







以HashSet举例
public class test {
public static void main(String[] args) {
Set<Student> set = new HashSet<>();
set.add(new Student("zhangsan", 18));
set.add(new Student("lisi", 20));
set.add(new Student("wangwu", 22));
set.add(new Student("wangwu", 22));// 打断点
set.forEach(System.out::println);
}
@AllArgsConstructor
@NoArgsConstructor
@ToString
private static class Student{
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
}
- 我们可以注释掉重写的两个方法
运行结果
test.Student(name=zhangsan, age=18)
test.Student(name=wangwu, age=22)
test.Student(name=wangwu, age=22)
test.Student(name=lisi, age=20)
发现HashSet明明自动去重,为什么有两个一样的test.Student(name=wangwu, age=22)
因为HashSet底层是一个HashMap,而HashMap在调用put方法时会先通过Object.hashCode方法并对length取余( hash%length计算机中直接求余效率不如位移运算。所以源码中做了优化,使用 hash&(length-1),而实际上hash%length等于hash&(length-1)的前提是length是2的n次幂 ),而Object.hashCode是通过内存地址计算的,两个对象存储在不同的内存地址,他们的hashCode%length大概率不同,如果碰巧余数相同,在下一步会对产生hash碰撞的对象.equals(HashMap中被碰撞的对象),而我们没有重写equals方法就会调用Object.equals(),它的源代码如下:是直接通过对比内存地址判断的
public boolean equals(Object obj) {
return (this == obj);
}
所以如果我们不重写hashCode方法,两个属性内容一样的对象将可能不会产生hash碰撞
如果不重写equals方法,两个属性内容一样的对象使用equals方法将一定不会返回true
- 注释hashCode
注释后我们来进行debug
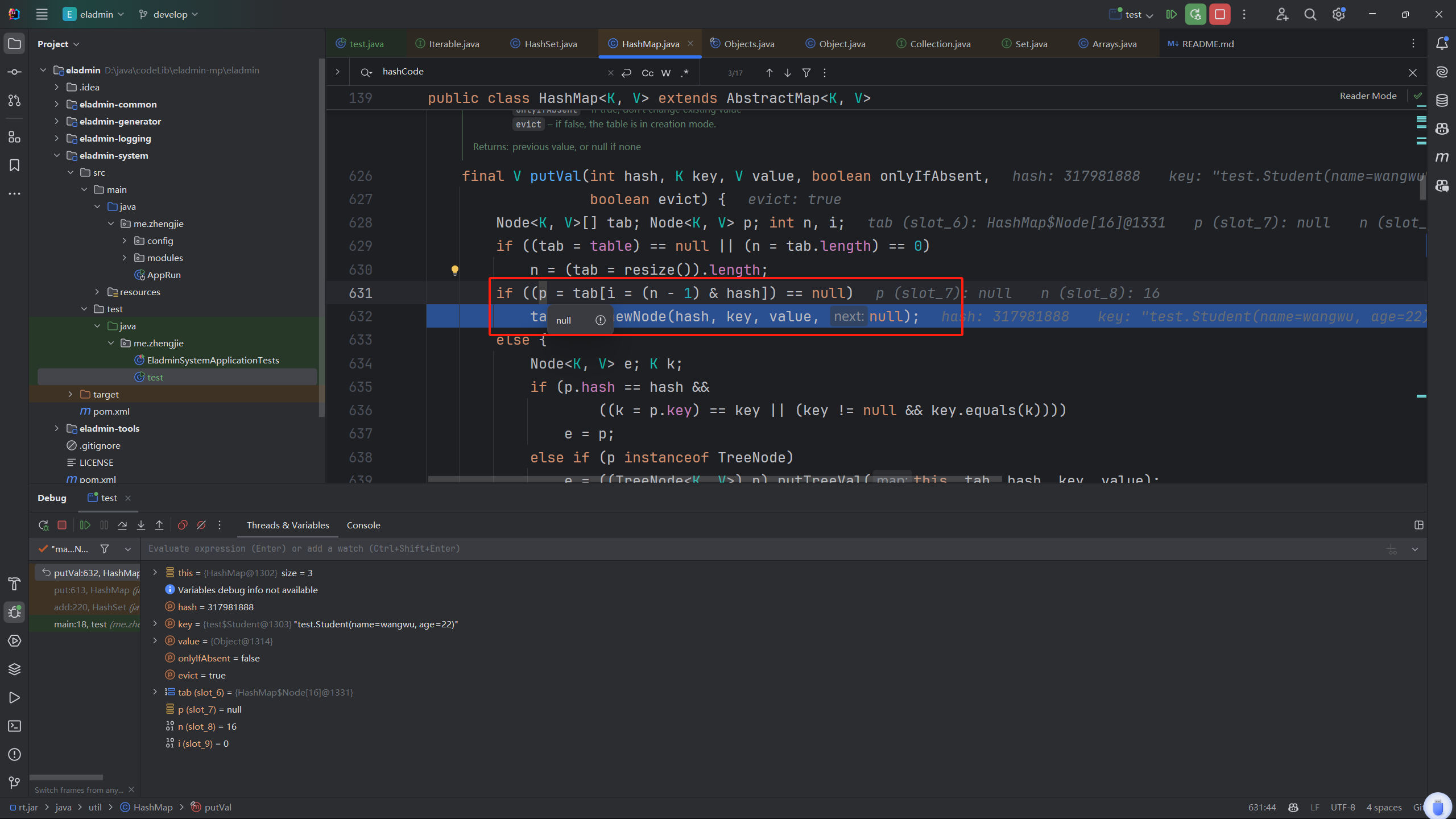
发现走进了hash无碰撞的判断中,可是这是我们第二个王五!!!
