







本文主要内容为R语言笔记
R语言教程
数据:是指对客观事件进行记录并可以鉴别的符号,是对客观事物的性质、状态以及相互关系等进行记载的物理符号或这些物理符号的组合。
R语言的特点:
1、有效的数据处理和保存机制:
2、拥有一整套数组和矩阵的操作运算符。
3、一系列连贯而又完整的数据分析中间工具。
4、图形统计可以对数据直接进行分析和显示,可用于多种图形设备。
5、一种相当完善、简洁和高效的程序设计语言。
6、R语言是彻底面向对象的统计编程语言。
7、R语言和其它编程语言、数据库之间有很好的接口。
8、语言是自由软件,可以放心大胆地使用,但其功能却不比任何其它同类软件差。
9、R语言具有丰富的网上资源。
R语言官网:httpsmmmmmmmmmfadsfa://www.r-project.org/
推荐书籍:《R语言实战》
常用快捷键:Ctrl + L 清空终端
R语言基础
1.1 R语言的基本功能
在Linux系统中,R语言中可以通过以下命令启动R软件
> R
可以通过以下命令来查找每个命令如何使用:
> R --help
通过以下命令可以获取当前目录:
> getwd()
可以通过Rprofile.site对R软件进行全局设置,Rprofile.site文件地址为D:\R\R-4.2.1\etc,这个文件中通过 # 进行注释,可以在最后通过.First()或者.Last(),当开始运行R软件时会执行.First()中的内容,当关闭R软件时执行.Last()中的内容。
.First()中可以是常用的库,也可以是自己编写的常用函数的源代码文件。
.Last()中可以是保存程序输出或者保存数据文件等。
在Rstudio软件中在命令后加括号进行区分对象和函数,R语法中对象可以是常量、变量,也可以是函数等等,函数必须加括号,便于区分。
可以通过setwd命令设定工作空间(这里是斜线,不是windows的反斜线):
> setwd(dir = "f:/Code/Code_R/R_proj_01")
可以通过list.files()命令查看当前目录下的文件:
> list.files()
R中不需要进行变量申明,可以进行变量赋值和计算,但是变量名不能以数字开头。
在终端中有以下三种赋值方式:
> x <- 3
> 6 -> y
> z = 10
通过xx <<- 9命令对全局变量进行强制赋值:
> xx <<- 9
在终端中通过ls()可以列出当前工作空间的变量:
> ls()
ls()命令是无法看到隐藏文件(以.开头的文件)的。可以通过以下命令查看所有文件(包括隐藏文件):
> ls(all.names = TRUE)
在终端中通过list.files()命令列出当前文件夹下的文件:
> list.files()
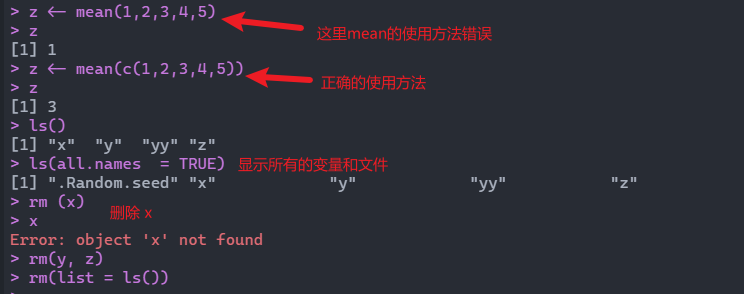
删除变量通过rm命令,如下所示,分别为删除单个变量、多个变量和所有变量:
> rm(x)
> rm(y, z)
> rm(list = ls())
通过Ctrl + L将终端所有代码清屏。
为了避免电脑死机,通过save.image()保存工作空间:
> save.image()
在终端中输入q()退出软件:
> q()
相应的操作结果图如下:
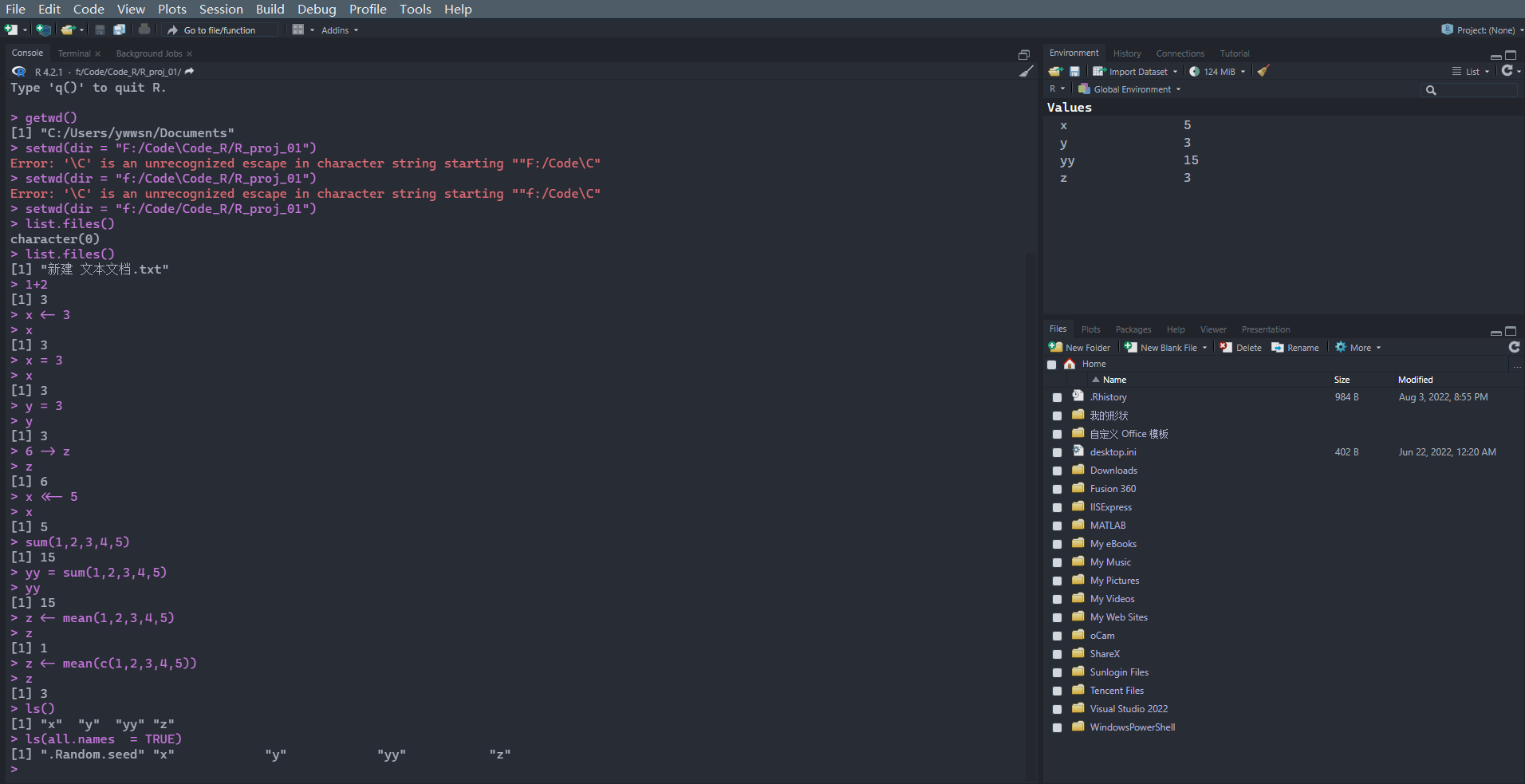
R表达式中常用的符号:

1.2 R包的安装
R包的安装:
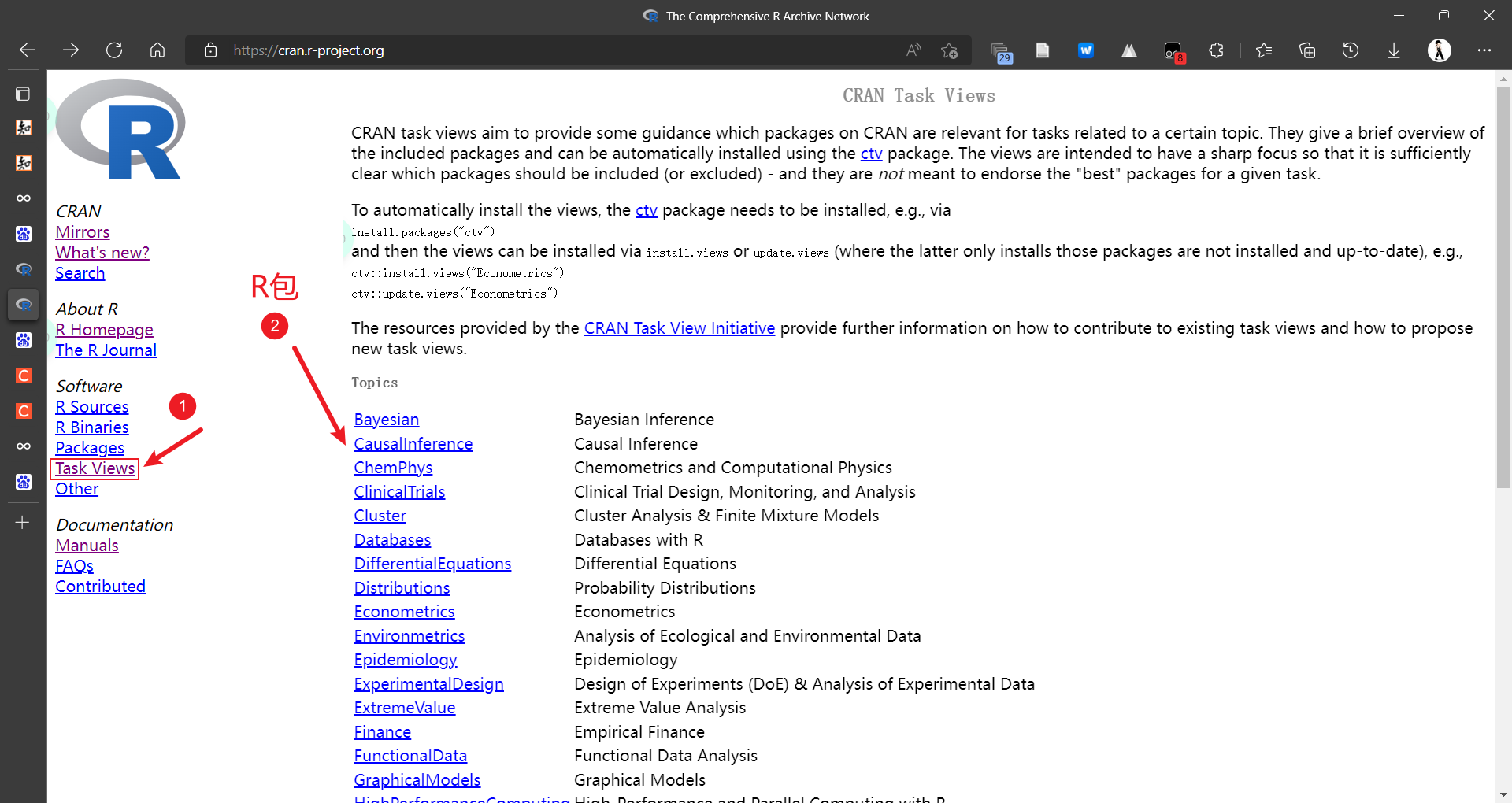
推荐使用在线安装的方式,可以自动安装需要的依赖包。
R中使用字符串要加引号,不加引号会将字符串当作对象处理,程序找不到对象就会报错:
错误用法:
> install.packages(vcd)
正确用法:
> install.packages("vcd")
# 也可以一次性安装多个包
> install.packages(c("tidyr", "dplyr"))

可以通过以下命令查看库所在的位置:
> .libPaths()
也可以通过以下命令查看库中所有的包:
> library()
如果想一次安装多个包,可以通过以下命令:
> install.packages(c("AER","ca"))
使用update.packages()命令可以更新安装的软件包:
> update.packages()
1.3 R包的使用
下载安装完包后,载入包就不需要引号了,如下:
正确用法:
> library(vcd)
或者通过require加载包:
> require(vcd)
R软件自带的包有:base,datasets,utils,grDevices,graphics,stats,methods,splines,stats4,tcltk
base:R基础功能相关的函数
datasets:存放R内置的数据集
grDevices:基于grid绘图相关的设备
graphics:基于base图形的R函数,R的绘图函数都在这个包中
methods:R语言一般的定义方法和类
这些包提供了种类繁多的函数和数据集,这些包集合在一起构成了R软件。
通过帮助文档进行R包的学习和使用:
> help(package = "vcd")
也可以通过以下命令查看包的基础信息:
> library(help = "vcd")
可以通过ls("package:函数包名")查看包的所有函数,例如:
> ls("package:vcd")
可以通过data("package:函数包名")查看包的所有数据集,例如:
> data("package:vcd")
可以通过detach("package:函数包名")移除加载的包,例如:
> detach("package:vcd")
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sn6l6PD9-1688349485068)(https://vip2.loli.io/2023/03/13/cpHMjX4SDNw7R6v.png)]
可以通过remove.packages函数彻底删除包:
> remove.packages("vcd")
将R包迁移到新设备,通过以下步骤进行操作:
- 列出当前环境已安装的包
> installed.packages()
- 取第1列,即所有包的名字,并保存给变量
Rpack
> Rpack <- installed.packages()[,1]
- 将所有的包保存到
Rpack.Rdata文件中
> save(Rpack,file="Rpack.Rdata")
- 将
Rpack.Rdata文件移入新设备,在新设备上R软件终端中通过以下命令安装R包:
> for(i in Rpack) install.packages(i)
即使新设备已经安装了包,R会自动跳过已经安装的包。
1.4 获取帮助
R软件的帮助文档可以通过help命令进行查看:
> help.start()
或者通过菜单栏中的help进行查看。
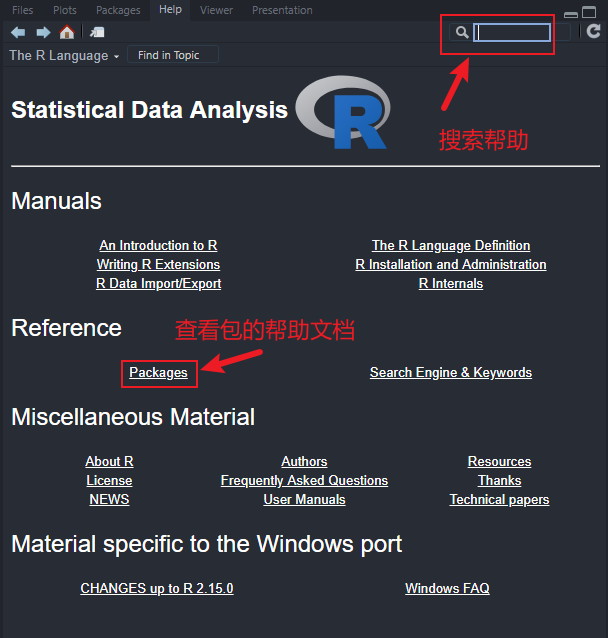
示例:在终端中
> help(sum)
或者?也可以:
> ?sum
运行结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pKf96VZt-1688349485069)(https://vip2.loli.io/2023/03/13/QYNkfedgmvR8qCO.png)]
如果想直接了解函数中的参数,可以通过args函数:
> args(plot)
在帮助文档中可以根据example中示例进行学习,也可以在终端中输入example进行实例展示:
> example("mean")
也可以通过以下命令展示绘图demo:
> demo(graphics)
如果想查看某个包的帮助文档,可以通过如下命令:
> help(package=vcd)
有些R包包含vignette文档,这个文档包含简介,教程文档等,但也并不是所有的包都有:
> vignette("xts")
有时候明明已经安装了包,但是help搜索不到相应的函数,这是因为相关的包并没有加载,需要通过library进行加载,如果不加载,可以通过以下方式搜索:
-
通过包的名字:
help(package = vcd) -
需要通过双问号命令进行搜索,例如:
> ??qplot
