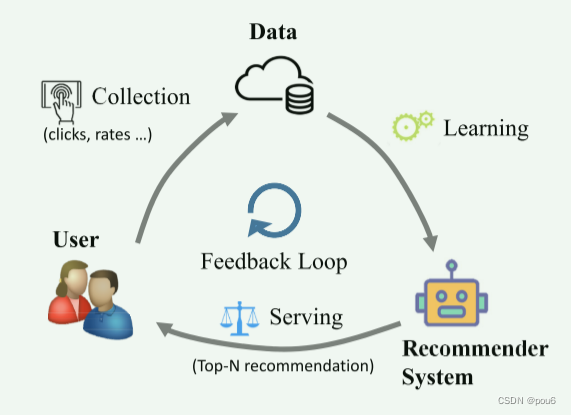
User→Data(采集),表示从用户收集数据的阶段,包括user-item交互和其他辅助信息(例如,用户画像、物品属性和背景等等)。·
Data→Model(学习),表示基于收集的数据学习推荐模型。其核心是从历史交互中获得用户偏好,并预测用户选择目标物品的可能性。在过去几十年中进行了广泛的研究。·
Model→User(服务),将推荐结果返回给用户,以满足用户的信息需求。这个阶段将影响用户未来的行为和决策。
通过这个回路,用户和推荐系统处于相互动态演化的过程中,其中用户的个人兴趣和行为通过推荐得到更新,并且RS可以通过利用更新的数据来自我增强。
2.2 推荐任务的公式
略
3 推荐中的bias
列出反馈回路中不同的几种bias,如图和表所示。然后进行深入的分析
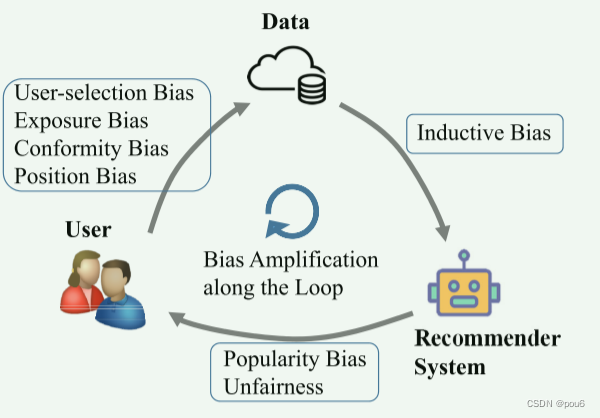
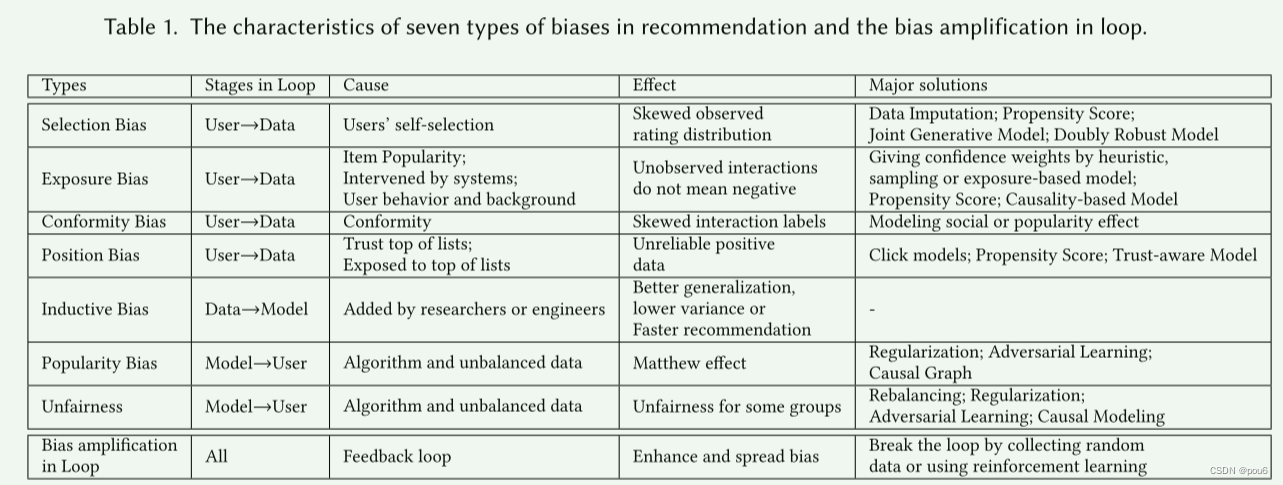
3.1 data bias
由于用户交互的数据是观察性的,而不是实验性的,因此很容易在数据中引入bias。它们通常来自不同的数据分组,并使推荐模型捕捉这些偏见,甚至缩放它们,在本节中,首先给予数据bias的一般定义,然后将其分为四类:selection bias,conformity bias, exposure bias 和 position bias
3.1.1 数据bias定义
定义:收集的训练数据的分布和理想的测试数据分布不同
独立同分布的假设为最近的基于学习的方法在测试环境中很好地推广奠定了基础。然而,这种假设在真实的推荐系统中可能不成立。通常,收集的数据是观察性的,而不是实验性的。样本选择或用户决策不可避免地会受到许多不良因素的影响,如推荐系统的曝光机制或舆情,使训练数据分布偏离测试数据分布。训练数据只能给出用户偏好的带有bias的快照,使推荐模型陷入次优结果。
