






pytroch实现mnist手写数字识别实验
- 导入必要的库:torch、torch.nn、torch.optim、torchvision.datasets、torchvision.transforms、torch.utils.data.DataLoader
- 定义超参数:
o batch_size:每个训练批次的样本数
o num_epochs:训练的总轮数
o learning_rate:学习率
o dropout_rate:Dropout层的丢弃率 - 数据加载和预处理:
o 定义数据增强和预处理的转换方法,如transforms.RandomHorizontalFlip()、transforms.RandomRotation()、transforms.ToTensor()等
o 加载MNIST训练集和测试集,应用数据转换 - 创建数据加载器:
o 创建训练集和测试集的数据加载器,将数据分为批次加载 - 定义全连接神经网络模型:
o 创建一个继承自torch.nn.Module的类,定义模型的结构和前向传播过程。
o 可以选择合适的激活函数、隐藏层神经元数量等 - 将模型移动到设备上:
o 检查是否有可用的GPU,若有,则将模型和数据加载到GPU上进行运算 - 定义损失函数和优化器:
o 定义损失函数,常用的是交叉熵损失函数torch.nn.CrossEntropyLoss()
o 定义优化器,常用的是Adam优化器torch.optim.Adam() - 训练模型:
o 进行num_epochs次的训练循环
o 在每个epoch中,遍历训练集中的每个批次,进行前向传播、计算损失、反向传播和优化模型的参数
o 在每个epoch结束后,在测试集上评估模型的性能,计算准确率等指标
o运行结果
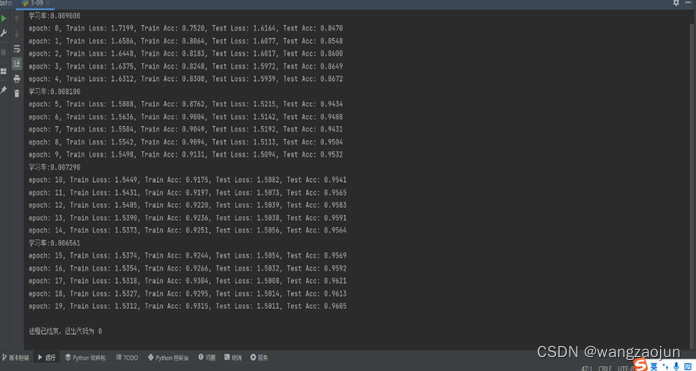
o 绘制Loss和ACC图:
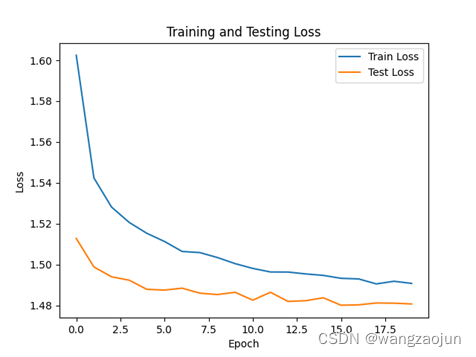
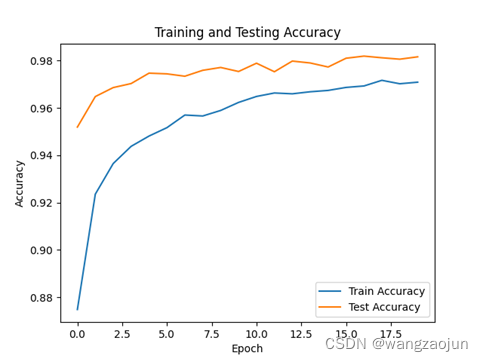
- 实验总结:
o 分析不同参数配置对模型性能的影响,如Batch Size、Epoch、学习率、优化器等
1.Batch Size: 较小的Batch Size可以加速训练过程,但可能导致模型收敛较慢,较大的Batch Size可以加快收敛速度,但可能会增加内存占用和计算负担。一般而言,较小的Batch Size可用于小型数据集,较大的Batch Size适用于大型数据集。
2.Epoch:较小的Epoch数可能无法充分训练模型,导致欠拟合。较大的Epoch数可能会过拟合模型,导致对训练集过度拟合。在验证集上的性能不再提高或出现过拟合时,可提前停止训练,避免不必要的计算开销。
3.学习率:较小的学习率可能导致收敛速度较慢。较大的学习率可能导致训练过程不稳定或错过最优解。可以使用学习率调度器(如torch.optim.lr_scheduler)来动态调整学习率,如学习率衰减或按需调整。
4.优化器: Adam优化器通常适用于大多数情况,具有自适应学习率机制。SGD优化器可能需要更仔细的参数调整,如动量、学习率衰减等,对模型性能的影响较敏感。
o 观察采用数据增强、Dropout等方法对模型性能的影响
1.数据增强:通过数据增强方法(如镜像翻转、随机旋转、平移等)扩充训练集,可以增加模型的泛化能力,提供更多的样本变化,帮助模型更好地学习对不同输入变化的鲁棒性。 - Dropout: Dropout层在训练过程中随机丢弃部分神经元,减少过拟合现象。Dropout的丢弃率需要根据具体情况进行选择,通常在0.5左右。
o 总结实验过程中遇到的问题和解决方法,以及对模型的改进方向
1.过拟合:如果模型在训练集上的准确率很高,但在测试集上表现较差,可能出现过拟合现象。这时可以通过增加训练集的大小、采用数据增强方法、添加正则化项、使用Dropout等方法来降低过拟合。 - 超参数调整:不同的超参数配置可能对模型性能有不同的影响,需要进行调试和优化。可以通过网格搜索、随机搜索、学习曲线分析等方法来选择合适的超参数组合。
实验完整代码:
import torchvision.datasets as datasets
# 下载并加载训练集
train_dataset = datasets.MNIST(root='../data/', train=True, download=True)
# 下载并加载测试集
test_dataset = datasets.MNIST(root='../data/', train=False, download=True)
# 其他代码...
import numpy as np
import torch
# 导入 pytorch 内置的 mnist 数据
from torchvision.datasets import mnist
# import torchvision
# 导入预处理模块-+
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 导入nn及优化器
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
# from torch.utils.tensorboard import SummaryWriter
# 定义一些超参数
train_batch_size = 8
test_batch_size = 8
learning_rate = 0.01
num_epoches = 20
# 定义预处理函数
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.5],
[0.5])])
#使用数据增强