有些情况下不知道函数名,可以通过help.search进行本地模糊搜索:
> help.search("heatmap")
这里的help.search可以通过??来简写:
> ??heatmap
apropos函数可以列出所有包含关键字的内容,例如:
> apropos("sum")
apropos函数也可以限定搜索范围,比如仅仅对函数进行搜索:
> apropos("sum",mod="function")
也可以通过RSiteSearch进行官网搜索:
> RSiteSearch("matlab")
注意:help.search为本地搜索
也可以通过 https://rseek.org/ 进行搜索,前提是要能够使用Google搜索。
1.5 内置数据集
R软件内置数据集存放在datasets中,某人加载这个包。
可以通过help查看数据集的具体内容:
> help("mtcars")
可以将一些数据组成数据框,示例:
> state <- data.frame(state.name,state.abb,state.area,state.division,state.region)
> state
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A6TapjGk-1688349485069)(https://vip2.loli.io/2023/03/13/7VElopxwPv18OhX.png)]
有些数据集可以绘制对应的热图:
> heatmap(volcano)
可以通过如下操作查看某个包中的数据集:
> data(package="MASS")
可以通过如下操作查看R软件中所有数据集(包括自己安装的包的数据集):
> data(package=.packages(all.available = TRUE))
如果不想加载某个数据集,但是想用其数据集,可以通过以下命令(Chile为数据集,car为包名):
> data(Chile,package="car")
2 数据结构
R语言中最重要的概念是对象。
对象:object,它是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。对象都拥有某个模式,描述了此对象是如何存储的,以及某个类。
2.1 向量
向量,vector,是R中最重要的一个概念,它是构成其他数据结构的基础。R中的向量概念与数学中向量是不同的,类似于数学上的集合的概念,由一个或多个元素构成。
向量其实是用于存储数值型、字符型或逻辑型数据结构的一维数组。
用函数c来创建向量。c代表concatenate连接,也可以理解为收集collect,或者合并combine,例如:
> x <- c(1,2,3,4,5)
这里的x就是向量,也可以称为对象。
在R语言中字符串要加引号,如果不加引号,就会把字符串当成对象。
> y <- c("one","two","three")
对于逻辑型变量用TRUE、FALSE、T、F进行表示:
> z <- c(TRUE FALSE TRUE FALSE)
不能够用首字母大写的模式,如 True 或 False。
用冒号构建等差数列:
> c(1:100)
如果想调整等差数列的差值,可以通过seq函数:
> seq(from=1,to=100,by=2)
如果想等差生成10个值,可以通过如下方式:
> seq(from=1,to=100,length.out=10)
如果想要输出重复的数值,可以通过rep函数,比如重复5次2:
> rep(2,5)
还有其他用法:x = 1 2 3 4 5
将x向量依次重复5次:
> rep(x,5)
输出:1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
将x向量每个元素重复5次:
> rep(x,each=5)
输出:1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5
将x向量每个元素依次重复五次,并执行两次:
> rep(x,each=5,times=2)
输出:1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5
示例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dgDytXsJ-1688349485069)(https://vip2.loli.io/2023/03/13/Bw5dmfYPoKODkGj.png)]
向量的数据类型都是同一类型,都是数值型或者字符型。如果不是同一类型,会自动将其转换为同一类型:
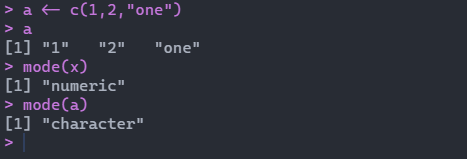
通过如果想要查看变量的类型,可以通过mode函数进行查看。
如果想要提取出x中大于3的值:
> x[x>3]
输出:4 5
例如前面的重复,也可以进行批量处理:
> rep(x,c(2,4,6,1,3))
输出:1 1 2 2 2 2 3 3 3 3 3 3 4 5 5 5
2.2 向量索引
可以用length统计向量的长度,R中元素序列是从0开始。
x[-19]表示不显示第19个数值。
x[c(1,23,45,67,89)]表示输出对应位置的数值
> y <- c(1:10)
[1] 1 2 3 4 5 6 7 8 9 10
> y[c(T,F,T,F,T,F,T,F,T,F)]
[1] 1 3 5 7 9
> y[c(T,F,T,F,T,F,T,F,T,F)]
[1] 1 3 5 7 9
> y[c(T,F)]
[1] 1 3 5 7 9
> y[c(T,F,F)]
[1] 1 4 7 10
> y[y>5]
[1] 6 7 8 9 10
> y[y>5 & y<9]
[1] 6 7 8
> z <- c("one","two","three","four","five")
> z
[1] "one" "two" "three" "four" "five"
> "one" %in% z
[1] TRUE
> z[z %in% c("one","two")]
[1] "one" "two"
> z %in% c("one","two")
[1] TRUE TRUE FALSE FALSE FALSE
> k <- z %in% c("one","two")
> z[k]
[1] "one" "two"
也可以通过names函数对变量进行命名:
> y <- c(1,2,3,4,5,6,7,8,9,10)
> y
[1] 1 2 3 4 5 6 7 8 9 10
> names(y) <- c("one","two","three","four","five","six","seven","eight","nine","ten")
> y
[1] one two three four five six seven eight nine ten
[2] 1 2 3 4 5 6 7 8 9 10
> y["two"]
[1] two
[2] 2
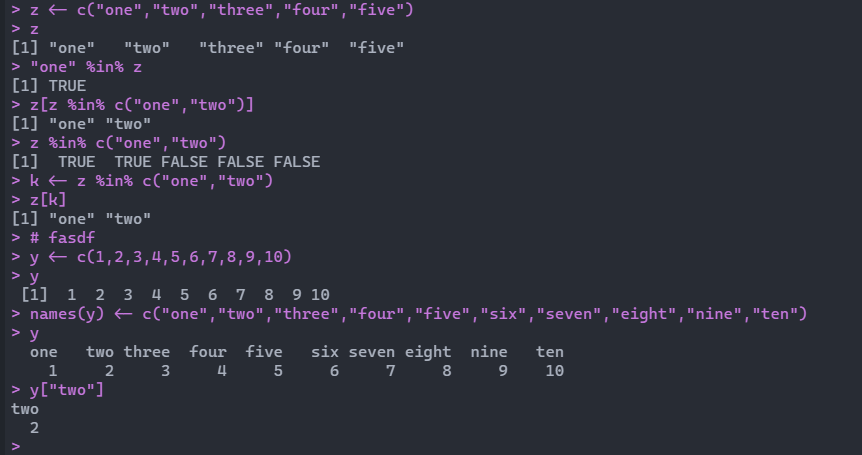
添加和删除元素:x为1到100的向量
> x[101] <- 101
> x
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
[31] 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
[61] 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
[91] 91 92 93 94 95 96 97 98 99 100 101
还可以通过以下方式添加向量:
> v <- 1:3
> v
[1] 1 2 3
> v[c(4,5,6)] <- c(4,5,6)
> v
[1] 1 2 3 4 5 6
> v[20] <- 4
> v
[1] 1 2 3 4 5 6 NA NA NA NA NA NA NA NA NA NA NA NA NA 4
> append(x = v, values = 99, after = 5)
[1] 1 2 3 4 5 99 6 NA NA NA NA NA NA NA NA NA NA NA NA NA 4
