







集合的引入
需求:我们知道Java是面向对象语言,那么万事万物皆是对象,我们需要使用一个容器来存储对象,并且希望对容器中对象进行存储,增加,删除,修改,查询的操作。
解决办法: 数组
数组的特点:
- 存储相同数据类型的一组数据
- 编译时期确定类型int[] arr = new int[3]; arr[0] = 10;
- 通过索引访问元素arr[0] arr[1]
- 既能够存储基本数据类型,还能够存储引用数据类型 Student[] Book[] Pig[]
- 数据结构是数组结构 【数据的存储方式】
- 数组的长度固定不变
- 可以针对数组进行增删查改的操作,但是很麻烦,并且数组中没有好的api方法提供给我们供我们对数组中的对象进行操作
- 数组针对其中的元素进行增加和删除的效率低,查询和修改的效率高
缺点:
1. 一旦编译结束,只能够存储同种类型
2. 长度固定不变
3. 针对其中的元素进行增加和删除的效率低
4. 没有好的方法对数组中的元素进行操作
所以Java针对以上缺陷设计了集合:
1. 能够存储任意类型的容器,可以动态扩容和缩容
2. 能够提供好的方法对容器中元素进行增加删除修改查询的操作
3. 可以自行根据不同的容器元素特点选择不同的数据结构的集合,从而提高容器的效率
数组和集合的区别
数组和集合的区别
长度
数组的长度固定不变的
集合长度是可以根据实际需要改变
内容
数组存储的是同一种类型的元素
集合可以存储不同类型的元素
数据类型
数组可以存储基本数据类型,也可以存储引用数据类型
集合只能存储引用类型
注意:虽然集合不能存储基本数据类型,但是可以存储基本数据类型的包装类类型
方法
数组没有任何的api操作元素
集合提供了大量的API操作元素
集合概述
集合是一批类,它是一套框架体系,如下图所示:
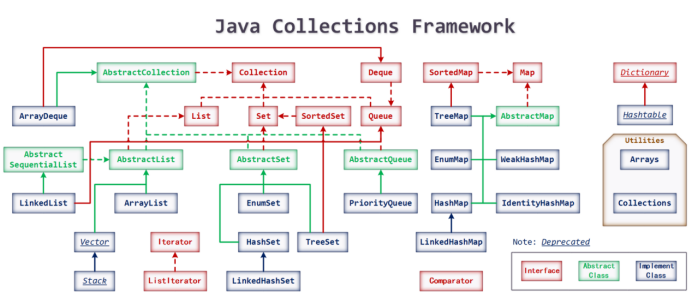
1. 集合为什么要设计出这么多类?
集合分为单列集合和双列集合,单列集合类似于数组存储一组数据,双列集合存储具有关系两列数据,并且有很多不同数据结构的子类,所以设计很多类组合而成
2. 集合顶层父类为什么设计成接口而不设计成普通类?
因为我们认为容器中的元素有不同的特点:
a. 是否有序【存储有序,怎么样存进去的就怎样出来】
b. 是否唯一
c. 是否可以存储null值
d. 是否可排序
e. 是否安全
f. 容器存取的效率
数据结构【数据的存储方式】
针对不同的特点会有不同的实现,那么这个时候父类必须设计成接口,子类根据不同的数据结构和实现方式实现自己的增删查改的功能,所以父类设计为接口。
学习集合围绕集合的特点方法数据结构
Collection接口
概述
Collection 层次结构 中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 不提供此接口的任何直接 实现:它提供更具体的子接口(如 Set 和 List)实现。此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。
特点
- 作为单列集合的根接口
- 部分集合有序,可重复【List】 部分集合无序,唯一【Set】
- 该接口不会提供具体的实现,如果要创建之,使用多态
成员方法
添加
- boolean add(E?e) 将指定的元素添加到此列表的尾部。
- boolean addAll(Collection<? extends E>?c) 将指定 collection 中的所有元素都添加到此 collection 中
删除
- void clear() 移除此 collection 中的所有元素(可选操作)。
- boolean remove(Object o) 从此 collection 中移除指定元素的单个实例
- boolean removeAll(Collection<?>?c) 移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。
修改
因为集合Collection是一个接口,如果能够修改,需要索引,而索引属于List接口的,Colleciton并不能够确定集合是否有序,所以这里不设计修改的方法
遍历
- Object[] toArray() 将集合转换成数组
- <T> T[] toArray(T[]?a) 泛型方法,将集合转换成数组
- Iterator<E> iterator() 返回在此 collection 的元素上进行迭代的迭代器。
判断
- boolean contains(Object?o) 判断集合中是否包含某个元素o
- boolean containsAll(Collection<?>?c) 如果此 collection 包含指定 collection 中的所有元素,则返回 true。
- boolean isEmpty() 如果此 collection 不包含元素,则返回 true。
其他
- int size() 获取集合的长度
集合的遍历
1. toArray遍历方式:将集合转换成数组进行遍历
Collection c = new ArrayList();
c.add("刘德华");
c.add("刘嘉玲");
c.add("刘亦菲");
c.add("刘能");
c.add("刘星");
c.add(c);
Object[] objs = c.toArray();
for (Object oj : objs) {
System.out.println(oj);
}
2. 迭代器遍历
// 通过集合创建迭代器对象
Iterator it = c.iterator();
while (it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}
可能出现的异常:
java.util.NoSuchElementException
异常名称:没有这样的元素异常
产生原因: 在迭代器迭代元素的时候,已经没有元素可以迭代了
解决办法: 在迭代遍历元素之前针对是否有元素做判断
默认集合重写的toString方法
public String toString() {
Iterator<E> it = iterator();
if (! it.hasNext())
return "[]";
StringBuilder sb = new StringBuilder();
sb.append('[');
for (;;) {
E e = it.next();
sb.append(e == this ? "(this Collection)" : e);
if (! it.hasNext())
return sb.append(']').toString();
sb.append(',').append(' ');
}
}Foreach遍历集合
Foreach遍历集合的格式:
For(元素类型 元素名 : 集合) {
通过元素名操作元素;
}
1. foreach简化遍历