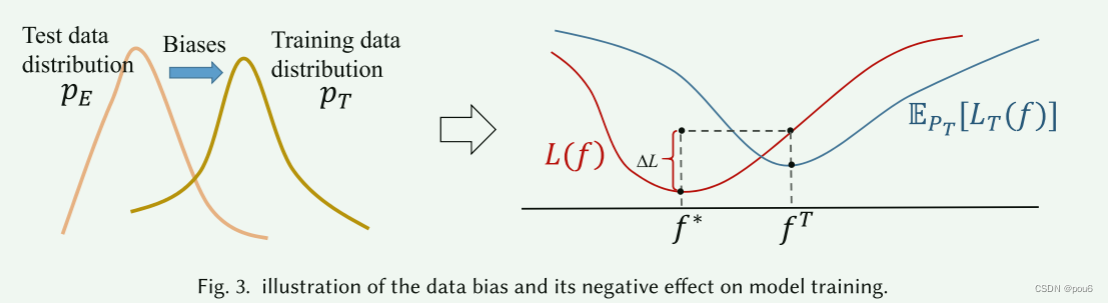
上图说明了数据bias及其负面影响。bias会扭曲训练分布,导致模型流向错误的方向。红色曲线表示测试的真实风险函数,而蓝色曲线表示训练的风险函数。即使在它们的最佳情况下,它们的表现也会相当不同,因为这两种risk的期望分布不同。这意味着,即使提供足够大的训练集,模型到达最佳点f^T,最佳f^*和经验最佳f^T之间仍然存在一定的差距ΔL。盲目地拟合推荐模型而不考虑固有的数据bias将导致较差的性能。
风险函数(risk function)是损失函数在样本空间的概率期望,所以又名期望损失。因为不同样本点的概率可能不同,那么不同样本点带来的损失也可能不一样,风险函数就相当于样本空间中所有样本点带来的损失的加权平均。即,风险函数表示的是总体的平均损失
3.1.2 Selection Bias
选择bias的发生是因为用户可以自由选择要评分的项目,所以观察到的评分并不是所有评分的代表性样本。换句话说,用户更可能对他们感兴趣或者有强烈情感的项目进行评分,而忽视其他项目。这种选择性评价行为会导致推荐系统的训练数据出现bais,因为这些数据并不是从所有用户可能产生的评分中随机抽取的。换句话说,这种评分数据通常是MNAR (Missing Not at Random)
在统计学和数据分析中,处理缺失数据是一个重要的问题。缺失数据的类型通常根据数据缺失的机制来分类。这里提到的MCAR、MAR和MNAR是三种常见的缺失数据机制:
MCAR (Missing Completely at Random):完全随机缺失。在这种情况下,数据的缺失与任何观测值或未观测值都没有关系。也就是说,缺失是完全随机的,不依赖于任何已观测或未观测的数据。这种类型的缺失数据通常被认为是最容易
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