> append(x = v, values = 88, after = 0)
[1] 88 1 2 3 4 5 6 NA NA NA NA NA NA NA NA NA NA NA NA NA 4
如果想要删除某个元素:
方法一:
rm(v)
方法二:通过不显示想删除的部分,然后赋值给自身就相当于删除部分元素了
y <- y[-c(1:3)]
如果想替换某个元素:
y["four"] <- 100
不能够将字符串赋值给数值,否则都会变成字符串。
2.3 向量运算
向量的基本用法:
> x <- 1:10
> x
[1] 1 2 3 4 5 6 7 8 9 10
> x+1
[1] 2 3 4 5 6 7 8 9 10 11
> x-3
[1] -2 -1 0 1 2 3 4 5 6 7
> x <- x+1
> x
[1] 2 3 4 5 6 7 8 9 10 11
总结:+为给所有元素相加某一值
> x
[1] 2 3 4 5 6 7 8 9 10 11
> y <- seq(1,100,length.out = 10)
> y
[1] 1 12 23 34 45 56 67 78 89 100
> x*y
[1] 2 36 92 170 270 392 536 702 890 1100
> x**2
[1] 4 9 16 25 36 49 64 81 100 121
> x^2
[1] 4 9 16 25 36 49 64 81 100 121
> x%%y
[1] 0 3 4 5 6 7 8 9 10 11
> x%/%5
[1] 0 0 0 1 1 1 1 1 2 2
总结:*为元素相乘符,**和^均为幂运算,%%为取余符号,%/%为整除符号。
> z <- c(1,2)
> z
[1] 1 2
> x
[1] 2 3 4 5 6 7 8 9 10 11
> x+z
[1] 3 5 5 7 7 9 9 11 11 13
> x = c(1,2,3)
> x
[1] 1 2 3
> x+z
[1] 2 4 4
Warning message:
In x + z : longer object length is not a multiple of shorter object length
总结:长的向量和短的向量相加,长的向量中元素个数必须为短的向量个数的整数倍。
> x <- 1:10
> x
[1] 1 2 3 4 5 6 7 8 9 10
> y <- seq(1,100,length.out = 10)
> y
[1] 1 12 23 34 45 56 67 78 89 100
> x>5
[1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE
> x>y
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
> c(1,2,3) %in% c(1,2,2,4,5,6)
[1] TRUE TRUE FALSE
> x
[1] 1 2 3 4 5 6 7 8 9 10
> y
[1] 1 12 23 34 45 56 67 78 89 100
> x==y
[1] TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
> x <- -5:5
> x
[1] -5 -4 -3 -2 -1 0 1 2 3 4 5
> abs(x)
[1] 5 4 3 2 1 0 1 2 3 4 5
> sqrt(25)
[1] 5
> log(16,base = 2)
[1] 4
> log(16)
[1] 2.772589
> log(16,base = 10)
[1] 1.20412
> log10(10)
[1] 1
> x
[1] -5 -4 -3 -2 -1 0 1 2 3 4 5
> exp(x)
[1] 6.737947e-03 1.831564e-02 4.978707e-02 1.353353e-01 3.678794e-01 1.000000e+00 2.718282e+00 7.389056e+00 2.008554e+01
[10] 5.459815e+01 1.484132e+02
> ceiling(c(-2.3,3.1415))
[1] -2 4
> floor(c(-2.3,3.1415))
[1] -3 3
> trunc(c(-2.3,3.1415))
[1] -2 3
> round(c(-2.3,3.1415))
[1] -2 3
> round(c(-2.3,3.1415),digits = 2)
[1] -2.30 3.14
> signif(c(-2.3,3.1415),digits = 2)
[1] -2.3 3.1
> sin(x)
[1] 0.9589243 0.7568025 -0.1411200 -0.9092974 -0.8414710 0.0000000 0.8414710 0.9092974 0.1411200 -0.7568025 -0.9589243
> cos(x)
[1] 0.2836622 -0.6536436 -0.9899925 -0.4161468 0.5403023 1.0000000 0.5403023 -0.4161468 -0.9899925 -0.6536436 0.2836622
总结:log(x)默认为以常数e为底的自然对数,log10(x)为以10为底的对数,log(16,base = 10)为以10为底的10的对数,exp表示以e为底的指数,ceiling为大于给定值的最小整数,floor为小于给定值的最大整数,trunc为给定值的整数部分,round为给定值四舍五入,默认为整数,如果设定值digits为2,则为保留两个小数。signif和round功能类似,如果digits为2时,表示保留两位有效数字,sin和cos分别为正弦函数和余弦函数。
> vec <- 1:100
> vec
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
[31] 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
[61] 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
[91] 91 92 93 94 95 96 97 98 99 100
> sum(vec)
[1] 5050
> max(vec)
[1] 100
> min(vec)
[1] 1
> range(vec)
[1] 1 100
> mean(vec)
[1] 50.5
> var(vec)
[1] 841.6667
> round(var(vec))
[1] 842
> round(var(vec),digits = 2)
[1] 841.67
> round(sd(vec),digits = 2)
[1] 29.01
> prod(vec)
[1] 9.332622e+157
> quantile(vec)
0% 25% 50% 75% 100%
1.00 25.75 50.50 75.25 100.00
> quantile(vec,c(0.4,0.5,0.8))
40% 50% 80%
40.6 50.5 80.2
总结:sum返回向量的求和,max返回向量最大值,min返回向量最小值,range返回向量最小值和最大值,mean返回向量均值,var返回向量方差,sd返回向量标准差,prod返回向量连乘的积。quantile为计算分位数中的值,quantile(vec,c(0.4,0.5,0.8))为计算四分位、中位和八分位数。
> t <- c(1,4,2,5,7,9,6)
> t
[1] 1 4 2 5 7 9 6
> which.max(t)
[1] 6
> which.min(t)
[1] 1
> which(t==7)
[1] 5
> which(t>5)
[1] 5 6 7
> t[which(t>5)]
[1] 7 9 6
总结:which返回的是对应的位置,which.max(t)返回最大值对应的位置,which.min(t)返回最小值对应的位置,which(t==7)返回数值为7的元素对应的位置,which(t>5)返回t>5对应的元素的位置,t[which(t>5)]返回t>5对应的元素。