2. Foreach本质还是使用了迭代器
Object obj;
for (Iterator iterator = c.iterator(); iterator.hasNext(); System.out.println(obj))
obj = iterator.next();
3. Foreach遍历集合和while的区别
(1) Foreach遍历之后就会释放迭代器对象,节约内存
(2) While循环遍历集合可读性更强
Collection集合去除重复元素
1. 创建一个新的集合,然后使用地址传递
(1) 如果比较的是系统类,String 不需要重写equals方法
(2) 如果比较的是自定义对象,需要自己根据需求重写equals方法
代码示例:
// 1.创建一个新的集合
Collection newC = new ArrayList();
// 2.遍历旧集合,获取到每一个元素
for (Object obj : c) {
// 3.判断在新集合中是否存在该元素
if (!newC.contains(obj)) {
// 4.如果不包含,就存储到新集合中
newC.add(obj);
}
}
// 地址传递
c = newC;
for (Object object : c) {
System.out.println(object);
}2. 使用选择排序思想去除重复元素【后面讲解List接口补充】
List接口
概述: 有序的collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
成员方法
添加
- void add(int index, E element) 在列表的指定位置插入指定元素(可选操作)。
- boolean addAll(int index, Collection<? extends E> c) 将指定 collection 中的所有元素都插入到列表中的指定位置(可选操作)。
删除
- E remove(int index) 移除列表中指定位置的元素(可选操作)。
修改
- E set(int index, E element) 用指定元素替换列表中指定位置的元素(可选操作)。
遍历
- E get(int index)
- ListIterator<E> listIterator() 返回此列表元素的列表迭代器(按适当顺序)。
- ListIterator<E> listIterator(int?index) 返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置开始。
获取
- int indexOf(Object o) 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。
- int lastIndexOf(Object o) 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。
- List<E> subList(int fromIndex, int?toIndex) 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图。
List接口的遍历方式
List接口是有序的,可以通过普通for遍历,还可以通过ListIterator遍历。
toArray方式遍历
List<String> list = new ArrayList<String>();
list.add("林冲");
list.add("武大郎");
list.add("潘金莲");
list.add("西门庆");
list.add("武松");
list.add("李逵");
list.add("宋江");
list.add("卢俊义");
list.add("时迁");
// 泛型toArray 来自于Collection
String[] strs = list.toArray(new String[] {});
for (String s : strs) {
System.out.println(s);
}
迭代器遍历
// 迭代器 来自于Collection
Iterator<String> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
或者
for(Iterator<String> iterator = list.iterator();
iterator.hasNext(); System.out.println(iterator.next())) ;
Forearch遍历
for (String s: strs) {
System.out.println(s);
}
普通for遍历
// 普通for遍历
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
列表迭代器
ListIterator<String> lit = list.listIterator();
while (lit.hasNext()) {
String s = lit.next();
System.out.println(s);
}
while (lit.hasPrevious()) {
String s = lit.previous();
System.out.println(s);
}
List<String> subList = list.subList(1, 5);
ListIterator<String> listIterator=subList.listIterator(subList.size());
while(listIterator.hasPrevious()) {
System.out.println(listIterator.previous());
}
ArrayList类
概述
List 接口的大小可变数组的实现。实现了所有可选列表操作,并允许包括 null 在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。(此类大致上等同于 Vector类,除了此类是不同步的。)
特点
- 底层数据结构是数组
- 增加和删除的效率低,查询和修改的效率高
- 能够存储 null 值
- 线程不安全,效率高可以通过 Collections.synchronizedList();变安全
- 有索引,能够方便检索
- 元素可重复,我们自己可以通过选择排序去重复
- 不可以排序,但是可以通过 Collections.sort();方法排序
- 注:ArrayList中常用的方法全部来自于 父类 Collection,List,Object.这里不再做详细叙述。
ArrayList动态扩容原理
ArrayList<String> list = new ArrayList<String>();
list.add("abc");
list.add("efg");