所以说明在不重写hashCode的情况下,我们直觉上相同的对象hashCode却不同。
- 注释equals不注释hashCode
再进行debug
发现hash碰撞了
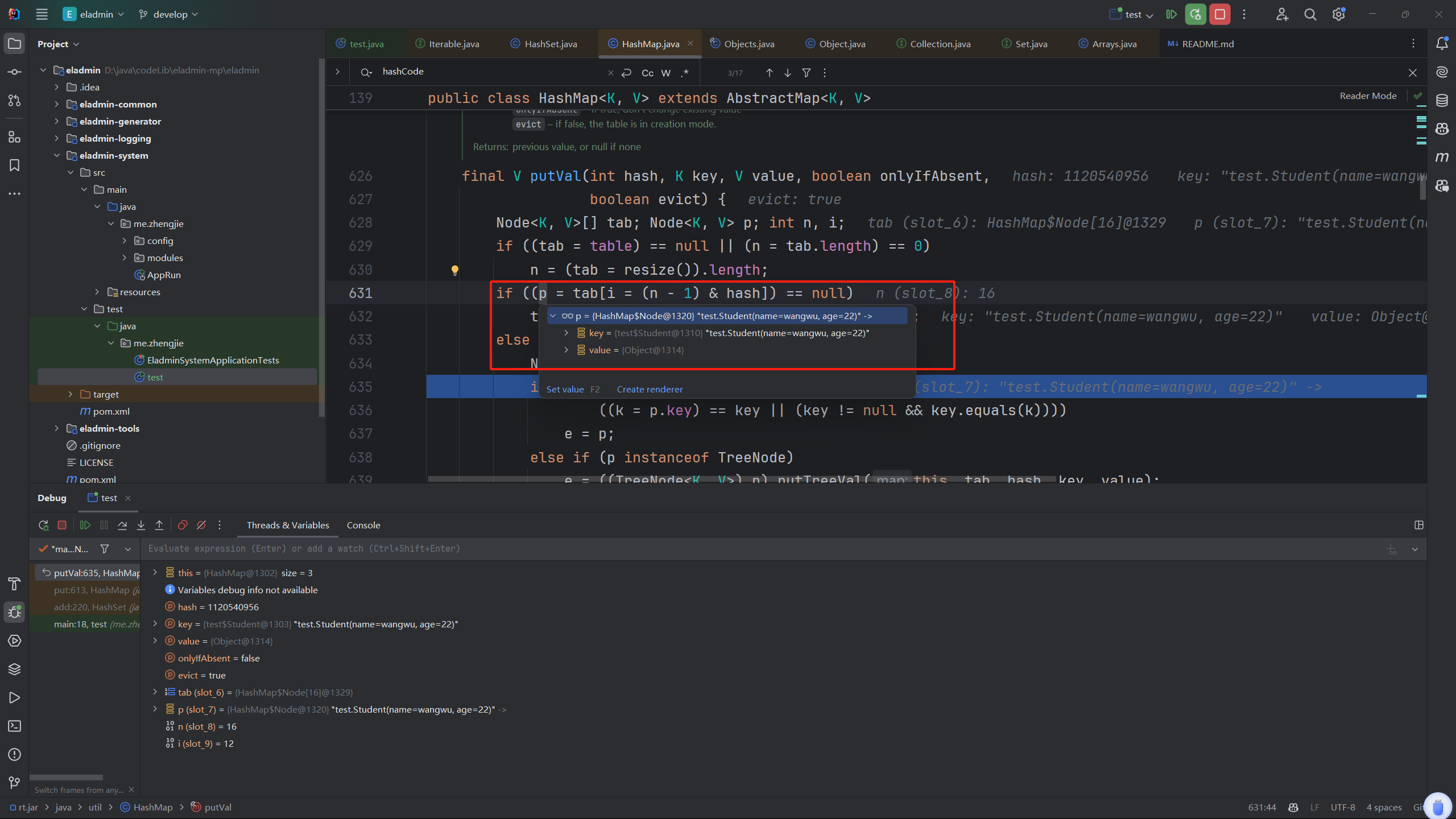