2.4 矩阵
矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合。向量是一维的,而矩阵是二维的,需要有行和列。
在R软件中,矩阵是有维数的向量,这里的矩阵元素可以是数值型,字符型或者逻辑型,但是每个元素必须都拥有相同的模式,这个和向量一致。
矩阵相关操作如下:
> x<- 1:20
> x
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> m <-matrix(x,nrow = 4,ncol = 5)
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> t <- matrix(1:20,4,5)
> t
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> t <- matrix(1:20,4)
> t
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> t <- matrix(1:20,4,byrow = T)
> t
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 6 7 8 9 10
[3,] 11 12 13 14 15
[4,] 16 17 18 19 20
总结:可以通过matrix创建矩阵,需要自己设定行数或者列数,也可以只设定列数或行数,默认按照列进行排列,如果byrow为T则按照行进行排列。
> m <-matrix(x,nrow = 4,ncol = 5)
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> rnames <- c("R1","R2","R3","R4")
> rnames
[1] "R1" "R2" "R3" "R4"
> cnames <- c("C1","C2","C3","C4","C5")
> cnames
[1] "C1" "C2" "C3" "C4" "C5"
> dimnames(m) <- list(rnames,cnames)
> m
C1 C2 C3 C4 C5
R1 1 5 9 13 17
R2 2 6 10 14 18
R3 3 7 11 15 19
R4 4 8 12 16 20
> x <- 1:20
> x
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> dim(x)
NULL
> dim(x) <- c(4,5)
> x
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
总结:可以通过dimnames给矩阵的行和列进行命名,也可以通过dim将向量变为矩阵。
数组:示例1
> x <- 1:20
> dim(x)
NULL
> dim(x) <- c(2,2,5)
> x
, , 1
[,1] [,2]
[1,] 1 3
[2,] 2 4
, , 2
[,1] [,2]
[1,] 5 7
[2,] 6 8
, , 3
[,1] [,2]
[1,] 9 11
[2,] 10 12
, , 4
[,1] [,2]
[1,] 13 15
[2,] 14 16
, , 5
[,1] [,2]
[1,] 17 19
[2,] 18 20
示例2:
> dim1 <- c("A1","A2")
> dim2 <- c("B1","B2","B3")
> dim3 <- c("C1","C2","C3","C4")
> z <- array(1:24,c(2,3,4),dimnames = list(dim1,dim2,dim3))
> z
, , C1
B1 B2 B3
A1 1 3 5
A2 2 4 6
, , C2
B1 B2 B3
A1 7 9 11
A2 8 10 12
, , C3
B1 B2 B3
A1 13 15 17
A2 14 16 18
, , C4
B1 B2 B3
A1 19 21 23
A2 20 22 24
总结:可以通过array创建矩阵,同时给矩阵命名。
读取矩阵中的元素,示例:
> m <- matrix(1:20,4,5,byrow = T)
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 6 7 8 9 10
[3,] 11 12 13 14 15
[4,] 16 17 18 19 20
> m[1,2]
[1] 2
> m[1,c(2,3,4)]
[1] 2 3 4
> m[c(2:4),c(2,3)]
[,1] [,2]
[1,] 7 8
[2,] 12 13
[3,] 17 18
> m[2,]
[1] 6 7 8 9 10
> m[,2]
[1] 2 7 12 17
> m[2]
[1] 6
> m[3]
[1] 11
> m[-1,2]
[1] 7 12 17
> rnames <- c("R1","R2","R3","R4")
> rnames
[1] "R1" "R2" "R3" "R4"
> cnames <- c("C1","C2","C3","C4","C5")
> cnames
[1] "C1" "C2" "C3" "C4" "C5"
> dimnames(m)=list(rnames,cnames)
> m
C1 C2 C3 C4 C5
R1 1 2 3 4 5
R2 6 7 8 9 10
R3 11 12 13 14 15
R4 16 17 18 19 20
> m["R1","C2"]
[1] 2
sum(m)
[1] 210
> colSums(m)
C1 C2 C3 C4 C5
34 38 42 46 50
> rowSums(m)
R1 R2 R3 R4
15 40 65 90
> colMeans(m)
C1 C2 C3 C4 C5
8.5 9.5 10.5 11.5 12.5
> rowMeans(m)
R1 R2 R3 R4
3 8 13 18
矩阵的内积和外积:
> n <- matrix(1:9,3,3)
> w <- matrix(2:10,3,3)
> n
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> w
[,1] [,2] [,3]
[1,] 2 5 8
[2,] 3 6 9
[3,] 4 7 10
> n*w
[,1] [,2] [,3]
[1,] 2 20 56
[2,] 6 30 72
[3,] 12 42 90
> n %*% w
[,1] [,2] [,3]
[1,] 42 78 114
[2,] 51 96 141
[3,] 60 114 168
> diag(n)
[1] 1 5 9
> t(n)
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
总结:函数内积可通过*将矩阵对应位置进行相乘,外积可以通过%*%符号实现,矩阵对角线的值可以通过diag取得,函数t可以对矩阵进行转置。
2.5 列表
列表就是用来存储很多内容的一个集合,在其他编程语言中,列表一般和数组是等同的,但是在R语言中,列表却是最复杂的一种数据结构,也是非常重要的一种数据结构。
列表是一些对象的有序集合。列表中可以存储若干向量、矩阵、数据框,甚至其他列表的组合。
向量与类表:
- 在模式上和向量类似,都是一维数据集合。
- 向量智能存储一种数据类型,列表中的对象可以是R中的任何数据结构,甚至列表本身。
示例:mtcars为数据集
> a <- 1:20
> b <- matrix(1:20,4)
> c <- mtcars
> d <- "This is a test list"
> mlist<- list(a,b,c,d)
> mlist
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[[2]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
[[3]]
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
...