list.add("efg");
class ArrayList<String> {
transient Object[] elementData;
// 1. {} 2. elementData.length = 0 3. size = 0
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
private static final int DEFAULT_CAPACITY = 10;
private int size;
protected transient int modCount = 0;
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public boolean add(String e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
1
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); // 10
}
ensureExplicitCapacity(minCapacity); // 10
}
10
private void ensureExplicitCapacity(int minCapacity) {
modCount++; // 添加会导致modCount发生变化
// overflow-conscious code
if (minCapacity > elementData.length) 10 > 0
// 动态扩容的核心源码实现
grow(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; // 2147483639
Integer.MAX_VALUE = 2147483647;
10
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length; // 0
int newCapacity = oldCapacity + (oldCapacity / 2); // 扩容系数
// ==> (1 + 1/2) * oldCapcity == > 1.5 * oldCapcity
if (newCapacity < minCapacity)
newCapacity = minCapacity; // 10
if (newCapacity > MAX_ARRAY_SIZE)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) { 2147483637
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
}
通过观察源码我们可以发现以下特点:
ArrayList是底层还是依赖数组实现,动态扩容和缩容依赖的是Arrays.copyOf方法,copyOf方法依赖的是System.arrayCopy方法,并且扩容系数为1.5倍
Vector类
概述
Vector 类可以实现可增长的对象数组。与数组一样,它包含可以使用整数索引进行访问的组件。但是,Vector 的大小可以根据需要增大或缩小,以适应创建 Vector 后进行添加或移除项的操作。
特点
- 底层数据结构是数组
- 有索引,能够方便检索
- 增加和删除的效率低,查询和修改的效率高
- 线程安全,效率低
- 能够存储null 值
- 元素可重复【我们自己可以通过选择排序思想去除重复元素】
- 不可以排序,但是可以通过Collections.sort();方法排序
常用方法
增加
- public synchronized void addElement(E obj) 添加元素 obj 到集合中
- public synchronized void insertElementAt(E obj, int index) 在指定索引 index 处插入元素 obj
删除
- public synchronized void removeElementAt(int index) 移除指定索引 index 处的元素
- public synchronized void removeAllElements() 移除所有元素
修改
- public synchronized void setElementAt(E obj, int index) 修改指定索引 index 的元素为 obj
遍历
- public synchronized E elementAt(int index) + size() for循环遍历集合中的所有元素
- public synchronized Enumeration<E> elements() 使用 Enumeration 迭代器遍历集合中的元素
获取
- public synchronized E firstElement() 获取集合中的第一个元素
- public synchronized E lastElement() 获取集合中的最后一个元素
- public synchronized E elementAt(int index) 获取指定索引 index 的元素
相关面试题
| ArrayList和Vector的区别? 1) Vector的方法都是同步的(Synchronized),是线程安全的(thread-safe),而ArrayList的方法不是,由于线程的同步必然要影响性能,因此,ArrayList的性能比Vector好。 2) 当Vector或ArrayList中的元素超过它的初始大小时,Vector会将它的容量翻倍,而ArrayList只增加50%的大小,这样,ArrayList就有利于节约内存空间。 |
Stack类
概述
Stack 类表示后进先出(LIFO)的对象堆栈。它通过五个操作对类 Vector 进行了扩展 ,允许将向量视为堆栈。它提供了通常的 push 和 pop 操作,以及取堆栈顶点的 peek 方法、测试堆栈是否为空的 empty 方法、在堆栈中查找项并确定到堆栈顶距离的 search 方法。
特点
- 基于栈结构的集合,先进后出
- Stack 类是Vector类的子类,所以该类也是线程安全的,效率低,建议使用Deque接口的实现类
常用方法
- E push(E item) 将元素压入栈底
- E pop() 将元素从栈结构中弹出,并作为此函数的值返回该对象,此方法会影响栈结构的大小
- E peek() 查看堆栈顶部的对象,但不从栈中移除它。
- boolean empty() 测试栈是否为空。
- int search(Object o) 返回对象在栈中的位置,以 1 为基数。
注:如果栈中元素为空,再尝试弹栈,将会抛出 EmptyStackException 异常, 而不是 NoSuchElementException
示例代码
Stack<String> stack = new Stack<>();