接下来发现调用了Object的equals方法,判断出来
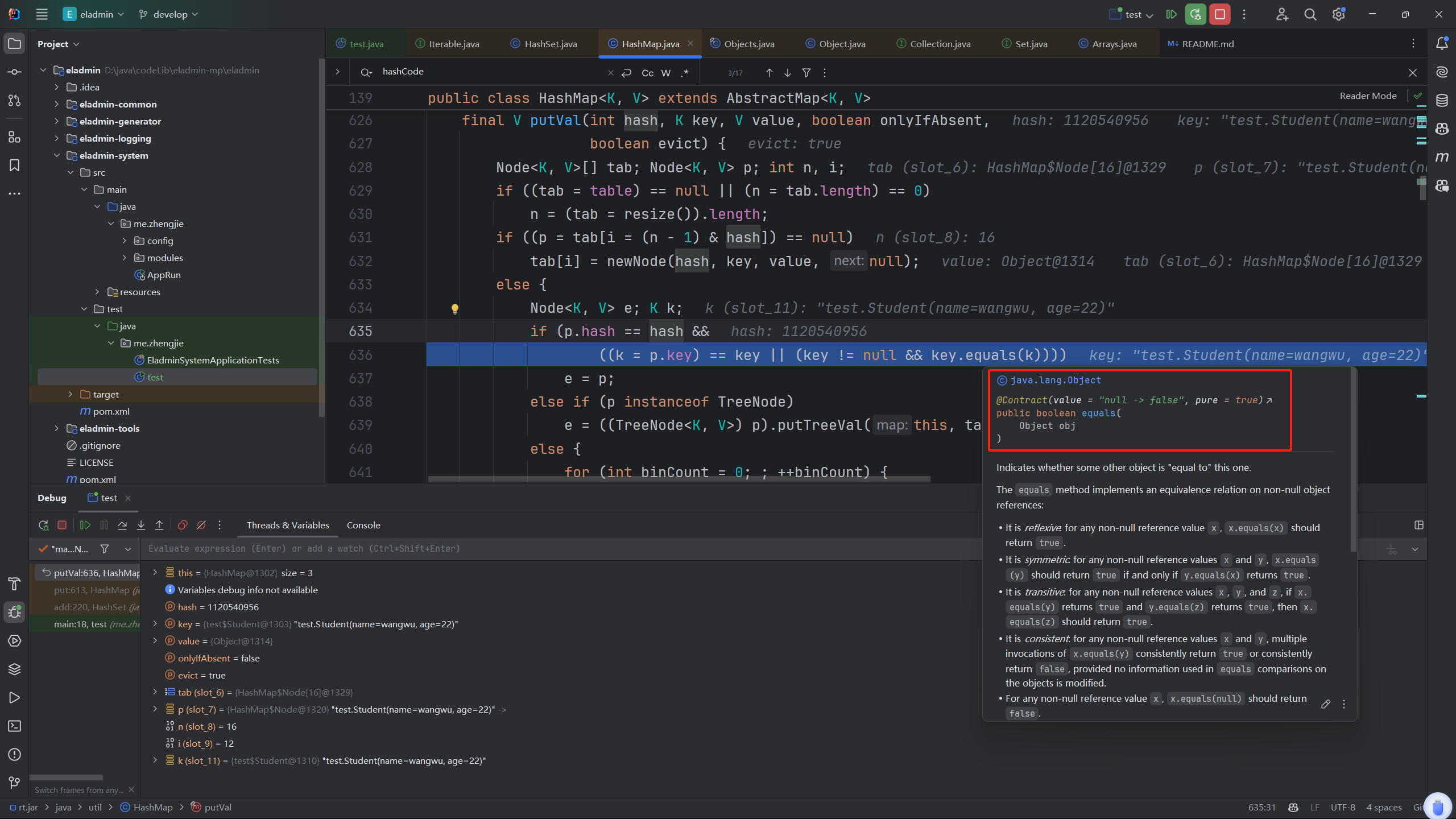
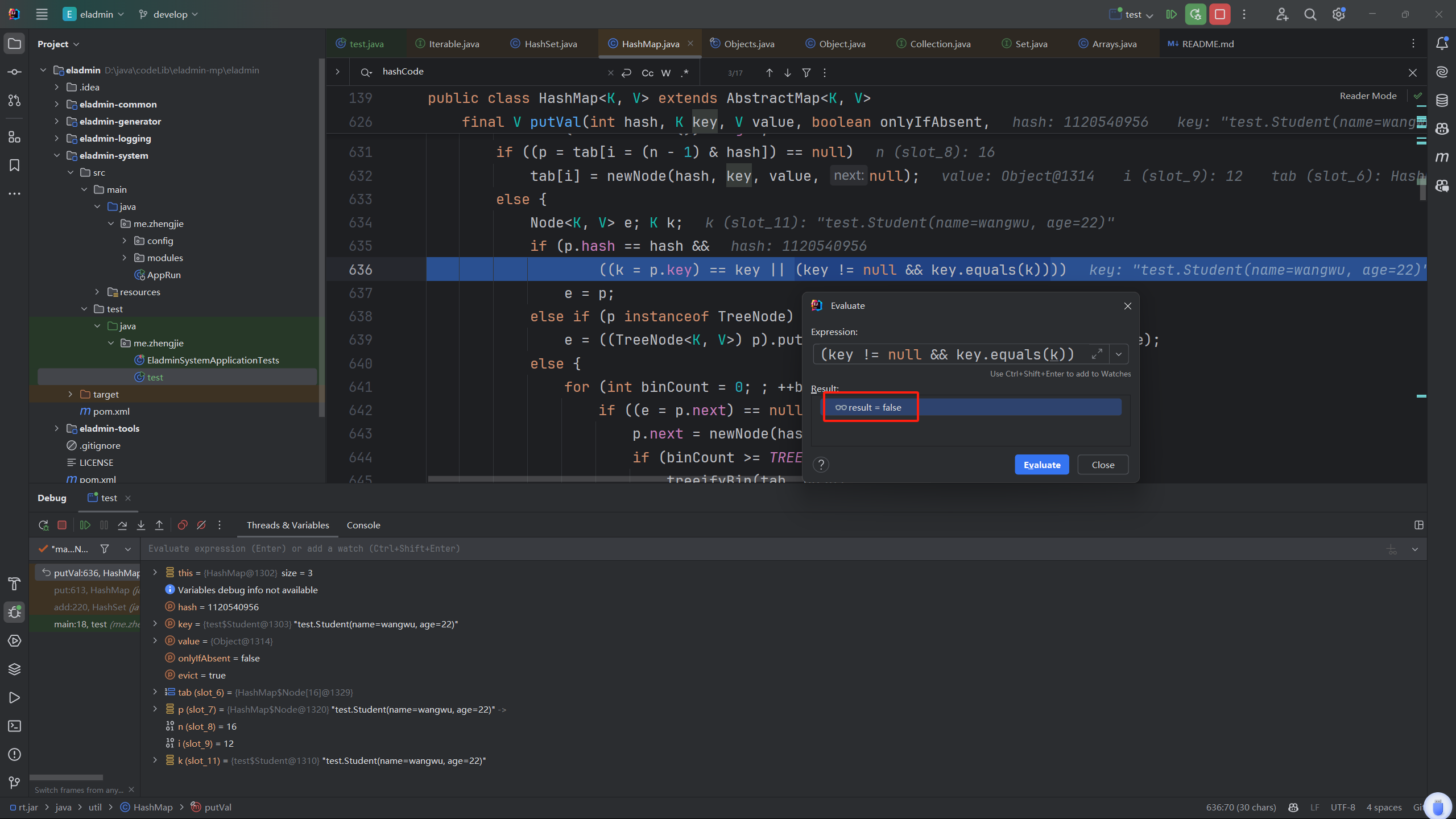
发现明明两个王五equals的结果居然是false
所以说明在不重写equals的情况下,我们直觉上相同的对象却不同。















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