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
[[4]]
[1] "This is a test list"
> mlist <- list(first=a,second=b,third=c,forth=d)
> mlist
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
$second
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
$third
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
...
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
$forth
[1] "This is a test list"
> mlist[1]
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> mlist[c(1,4)]
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
$forth
[1] "This is a test list"
总结:可以通过以上的方式进行命名,并根据需要输出相关内容。
> state.center[c("x","y")]
$x
[1] -86.7509 -127.2500 -111.6250 -92.2992 -119.7730 -105.5130 -72.3573 -74.9841 -81.6850 -83.3736 -126.2500 -113.9300
[13] -89.3776 -86.0808 -93.3714 -98.1156 -84.7674 -92.2724 -68.9801 -76.6459 -71.5800 -84.6870 -94.6043 -89.8065
[25] -92.5137 -109.3200 -99.5898 -116.8510 -71.3924 -74.2336 -105.9420 -75.1449 -78.4686 -100.0990 -82.5963 -97.1239
[37] -120.0680 -77.4500 -71.1244 -80.5056 -99.7238 -86.4560 -98.7857 -111.3300 -72.5450 -78.2005 -119.7460 -80.6665
[49] -89.9941 -107.2560
$y
[1] 32.5901 49.2500 34.2192 34.7336 36.5341 38.6777 41.5928 38.6777 27.8744 32.3329 31.7500 43.5648 40.0495 40.0495 41.9358
[16] 38.4204 37.3915 30.6181 45.6226 39.2778 42.3645 43.1361 46.3943 32.6758 38.3347 46.8230 41.3356 39.1063 43.3934 39.9637
[31] 34.4764 43.1361 35.4195 47.2517 40.2210 35.5053 43.9078 40.9069 41.5928 33.6190 44.3365 35.6767 31.3897 39.1063 44.2508
[46] 37.5630 47.4231 38.4204 44.5937 43.0504
总结:可以通过命名提取相应的列表
> mlist$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> mlist[1]
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> mlist[[1]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> class(mlist[[1]])
[1] "integer"
> class(mlist[1])
[1] "list"
总结:可以通过class查看数据类型,mlist[1]和mlist[[1]]是不同的数据类型。
> mlist <- mlist[-3]
> mlist
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
$second
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
$forth
[1] "This is a test list"
> mlist[2] <- NULL
> mlist
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
$forth
[1] "This is a test list"
总结:可以通过负号去掉不需要的部分,然后赋值给自身,这样可以删除部分列表内容。或者给相应的列表置空。first、second和forth只是名称并不代表相应的顺序。
2.6 数据框
数据框是一种表格式的数据结构。数据框旨在模拟数据集,与其他统计软件如SAS或者SPSS中的数据集的概念一致。
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。不同的行业对于数据集的行和列的叫法不同。
数据框实际上是一个列表,列表中的元素是向量,这些向量构成数据框的列,每一列必须具有相同的长度,所以数据框是矩形结构,而且数据框的列必须命名。
矩阵和数据框:
- 数据框形状上很像矩阵;
- 数据框是比较规则的列表;
- 矩阵必须为同一数据类型;
- 数据框每一列必须同一类型,每一行可以不同。
> state <- data.frame(state.name,state.abb,state.region,state.x77)
> state
总结:通过data.frame将向量组成数据框。
state[c(2,4)]
state[,"state.abb"]
state["Alabama",]
state$state.abb
总结:通过以上方式可以提取相关行或列中的数据。
示例:
> women
height weight
1 58 115
2 59 117
3 60 120
4 61 123
5 62 126
6 63 129
7 64 132
8 65 135
9 66 139
10 67 142
11 68 146
12 69 150
13 70 154
14 71 159
15 72 164
> plot(women$height,women$weight)
运行结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f7wDKlGe-1688349485070)(https://vip2.loli.io/2023/03/13/yCSWdJP6ghZiDUr.png)]
在lm函数进行线性回归的时候,直接给出列名即可:
> lm(height~weight,data = women)
Call:
lm(formula = height ~ weight, data = women)
Coefficients:
(Intercept) weight
25.7235 0.2872
R语言中提供了attach函数,将数据框加载到搜索框中,不需要再使用$符号,直接输入列的名字即可:
> attach(mtcars)
> mpg
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3
[25] 19.2 27.3 26.0 30.4 15.8 19.7 15.0 21.4
> colnames(mtcars)
[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb"
> rownames(mtcars)
[1] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" "Hornet Sportabout"
[6] "Valiant" "Duster 360" "Merc 240D" "Merc 230" "Merc 280"
[11] "Merc 280C" "Merc 450SE" "Merc 450SL" "Merc 450SLC" "Cadillac Fleetwood"
[16] "Lincoln Continental" "Chrysler Imperial" "Fiat 128" "Honda Civic" "Toyota Corolla"
[21] "Toyota Corona" "Dodge Challenger" "AMC Javelin" "Camaro Z28" "Pontiac Firebird"
[26] "Fiat X1-9" "Porsche 914-2" "Lotus Europa" "Ford Pantera L" "Ferrari Dino"
[31] "Maserati Bora" "Volvo 142E"
> detach(mtcars)
也可以使用with实现数据集的调用:
> with(mtcars,{hp})
[1] 110 110 93 110 175 105 245 62 95 123 123 180 180 180 205 215 230 66 52 65 97 150 150 245 175 66 91 113 264 175
[31] 335 109
> with(mtcars,{mpg})
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3
[25] 19.2 27.3 26.0 30.4 15.8 19.7 15.0 21.4
> with(mtcars,{sum(mpg)})
[1] 642.9
单双中括号的区别:

2.7 因子
变量分类:
- 名义型变量
- 有序型变量
- 连续型变量
因子:在R中名义型变量和有序型变量称为因子,factor。这些分类变量的可能值成为一个水平,level,例如good、better、better,都称为一个level。由这些水平值构成的向量就称为因子。因子本身也是一个向量,一个集合,只不过里面的元素可以用来分类。
> mtcars
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
...