// 压栈
stack.push("A");
stack.push("B");
stack.push("C");
while (!stack.isEmpty()) {
System.out.println("栈顶元素:" + stack.peek());
// 弹栈
System.out.println("弹出栈顶元素:" + stack.pop());
}Queue类
概述
在处理元素前用于保存元素的 collection。除了基本的Collection操作外,队列还提供其他的插入、提取和检查操作。每个方法都存在两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是用于专门为有容量限制的 Queue 实现设计的;在大多数实现中,插入操作不会失败。
特点
- 该接口是队列接口的根接口,先进先出
- 该接口提供队列相关两种形式的方法,一种抛出异常(操作失败时),另一种返回一个特殊值(null 或false,具体取决于操作)。插入操作的后一种形式是用于专门为有容量限制的Queue 实现设计的;在大多数实现中,插入操作不会失败。
常用方法
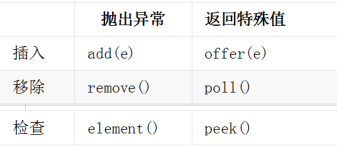
示例代码
Queue<String> queue = new ArrayDeque<>();
queue.add("A");
queue.add("B");
queue.add("C");
while (!queue.isEmpty()) {
System.out.println(queue.remove());
}
// 或者
queue.offer("A");
queue.offer("B");
queue.offer("C");
while (!queue.isEmpty()) {
System.out.println(queue.poll());
}Deque类
概述
一个线性collection,支持在两端插入和移除元素。名称 deque 是“double ended queue(双端队列)”的缩写,通常读为“deck”。大多数 Deque 实现对于它们能够包含的元素数没有固定限制,但此接口既支持有容量限制的双端队列,也支持没有固定大小限制的双端队列。
特点
- Deque是一个Queue的子接口,是一个双端队列,支持在两端插入和移除元素
- deque支持索引值直接存取。
- Deque头部和尾部添加或移除元素都非常快速。但是在中部安插元素或移除元素比较费时。
- 插入、删除、获取操作支持两种形式:快速失败和返回null或true/false
- 不推荐插入null元素,null作为特定返回值表示队列为空
常用方法
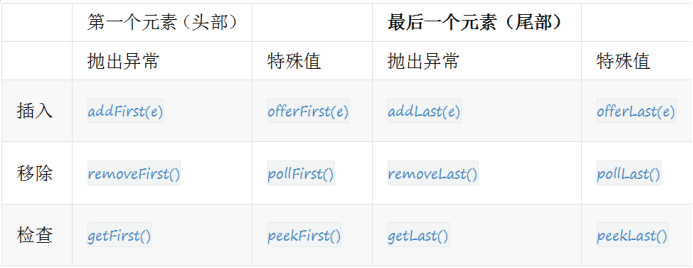
双向队列操作
插入元素
- addFirst(): 向队头插入元素,如果元素为null,则发生空指针异常
- addLast(): 向队尾插入元素,如果为空,则发生空指针异常
- offerFirst(): 向队头插入元素,如果插入成功返回true,否则返回false
- offerLast(): 向队尾插入元素,如果插入成功返回true,否则返回false
移除元素
- removeFirst(): 返回并移除队头元素,如果该元素是null,则发生NoSuchElementException
- removeLast(): 返回并移除队尾元素,如果该元素是null,则发生NoSuchElementException
- pollFirst(): 返回并移除队头元素,如果队列无元素,则返回null
- pollLast(): 返回并移除队尾元素,如果队列无元素,则返回null
获取元素
- getFirst(): 获取队头元素但不移除,如果队列无元素,则发生NoSuchElementException
- getLast(): 获取队尾元素但不移除,如果队列无元素,则发生NoSuchElementException
- peekFirst(): 获取队头元素但不移除,如果队列无元素,则返回null
- peekLast(): 获取队尾元素但不移除,如果队列无元素,则返回null
栈操作
- pop(): 弹出栈中元素,也就是返回并移除队头元素,等价于removeFirst(),如果队列无元素,则发生NoSuchElementException
- push(): 向栈中压入元素,也就是向队头增加元素,等价于addFirst(),如果元素为null,则发生NoSuchElementException,如果栈空间受到限制,则发生IllegalStateException
应用场景
- 满足FIFO场景时
- 满足LIFO场景时,曾经在解析XML按标签时使用过栈这种数据结构,但是却选择Stack类,如果在进行栈选型时,更推荐使用Deque类,应为Stack是线程同步
ArrayDeque类
概述
Deque 接口的大小可变数组的实现。数组双端队列没有容量限制;它们可根据需要增加以支持使用。它们不是线程安全的;在没有外部同步时,它们不支持多个线程的并发访问。禁止null 元素。此类很可能在用作堆栈时快于 Stack,在用作队列时快于LinkedList。
特点
- ArrayDeque 是Deque 接口的一种具体实现,是依赖于可变数组来实现的
- ArrayDeque 没有容量限制,可根据需求自动进行扩容
- ArrayDeque不支持值为null 的元素。
- ArrayDeque 可以作为栈来使用,效率要高于 Stack
- ArrayDeque 也可以作为队列来使用,效率相较于基于双向链表的 LinkedList 也要更好一些
LinkedList
概述
List 接口的链接列表实现。实现所有可选的列表操作,并且允许所有元素(包括 null)。除了实现 List 接口外,LinkedList 类还为在列表的开头及结尾 get、remove 和 insert 元素提供了统一的命名方法。这些操作允许将链接列表用作堆栈、队列或双端队列。
特点
- LinkedList 底层数据结构是一个双向链表,元素有序,可重复。
- LinkedList 在实现数据的增加和删除效率高,查询和修改效率低,顺序访问会非常高效,而随机访问效率比较低。
- LinkedList 实现 List 接口,支持使用索引访问元素。
- LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
- LinkedList 是线程不安全的,效率高
Set接口
概述
一个不包含重复元素的collection。更确切地讲,set 不包含满足 e1.equals(e2) 的元素对e1 和e2,并且最多包含一个null 元素
特点
- Set接口是无序的
- Set 是继承于Collection的接口。它是一个不允许有重复元素的集合。
- Set可以存储null值,但是null不能重复
- Set的实现类大多数都是基于Map来实现的(HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,LinkedHashSet是通过LinkedHashMap实现的)。
- 成员方法全部来自于Object类和Collection类。
示例代码
Set<String> set = new HashSet<>();
set.add("abc");
set.add("hij");
set.add("opq");
set.add("bac");
set.add("bac");
set.add("cab");
set.add("cba");
set.add("cba");
set.add(null);
set.add(null);
// foreach遍历
for (String s : set) {
System.out.println(s);
}
// 迭代器遍历
Iterator<String> it = set.iterator();
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
HashSet类
此类实现Set 接口,由哈希表(实际上是一个HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
特点
- 底层数据结构是哈希表(JDK1.8数据结构为数组 + 链表 + 红黑树)
- 去除重复元素依赖hashCode和equals方法
存储元素是首先判断元素的hashCode是否相等
相等,继续比较元素的equals方法
相等
不存储到哈希表结构中
不相等
不存储到哈希表结构中,去除重复元素
不相等,不存储到哈希表结构中,去除重复元素
- 如果HashSet中的元素是系统类,则不需要重写hashCode和equals方法,如果元素是自定义对象,则需要自己手动重写hashCode和equals方法,重写的规则可以自动生成,快捷键 Alt + Shift + S再按H。
示例代码
HashSet<String> hs = new HashSet<>();
hs.add("abc");
hs.add("hij");
hs.add("opq");
hs.add("bac");
hs.add("bac");
hs.add("cab");
hs.add("cba");
hs.add("cba");
for (String s : hs) {
System.out.print(s + "\t");
}
HashSet底层源码以及数据结构解析
首先我们先建元素存储到集合中,代码如下:
HashSet<String> hs = new HashSet<>();
hs.add("abc");创建HashSet底层其实创建的是HashMap
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
这里访问的是HashMap的无参构造方法
/**
* The load factor for the hash table.
* @serial
*/
final float loadFactor;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}访问了HahMap的无参构造方法,这里的负载因子是0.75.接下来我们可以看一下hs.add()方法了.
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}通过观察我们会发现其实Set本质就是将value设置为一个final的常量,这个常量是一个不会发生变化的地址,所以我们只需要关系键即可,我们继续深入学习map的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}通过观察putVal方法我们可以知道其实这里存储元素到哈希表结构之前先会根据存储的元素本很计算一个hash索引值,我们继续来跟踪学习hash(key)方法。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}通过hash方法我们知道计算某个hash索引值和对象本身的hashCode方法有关,那么到这里我们就知道为什么我们书写元素的时候建议大家重写hashCode方法,因为哈希索引值依赖这个方法,那么我们回到putVal的方法继续深入研究,但是学习这个方法之前我希望让大家先了解一下HashMap的一些重要成员变量
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
/**
* The default initial capacity - MUST be a power of two.
* 默认初始容量 - 必须是2的幂次方整数
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
* 最大容量,当显示调用其中一个带参构造方法的时候使用
* 必须是一个2的幂次方整数并且小于2的30次方
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
* 当没有在构造方法中指定该值的时候使用的默认负载因子值
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
* 链表转换成红黑树结构的最小threshold的值
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
* 当红黑树数量小于该值时,转换回链表
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
* 实际存储key,value的数组,这里将Key,Value封装成Node节点了
*/
transient Node<K,V>[] table;
/**
* The number of key-value mappings contained in this map.
* Map集合中键值对的数量,即Map集合的大小
*/
transient int size;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
* Map集合修改的次数
*/
transient int modCount;
/**
* The next size value at which to resize (capacity * load factor).
* 阈值,这个threshold = capacity * loadfactor,当HashMap的size到threshold
* 时,就要进行动态扩容(resize)
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
/**
* The load factor for the hash table.