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
> mtcars$cyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
> table(mtcars$cyl)
4 6 8
11 7 14
> table(mtcars$am)
0 1
19 13
总结:上面的4、6、8并不是因子,而是cyl这一列可以当作因子类型来处理,4、6或8为一个level。使用table函数进行频数统计。
> f <- factor(c("red","red","green","blue","green","blue","blue"))
> f
[1] red red green blue green blue blue
Levels: blue green red
> week <- factor(c("Mon","Fri","Thu","Wed","Mon","Fri","Sun"))
> week
[1] Mon Fri Thu Wed Mon Fri Sun
Levels: Fri Mon Sun Thu Wed
> week <- factor(c("Mon","Fri","Thu","Wed","Mon","Fri","Sun"),ordered = T,levels = c("Mon","Tue","Wed","Thu","Fri","Sat","Sun"))
> week
[1] Mon Fri Thu Wed Mon Fri Sun
Levels: Mon < Tue < Wed < Thu < Fri < Sat < Sun
> fcyl <- factor(mtcars$cyl)
> fcyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
Levels: 4 6 8
> plot(mtcars$cyl)
> plot(factor(mtcars$cyl))
总结:可以通过factor创建因子类型。有序型变量也可以作为因子。fcyl <- factor(mtcars$cyl)可以将cyl向量变为因子。向量输出的是散点图,而因子输出的是条形图。
> num <- 1:100
> num
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
[31] 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
[61] 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
[91] 91 92 93 94 95 96 97 98 99 100
> cut(num,c(seq(0,100,10)))
[1] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (10,20] (10,20] (10,20]
[14] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30]
[27] (20,30] (20,30] (20,30] (20,30] (30,40] (30,40] (30,40] (30,40] (30,40] (30,40] (30,40] (30,40] (30,40]
[40] (30,40] (40,50] (40,50] (40,50] (40,50] (40,50] (40,50] (40,50] (40,50] (40,50] (40,50] (50,60] (50,60]
[53] (50,60] (50,60] (50,60] (50,60] (50,60] (50,60] (50,60] (50,60] (60,70] (60,70] (60,70] (60,70] (60,70]
[66] (60,70] (60,70] (60,70] (60,70] (60,70] (70,80] (70,80] (70,80] (70,80] (70,80] (70,80] (70,80] (70,80]
[79] (70,80] (70,80] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (90,100]
[92] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100]
Levels: (0,10] (10,20] (20,30] (30,40] (40,50] (50,60] (60,70] (70,80] (80,90] (90,100]
> class(cut(num,c(seq(0,100,10))))
[1] "factor"
通过cut可以统计每个区间分别有多少。
2.8 缺失数据
缺失数据的分类
统计学家通常将缺失数据分为三类。它们都用概率术语进行描述,但思想都非常直观。我们将用sleep研究中对做梦时长的测量(有12个动物有缺失值)来依次阐述三种类型。
- 完全随机缺失若某变量的缺失数据与其他任何观测或未观测变量都不相关,则数据为完全随机缺失(MCAR)。若12个动物的做梦时长值缺失不是由于系统原因,那么可认为数据是MCAR。注意,如果每个有缺失值的变量都是MCAR,那么可以将数据完整的实例看做是对更大数据集的一个简单随机抽样。
- 随机缺失若某变量上的缺失数据与其他观测变量相关,与它自己的未观测值不相关,则数据为随机缺失(MAR)。例如,体重较小的动物更可能有做梦时长的缺失值(可能因为较小的动物较难观察),“缺失”与动物的做梦时长无关,那么该数据就可以认为是MAR。
此时,一旦你控制了体重变量,做梦时长数据的缺失与出现将是随机的。 - 非随机缺失若缺失数据不属于MCAR或MAR,则数据为非随机缺失(NMAR)。例如,做梦时长越短的动物也更可能有做梦数据的缺失(可能由于难以测量时长较短的事件),那么数据可认为是NMAR。
为何会出现缺失数据:
- 机器断电,设备故障导致某个测量值发生了丢失。
- 测量根本没有发生,例如在做调查问卷时,有些问题没有回答,或者有些问题是无效回答等。
缺失值NA
在R中,NA代表缺失值,NA是不可用,not available的简称,用来存储缺失信息。
这里缺失值NA表示没有,但注意没有并不一定就是0,NA是不知道是多少,也能是0,也可能是任何值,缺失值和值为0是完全不同的。
> 1+NA
[1] NA
> NA==0
[1] NA
在运行中NA的处理:
> a <- c(NA,1:49)
> a
[1] NA 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
[42] 41 42 43 44 45 46 47 48 49
> sum(a)
[1] NA
> mean(a)
[1] NA
> sum(a,na.rm = TRUE)
[1] 1225
> mean(a,na.rm = TRUE)
[1] 25
> mean(1:49)
[1] 25
> is.na(a)
[1] TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[21] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[41] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
总结:可以通过na.rm将NA进行剔除,剔除后,不会将NA的位置保留进行计算。通过is.na判断是否存在NA。
> c
[1] NA 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 NA NA
> d <- na.omit(c)
> d
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
attr(,"na.action")
[1] 1 22 23
attr(,"class")
[1] "omit"
> is.na(d)
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
> sum(d)
[1] 210
> mean(d)
[1] 10.5
> na.omit(sleep)
BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger
2 1.000 6.60 6.3 2.0 8.3 4.5 42.0 3 1 3
5 2547.000 4603.00 2.1 1.8 3.9 69.0 624.0 3 5 4
6 10.550 179.50 9.1 0.7 9.8 27.0 180.0 4 4 4
7 0.023 0.30 15.8 3.9 19.7 19.0 35.0 1 1 1
8 160.000 169.00 5.2 1.0 6.2 30.4 392.0 4 5 4
...
57 0.900 2.60 11.0 2.3 13.3 4.5 60.0 2 1 2
58 2.000 12.30 4.9 0.5 5.4 7.5 200.0 3 1 3
59 0.104 2.50 13.2 2.6 15.8 2.3 46.0 3 2 2
60 4.190 58.00 9.7 0.6 10.3 24.0 210.0 4 3 4
61 3.500 3.90 12.8 6.6 19.4 3.0 14.0 2 1 1
总结:可以通过na.omit(sleep)将数据框中的NA对应的这一行的数据删除。
> length(rownames(sleep))
[1] 62
> length(rownames(na.omit(sleep)))
[1] 42
但是这样也会出现问题,比如NA占据的行数有一半,则会导致大量数据丢失,影响分析结果。
R提供了多种处理缺失值的方法:

其他缺失数据:
- 缺失数据NaN,代表不可能的值;
- Inf代表无穷,分为正无穷Inf和负无穷-Inf,代表无穷大或者无穷小。
不同缺失值之间的差别:
- NA是存在的值,但是不知道是多少;
- NaN是不存在的;
- Inf存在,是无穷大或者无穷小,但是表示不可能的值。
> 1/0
[1] Inf
> -1/0
[1] -Inf
> 0/0
[1] NaN
> is.nan(0/0)
[1] TRUE
> is.infinite(1/0)
[1] TRUE
> is.infinite(-1/0)
[1] TRUE
2.9 字符串
R语言支持正则表达式,正则表达式如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-picP5VLQ-1688349485071)(https://vip2.loli.io/2023/03/13/kiVJt3FIcszSBga.png)]
下面介绍处理字符串的函数:
> nchar("hello world")
[1] 11
> month.name
[1] "January" "February" "March" "April" "May" "June" "July" "August" "September" "October"
[11] "November" "December"
> nchar(month.name)
[1] 7 8 5 5 3 4 4 6 9 7 8 8
> length(month.name)
[1] 12
> nchar(c(12,2,345))
[1] 2 1 3
> paste("Everybody","loves","stats")