* 加载因子
*/
final float loadFactor;
最后我们来看一下hashMap的putVal方法
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
看源码之前我们必须先了解以下哈希表结构,大概如下如所示:
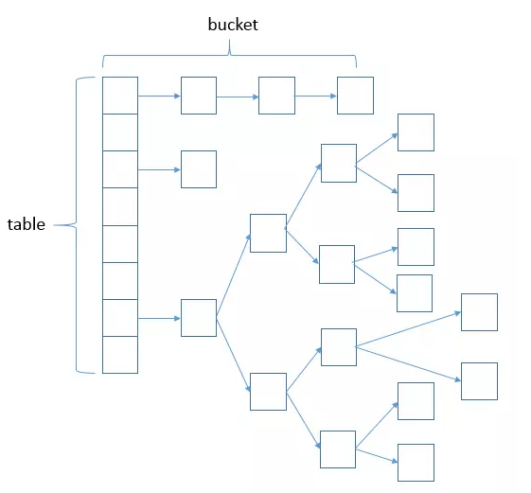
通过源码分析+数据结构原理图我们可以得出如下结论:
- 首先通过元素本身计算哈希索引,将这个值作为索引存储到哈希表结构中,由于这个值和对象本身的hashode有关,所以我们存储的元素需要重写hashCode方法,重写hashCode方法是为了提高哈希表的性能。
- 如果两个对象的hash值不同,那么完全能够说明两个对象不是同一个对象,那么我们就将该元素存储到哈希表结构中
- 如果两个对象的hash值相同(哈希冲突),那么这个时候不能够完全说明两个元素相等,还需要比较两个对象的equals方法,所以我们还需要重写equals方法。
- 当两个对象的equals方法不同,那么我们就可以以链表的形式把该元素存储到哈希表结构中同一个索引的位置。
5. 两个对象的equals方法相同,那么我们可以当成重复元素去除,不存储到哈希表结构中。
6. 当链表长度大于TREEIFY_THRESHOLD(默认为8) 的时候,将链表转换为红黑树,以提高查找的性能,当红黑树节点数量小于UNTREEIFY_THRESHOLD(默认为6)又将红黑树转回为链表以达到性能均衡。
TreeSet类
概述
基于TreeMap 的NavigableSet 实现。使用元素的自然顺序(Comparable)对元素进行排序,或者根据创建set 时提供的 (Comparotor)进行排序,具体取决于使用的构造方法。
特点
- 底层数据结构是红黑树
- TreeSet依赖二叉树取中序遍历去元素的特点能够实现元素自动排序
- TreeSet依赖二叉树存储的特点能够去除重复元素
- TreeSet的两种排序方式是如何实现
a.自然排序
使用TreeSet的无参构造方法
b.比较器排序
使用TreeSet的带Comparotor接口参数的构造方法
代码示例
TreeSet<Integer> ts = new TreeSet<>();
ts.add(44);
ts.add(32);
ts.add(25);
ts.add(44);
ts.add(78);
ts.add(91);
ts.add(12);
ts.add(32);
ts.add(19);
ts.add(91);
for (Integer i : ts) {
System.out.print(i + "\t");
}TreeSet底层源码以及数据结构解析
首先我们先来看TreeSet的构造方法
/**
* 使用该构造方法就是采用的自然排序
*/
public TreeSet() {
this(new TreeMap<E,Object>());
}
/**
* 使用该构造方法就是采用的比较器排序
*/
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}通过观察我们看先访问TreeSet构造方法底层还是创建TreeMap,我们接下来看看TreeMap的构造方法
这是一个比较器接口,默认希望外界通过构造方法传入具体的实现类,来告知当前的TreeMap根据什么规则来进行排序,即比较器排序,如果外界没有传入对应的接口实现类,那么我们将会使用元素自带的排序规则进行排序,这要求元素本身实现Comparable接口,即自然排序。
private final Comparator<? super K> comparator;
/**
* 外界如果访问无参构造方法,即没有传入接口的实现类,那么comparator为null,即使用自然排序进行排序。
*/
public TreeMap() {
comparator = null;
}
/**
* 外界传入对应Comparator接口的实现类,即通过传入的规则进行排序,即比较器排序
*/
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}接下来我们再来看看TreeSet#add方法
private static final Object PRESENT = new Object();
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}底层实际访问的是TreeMap的put方法
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}底层数据结构图解如下所示:
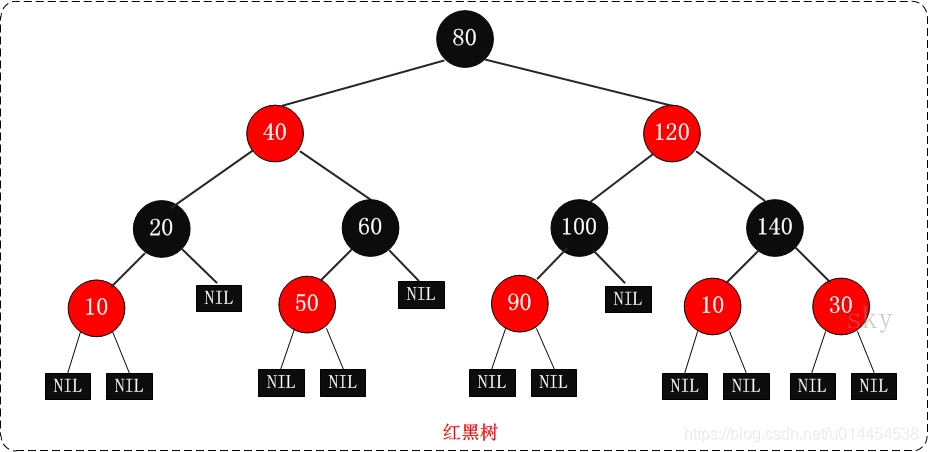
通过观察源码+数据结构图解我们可以总结出以下结论:
- 首先第一个元素进来作为根节点存储,存储之前会先做类型检查,如果元素本身没有实现Comparable接口,那么就会抛出类型转换异常。
- 后面元素进来,将根节点作为父节点进行比较
- 根据比较的整数值进行判断
(1) 大了,放在根的左边
(2) 小了,放在根的右边
(3) 相等,设置原值,即去除重复元素
- 重复上述步骤,分别将元素存储到二叉树结构中,即可去除重复元素
- 通过中序遍历将元素去除,即可实现元素排序
LinkedHashSet类
概述
Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现与HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。
特点
- 底层数据结构是链表+ 哈希表
- 链表保证元素有序
- 哈希表保证元素唯一
示例代码
LinkedHashSet<String> lhs = new LinkedHashSet<>();
lhs.add("中国");
lhs.add("中国");
lhs.add("德国");
lhs.add("日本");
lhs.add("日本");
lhs.add("意大利");
for (String s : lhs) {
System.out.print(s + "\t");
}在这里我们不在源码进行一一解析,有兴趣的同学可以自行学习。
EnumSet
概述
与枚举类型一起使用的专用Set 实现。枚举set 中所有键都必须来自单个枚举类型,该枚举类型在创建 set 时显式或隐式地指定。枚举 set 在内部表示为位向量。此表示形式非常紧凑且高效。此类的空间和时间性能应该很好,足以用作传统上基于 int 的“位标志”的替换形式,具有高品质、类型安全的优势。如果其参数也是一个枚举 set,则批量操作(如 containsAll 和retainAll)也应运行得非常快。
特点
- 枚举set 中所有键都必须来自单个枚举类型
- 枚举常量不能够重复,所以枚举Set具有天然唯一性
代码示例
public class EnumSetDemo {
public static void main(String[] args) {
EnumSet<TrafficLight> es = EnumSet.noneOf(TrafficLight.class);
es.add(TrafficLight.RED);
es.add(TrafficLight.GREEN);
es.add(TrafficLight.YELLOW);
System.out.println(es);
}
}
enum TrafficLight {
RED, GREEN, YELLOW
}
Map接口
Map接口的引入
为什么需要map集合?