[1] "Everybody loves stats"
> paste("Everybody","loves","stats",sep = "-")
[1] "Everybody-loves-stats"
> names <- c("Moe","Larry","Curly")
> paste(names,"loves stats")
[1] "Moe loves stats" "Larry loves stats" "Curly loves stats"
总结:nchar可以用来统计字符数,空格也算一个字符。length计算的是元素的个数,而nchar计算的是每个元素字符的长度。paste是将多个字符串连成一个字符串,通过空格进行连接,也可以通过sep设定连接符,也可以将多个字符串分别和某一个固定的字符串进行连接。
> substr(x = month.name,start = 1,stop = 3)
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"
> temp <- substr(x = month.name,start = 1,stop = 3)
> toupper(temp)
[1] "JAN" "FEB" "MAR" "APR" "MAY" "JUN" "JUL" "AUG" "SEP" "OCT" "NOV" "DEC"
> tolower(temp)
[1] "jan" "feb" "mar" "apr" "may" "jun" "jul" "aug" "sep" "oct" "nov" "dec"
> gsub("^(\\w)","\\U\\1",tolower(temp),perl = T)
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"
> gsub("^(\\w)","\\L\\1",tolower(temp),perl = T)
[1] "jan" "feb" "mar" "apr" "may" "jun" "jul" "aug" "sep" "oct" "nov" "dec"
> gsub("^(\\w)","\\L\\1",toupper(temp),perl = T)
[1] "jAN" "fEB" "mAR" "aPR" "mAY" "jUN" "jUL" "aUG" "sEP" "oCT" "nOV" "dEC"
总结:字符串分隔符substr可以进行字符串分割,sub进行一次字符替换,而gsub可以进行全局替换,需要使用正则表达式进行操作。
> x <- c("b","A+","AC")
> x
[1] "b" "A+" "AC"
> grep("A+",x)
[1] 2 3
> grep("A+",x,fixed = T)
[1] 2
> grep("A+",x,fixed = F)
[1] 2 3
总结:grep可以用来查找字符串,如果grep参数中fixed为T,则不支持正则表达式,返回值为匹配的下标,grep支持正则表达式,如果Fixed为F,则支持正则表达式,其中A+中的+号表示所有字符。
> x <- c("b","A+","AC")
> x
[1] "b" "A+" "AC"
> match("AC",x)
[1] 3
总结:match也可以进行字符串匹配,但是不支持正则表达式,没有grep强大。
> path <- "/use/local/bin/R"
> strsplit(path,"/")
[[1]]
[1] "" "use" "local" "bin" "R"
> strsplit(c(path,path),"/")
[[1]]
[1] "" "use" "local" "bin" "R"
[[2]]
[1] "" "use" "local" "bin" "R"
总结:strsplit为字符串分割函数,需要指定分隔符,在上面的例子中,分隔符为/。strsplit返回的值是一个列表而不是一个向量。可以同时处理分割多个字符串,也方便后面的处理。
许多函数都有fixed参数设置,表示是否支持正则表达式,使用正则表达式很方便进行处理。
face <- 1:13
suit <- c("spades","clubs","hearts","diamonds")
> outer(suit,face,FUN=paste)
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
[1,] "spades 1" "spades 2" "spades 3" "spades 4" "spades 5" "spades 6" "spades 7" "spades 8" "spades 9"
[2,] "clubs 1" "clubs 2" "clubs 3" "clubs 4" "clubs 5" "clubs 6" "clubs 7" "clubs 8" "clubs 9"
[3,] "hearts 1" "hearts 2" "hearts 3" "hearts 4" "hearts 5" "hearts 6" "hearts 7" "hearts 8" "hearts 9"
[4,] "diamonds 1" "diamonds 2" "diamonds 3" "diamonds 4" "diamonds 5" "diamonds 6" "diamonds 7" "diamonds 8" "diamonds 9"
[,10] [,11] [,12] [,13]
[1,] "spades 10" "spades 11" "spades 12" "spades 13"
[2,] "clubs 10" "clubs 11" "clubs 12" "clubs 13"
[3,] "hearts 10" "hearts 11" "hearts 12" "hearts 13"
[4,] "diamonds 10" "diamonds 11" "diamonds 12" "diamonds 13"
> outer(suit,face,FUN=paste,sep = "-")
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
[1,] "spades-1" "spades-2" "spades-3" "spades-4" "spades-5" "spades-6" "spades-7" "spades-8" "spades-9"
[2,] "clubs-1" "clubs-2" "clubs-3" "clubs-4" "clubs-5" "clubs-6" "clubs-7" "clubs-8" "clubs-9"
[3,] "hearts-1" "hearts-2" "hearts-3" "hearts-4" "hearts-5" "hearts-6" "hearts-7" "hearts-8" "hearts-9"
[4,] "diamonds-1" "diamonds-2" "diamonds-3" "diamonds-4" "diamonds-5" "diamonds-6" "diamonds-7" "diamonds-8" "diamonds-9"
[,10] [,11] [,12] [,13]
[1,] "spades-10" "spades-11" "spades-12" "spades-13"
[2,] "clubs-10" "clubs-11" "clubs-12" "clubs-13"
[3,] "hearts-10" "hearts-11" "hearts-12" "hearts-13"
[4,] "diamonds-10" "diamonds-11" "diamonds-12" "diamonds-13"
总结:outer函数可以生成两个字符串的所有组合,两个字符串的连接默认通过空格的形式,也可以自定义连接符。
2.10 日期和时间
时间序列分析:
- 对时间序列的描述;
- 利用前面的结果进行预测。
时间序列包:TimeSeries
时间数据集:sunspots、presidents、airmiles
> class(presidents)
[1] "ts"
总结:这里的ts表示时间序列,有些数据集是时间序列数据,但是数据形式是数据框。
> Sys.Date()
[1] "2022-08-06"
> class(Sys.Date())
[1] "Date"
> a <- "2017-01-01"
> a
[1] "2017-01-01"
> as.Date(a,format = "%Y-%m-%d")
[1] "2017-01-01"
> class(as.Date(a,format = "%Y-%m-%d"))
[1] "Date"
总结:Sys.Date函数可以查看当前的年月日,Sys.Date()中的数据类型为Date类型,可以通过as.Date函数将字符串类型转换成Date类型。
更多格式化参数,可以通过?strftime命令参看strftime函数中的介绍。
> seq(as.Date("2017-01-01"),as.Date("2017-06-23"),by = 5)
[1] "2017-01-01" "2017-01-06" "2017-01-11" "2017-01-16" "2017-01-21" "2017-01-26" "2017-01-31" "2017-02-05" "2017-02-10"
[10] "2017-02-15" "2017-02-20" "2017-02-25" "2017-03-02" "2017-03-07" "2017-03-12" "2017-03-17" "2017-03-22" "2017-03-27"
[19] "2017-04-01" "2017-04-06" "2017-04-11" "2017-04-16" "2017-04-21" "2017-04-26" "2017-05-01" "2017-05-06" "2017-05-11"
[28] "2017-05-16" "2017-05-21" "2017-05-26" "2017-05-31" "2017-06-05" "2017-06-10" "2017-06-15" "2017-06-20"
总结:可以使用seq函数创建连续的时间点,by表示间隔五天。
> sales <- round(runif(48,min=50,max=100))
> sales
[1] 56 88 87 91 83 82 90 68 100 64 64 62 85 51 76 91 53 94 80 93 77 73 53 59 88 71 98 89 74 66
[31] 91 57 71 50 67 91 70 60 51 71 99 73 95 52 57 72 82 72
> ts(sales,start = c(2010,5),end = c(2014,4),frequency = 1)
Time Series:
Start = 2014
End = 2017
Frequency = 1
[1] 56 88 87 91
> ts(sales,start = c(2010,5),end = c(2014,4),frequency = 4)
Qtr1 Qtr2 Qtr3 Qtr4
2011 56 88 87 91
2012 83 82 90 68
2013 100 64 64 62
2014 85 51 76 91
> ts(sales,start = c(2010,5),end = c(2014,4),frequency = 12)
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
2010 56 88 87 91 83 82 90 68
2011 100 64 64 62 85 51 76 91 53 94 80 93
2012 77 73 53 59 88 71 98 89 74 66 91 57
2013 71 50 67 91 70 60 51 71 99 73 95 52
2014 57 72 82 72
总结:runif(48,min=50,max=100)表示随机生成均匀分布d48个数值,最小值为50,最大值为100。round表示四舍五入取整。ts可以将向量转换为时间序列,ts中的frequency值为1,表示以年为单位,如果值为4,表示以季度为单位,如果值为12,表示以月为单位,没有以天为单位的,一般时间序列不用天为单位。
2.11 常见错误
注意:变量赋值要用c,需要注意括号的使用,字符串需要加上引号。在R语言中文件地址用正斜线,反斜线用来转义。
> x <- c(1,2,3)
> x
[1] 1 2 3
> x <- matrix(c(1:20,seq(1,12,3),4,4))
> x
[,1]
[1,] 1
[2,] 2
[3,] 3
[4,] 4
[5,] 5
[6,] 6
[7,] 7
[8,] 8
[9,] 9
[10,] 10
[11,] 11
[12,] 12
[13,] 13
[14,] 14
[15,] 15
[16,] 16
[17,] 17
[18,] 18
[19,] 19
[20,] 20
[21,] 1
[22,] 4
[23,] 7
[24,] 10
[25,] 4
[26,] 4
> getwd()
[1] "C:/Users/ywwsn/Documents"
> setwd("c:\\Users\\Default")
> setwd("c:/Users/Default")
如果出现错误,可以访问网站进行解决,比如Google、Rblogger、quickR、stackoverflow等。
3 数据基本操作
3.1 获取数据
R获取数据三种途径:
- 利用键盘来输入数据;
- 通过读取存储在外部文件上的数据;
- 通过访问数据库系统来获取数据。
手动输入方式:
> status <- c("Poor", "Improved", "Excellent", "Poor")
> data <- data.frame(patientID, age, diabetes, status)
> data
patientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor
> data2 <- data.frame(patientID=character(0),admdate=character(0),age=numeric(),diabetes=character(),status=character())
> data2
[1] patientID admdate age diabetes status
<0 行> (或0-长度的row.names)
> data2 <- edit(data2)
> data2
patientID admdate age diabetes status
1 1 10/15/200 25 Type1 Poor
2 2 11/01/2009 34 Type2 Improved
3 3 10/21/2009 28 Type1 Excellent
4 4 10/28/2009 52 Type1 Poor
在运行data2 <- edit(data2)命令时会弹出下面的数据编辑器,进行数据输入:
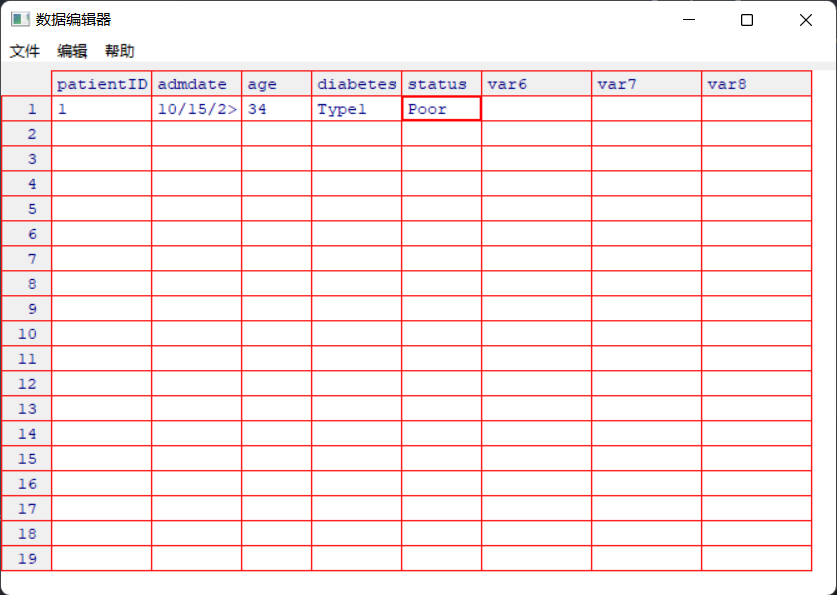
在linux系统中如果无法打开数据编辑器,可以用vim进行编辑。
也可以使用fix函数启动数据编辑器进行边界,fix修改后会直接保存。
通过IDBC访问数据库,ODBC(Open Database Connectivity)是开放数据库连接。
在R中,可以RODBC包连接和访问数据库。:
> install.packages("RODBC")
RODBC包允许R和一个通过ODBC连接的SQL数据库之间进行双向的通信,这样不仅可以用R读取数据库的内容,同时还可以将R处理过的数据写入数据库中。需要使用MySQL、SQLlite包就下载相应的包。
3.2 读取文件
读取纯文本文件,可以使用read.table函数,将读取的文件赋值给一个参数。
> x <- read.table("input.txt")
> head(x)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
> tail(x)
Ozone Solar.R Wind Temp Month Day
148 14 20 16.6 63 9 25
149 30 193 6.9 70 9 26
150 NA 145 13.2 77 9 27
151 14 191 14.3 75 9 28
152 18 131 8.0 76 9 29
153 20 223 11.5 68 9 30
x <- read.table("f:/Learning/R语言入门与数据分析/RData/input.txt")
> x <- read.table("input.csv")
> x
V1 V2
1 ,"mpg","cyl","disp","hp","drat","wt","qsec","vs","am","gear","carb"
2 Mazda RX4 ,21,6,160,110,3.9,2.62,16.46,0,1,4,4
3 Mazda RX4 Wag ,21,6,160,110,3.9,2.875,17.02,0,1,4,4
4 Datsun 710 ,22.8,4,108,93,3.85,2.32,18.61,1,1,4,1
...
31 Ferrari Dino ,19.7,6,145,175,3.62,2.77,15.5,0,1,5,6
32 Maserati Bora ,15,8,301,335,3.54,3.57,14.6,0,1,5,8
33 Volvo 142E ,21.4,4,121,109,4.11,2.78,18.6,1,1,4,2
> x <- read.table("input.csv",sep = ",")
> x
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12
1 mpg cyl disp hp drat wt qsec vs am gear carb
2 Mazda RX4 21 6 160 110 3.9 2.62 16.46 0 1 4 4
3 Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4
4 Datsun 710 22.8 4 108 93 3.85 2.32 18.61 1 1 4 1
...
31 Ferrari Dino 19.7 6 145 175 3.62 2.77 15.5 0 1 5 6
32 Maserati Bora 15 8 301 335 3.54 3.57 14.6 0 1 5 8
33 Volvo 142E 21.4 4 121 109 4.11 2.78 18.6 1 1 4 2
> x <- read.table("input.csv",sep = ",",header = TRUE)
> x
X mpg cyl disp hp drat wt qsec vs am gear carb
1 Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
...
30 Ferrari Dino 19.7 6 145 175 3.62 2.77 15.5 0 1 5 6
31 Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
32 Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
> x <- read.table("input 1.txt",header = TRUE,skip = 5)
> x
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
...
151 14 191 14.3 75 9 28
152 18 131 8.0 76 9 29
153 20 223 11.5 68 9 30
> x <- read.table("input 1.txt",header = TRUE,skip = 6,nrows = 6)
> x
X1 X41 X190 X7.4 X67 X5 X1.1
1 2 36 118 8.0 72 5 2
2 3 12 149 12.6 74 5 3
3 4 18 313 11.5 62 5 4
4 5 NA NA 14.3 56 5 5
5 6 28 NA 14.9 66 5 6
6 7 23 299 8.6 65 5 7
总结:这里的head为显示x的头部6行,tail为显示x的尾部6行。read.table读取的文件可以写全局路径。如果读写的是csv文件,需要将分隔符设为,。否则会出现问题,如果想知道用什么分隔符,可以打开文件看看。header参数如果为TRUE表示将第一行作为变量名称。skip参数用来跳过部分内容,比如有些数据会有介绍性文字。通过skip和nrows组合可以读取任意一段数据。na.strings参数可以将设定的其他软件中的缺失符号替换为NA,NA属于R中的缺失值。stringAsFactors控制读入的字符串是否转换成因子,R读取数据时,数字被读取成数值型数据,而在读取字符串时,会默认将读取的字符串转为因子类型,但是很多情况下不需要这样的转换,因此需要将stringAsFactors设为FALSE。
除了read.table函数,还有read.csv函数,read.csv函数默认用,分隔。read.delim表示读取用制表符分割的文件,read.fwf表示读取固定宽度的文件,每一列都开始于固定的位置,例如:
read.fwf("fwf.txt",widths = c(2,3,4))
使用read.fwf需要用widths参数给定每一列所占用的宽度值。这种文件使用的不多。
R还支持读取网络文件,read.table会将文件下载到本地。
x <- read.table("https://codeload.github.com/mperdeck/LINQtoCSV/zip/master",header = TRUE)
如果读取网页中的数据,需要安装包XML,然后通过readHTMLTable函数进行读取,如果想读取网页中第三个表格的数据,可以将which参数值设为3。
可以通过foreign包中的函数对其他软件格式的数据进行导入。
help(package = "foreign")
如果其他格式的文件不在foreign包中,一种方法就是另存为文本文件,另一种就是搜索R中对应的包,例如搜索能够读取Matlab相关格式的包,如下所示:
RSiteSearch("Matlab")
R还支持读取剪贴板的数据:
> x <- read.table("clipboard",header = T, sep = "\t")
> x
X mpg cyl disp hp drat wt qsec vs am gear carb
1 Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
4 Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