学生id 姓名 年龄 成绩
2018050401 张三 18 80.0
2018050402 李四 20 85.0
2018050403 李四 21 89.0
2018050404 王五 21 89.0
如果使用已经学习过的知识点,如何来存储如上的数据?
HashSet<String> idList
ArrayList<Stirng> nameList
ArrayList<Integer> ageList
ArrayList<Double> scoreList
需求: 请通过学号查询某个学生的学生信息?
提供一个学号2018050402,可以通过学号来获取学生姓名吗?
对象和Map在数据存储方面是一模一样
Class Student {
Private String name;
Private Integer age;
}所以针对这种情况,Java就设计Map集合
Map集合提供了集合之间一种映射关系
让集合和集合之间产生关系
概述
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
此接口取代Dictionary 类,后者完全是一个抽象类,而不是一个接口。
特点
- 能够存储唯一的列的数据(唯一,不可重复)
- 能够存储可以重复的数据
- 值的顺序取决于键的顺序
- 键和值都是可以存储null元素的
- 底层数据结构依赖于键的数据结构,和值无关。
常用方法
添加功能
- V put(K key, V value)
- void putAll(Map<? extends K,? extends V> m)
删除功能
- V remove(Object key)
- void clear()
遍历功能
- Set<K> keySet()
- Collection<V> values()
- Set<Map.Entry<K,V>> entrySet()
获取功能
- V get(Object key)
判断功能
- boolean containsKey(Object key)
- boolean containsValue(Object value)
- boolean isEmpty()
修改功能
- V put(K key, V value)
- void putAll(Map<? extends K,? extends V> m)
长度功能
- int size()
代码示例
public class MapDemo01 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
System.out.println("V put(K key, V value) : " + map.put("文章", "姚笛"));
System.out.println("V put(K key, V value) : " + map.put("文章", "马伊琍"));
System.out.println("V put(K key, V value) : " + map.put("王宝强", "马蓉"));
System.out.println("V put(K key, V value) : " + map.put("贾乃亮", "李小璐"));
System.out.println("V put(K key, V value) : " + map.put("PGONE", "李小璐"));
System.out.println("V put(K key, V value) : " + map.put(null, null));
System.out.println(map);
System.out.println(map.remove("文章"));
System.out.println(map);
System.out.println(map.get("PGONE"));
System.out.println("containsKey(Object key):" + map.containsKey("贾乃亮"));
System.out.println("containsValue(Object value) : " + map.containsValue("李小璐"));
System.out.println("size: " + map.size());
}
}Map集合的遍历
遍历方式一
1. 获取到所有键的集合
2. 遍历键的集合,获取到每一个键
3. 通过键获取值
Map<String, String> map = new HashMap<String, String>();
map.put("陈羽凡", "白百何");
map.put("林丹", "妙药");
map.put("谢霆锋", "张柏芝");
map.put("汪峰", "章子怡");
Set<String> keys = map.keySet();
for (String key : keys) {
String value = map.get(key);
System.out.println(key + "=" + value);
}
遍历方式二
1. 获取到键值对对象的集合
2. 遍历键值对对象的集合,获取到每一对键值对对象
3. 通过键值对对象分别找键找值
Set<Entry<String, String>> keyValues = map.entrySet();
for (Entry<String, String> keyValue : keyValues) {
String key = keyValue.getKey();
String value = keyValue.getValue();
System.out.println(key + "=" + value);
}HashMap类
概述
基于哈希表的Map 接口的实现。此实现提供所有可选的映射操作,并允许使用null 值和null 键。(除了非同步和允许使用null 之外,HashMap 类与Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
特点
- 底层数据结构是哈希表,并且数据结构仅仅针对Map的Key有效,和值无关。
- HashMap去除重复元素依赖hashCode和equals方法
- 如果HashMap中的元素的键是系统类,则不需要重写hashCode和equals方法,如果元素的键是自定义对象,则需要自己手动重写hashCode和equals方法,重写的规则可以自动生成,快捷键 Alt + Shift + S再按H。
注意: 之前讲解HashSet的时候已经分析过HashMap底层源码实现,这里就不在一一阐述。
代码示例
使用HashMap存储元素,键是员工对象,值员工工资
public class HashMapDemo01 {
public static void main(String[] args) {
HashMap<Employee, Double> hs = new HashMap<>();
hs.put(new Employee("张三", 800.0), 800.0);
hs.put(new Employee("李四", 1500.0), 1500.0);
hs.put(new Employee("李四", 1500.0), 1500.0);
hs.put(new Employee("王五", 3000.0), 3000.0);
hs.put(new Employee("王五", 3000.0), 3000.0);
Set<Employee> keys = hs.keySet();
for (Employee e : keys) {
Double salary = hs.get(e);
System.out.println(e + "=" + salary);
}
}
}
class Employee {
private String name;
private Double salary;
public Employee() {
super();
}
public Employee(String name, Double salary) {
super();
this.name = name;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
@Override
public String toString() {
return "Employee [name=" + name + ", salary=" + salary + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + ((salary == null) ? 0 : salary.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (salary == null) {
if (other.salary != null)
return false;
} else if (!salary.equals(other.salary))
return false;
return true;
}
}
TreeMap
概述
基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的Comparator 进行排序,具体取决于使用的构造方法。
特点
- 底层数据结构是红黑树,数据结构仅针对TreeMap的键有效,和值无关
- TreeMap依赖二叉树取中序遍历去元素的特点能够实现元素自动排序
- TreeMap依赖二叉树存储的特点能够去除重复元素
- TreeMap的两种排序方式是如何实现
a.自然排序
使用TreeMap的无参构造方法
b.比较器排序
使用TreeMap的带Comparotor接口参数的构造方法
注意: 之前已经针对TreeMap源码做了详细的分析,这里不再一一阐述。
示例代码
public class TreeMapDemo01 {
public static void main(String[] args) {
TreeMap<Integer, String> tm = new TreeMap<>();
tm.put(100, "张三");
tm.put(100, "张三");
tm.put(25, "李四");
tm.put(31, "王五");
tm.put(31, "王五");
tm.put(18, "赵六");
tm.put(71, "孙七");
tm.put(25, "李四");
for(Integer key : tm.keySet()) {
System.out.println(key + "=" + tm.get(key));
}
}
}
LinkedHashMap类
概述
Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现与HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。注意,如果在映射中重新插入 键,则插入顺序不受影响。
特点
- 底层数据结构是链表+ 哈希表
- 链表保证元素有序
- 哈希表保证元素唯一
示例代码
public class LinkedHashMapDemo01 {
public static void main(String[] args) {
LinkedHashMap<String, String> lhm = new LinkedHashMap<>();
lhm.put("abc", "asldajdl");
lhm.put("efg", "dsad");
lhm.put("hahah", "gag");
lhm.put("ooo", "hg");
lhm.put("abc", "ww");
lhm.put("ooo", "hsh");
System.out.println(lhm);
}
}EnumMap
概述
与枚举类型键一起使用的专用Map 实现。枚举映射中所有键都必须来自单个枚举类型,该枚举类型在创建映射时显式或隐式地指定。枚举映射在内部表示为数组。此表示形式非常紧凑且高效。
代码示例
public class EnumMapDemo01 {
public static void main(String[] args) {
EnumMap<Direction, String> em = new EnumMap<>(Direction.class);
em.put(Direction.UP, "向上移动");
em.put(Direction.LEFT, "向左移动");
em.put(Direction.RIGHT, "向右移动");
em.put(Direction.DOWN, "向下移动");
Set<Direction> keys = em.keySet();
for (Direction key : keys) {
String value = em.get(key);
System.out.println(key + "=" + value);
}
}
}
enum Direction {
UP, LEFT, RIGHT, DOWN
}
Collections工具类
类java.util.Collections 提供了对Set、List、Map操作的工具方法。
- void sort(List) //对List容器内的元素排序,
//排序的规则是按照升序进行排序。
- void shuffle(List) //对List容器内的元素进行随机排列
- void reverse(List) //对List容器内的元素进行逆续排列
- void fill(List, Object) //用一个特定的对象重写整个List容器
- int binarySearch(List, Object)//对于顺序的List容器,采用折半查找的 //方法查找特定对象
List aList = new ArrayList();
for (int i = 0; i < 5; i++)
aList.add("a" + i);
System.out.println(aList);
Collections.shuffle(aList); // 随机排列
System.out.println(aList);
Collections.reverse(aList); // 逆续
System.out.println(aList);
Collections.sort(aList); // 排序
System.out.println(aList);
System.out.println(Collections.binarySearch(aList, "a2"));
Collections.fill(aList, "hello");
System.out.println(aList);














 5155
5155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