# transform = transforms.Compose([
# transforms.RandomRotation(10), # 随机旋转10度
# transforms.RandomHorizontalFlip(), # 随机水平翻转
# transforms.ToTensor(),
# transforms.Normalize([0.5], [0.5])
# ])
# 下载数据,并对数据进行预处理
train_dataset = mnist.MNIST('../data/',
train=True,
transform=transform,
download=False)
test_dataset = mnist.MNIST('../data/',
train=False,
transform=transform)
# 得到一个生成器
train_loader = DataLoader(train_dataset,
batch_size=train_batch_size,
shuffle=True)
test_loader = DataLoader(test_dataset,
batch_size=test_batch_size,
shuffle=False)
class Net(nn.Module):
"""
使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Net, self).__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.BatchNorm1d(n_hidden_1))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.BatchNorm1d(n_hidden_2))
self.out = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x = self.flatten(x)
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = F.softmax(self.out(x), dim=1)
return x
lr = 0.01
momentum = 0.9
# 实例化模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Net(28 * 28, 300, 100, 10)
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
# 开始训练
losses = []
acces = []
eval_losses = []
eval_acces = []
for epoch in range(num_epoches):
train_loss = 0
train_acc = 0
model.train()
# 动态修改参数学习率
if epoch % 5 == 0:
optimizer.param_groups[0]['lr'] *= 0.9
print("学习率:{:.6f}".format(optimizer.param_groups[0]['lr']))
for img, label in train_loader:
img = img.to(device)
label = label.to(device)
# 正向传播
out = model(img)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.item()
# 计算分类的准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
train_acc += acc
losses.append(train_loss / len(train_loader))
acces.append(train_acc / len(train_loader))
# 在测试集上检验效果
eval_loss = 0
eval_acc = 0
# net.eval() # 将模型改为预测模式
model.eval()
for img, label in test_loader:
img = img.to(device)
label = label.to(device)
img = img.view(img.size(0), -1)
out = model(img)
loss = criterion(out, label)
# 记录误差
eval_loss += loss.item()
# 记录准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_loader))
eval_acces.append(eval_acc / len(test_loader))
print('epoch: {}, Train Loss: {:.4f}, Train Acc: {:.4f}, Test Loss: {:.4f}, Test Acc: {:.4f}'
.format(epoch, train_loss / len(train_loader), train_acc / len(train_loader),
eval_loss / len(test_loader), eval_acc / len(test_loader)))
import matplotlib.pyplot as plt
# 绘制损失图表
plt.plot(losses, label='Train Loss')
plt.plot(eval_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Testing Loss')
plt.legend()
plt.show()
# 绘制准确率图表
plt.plot(acces, label='Train Accuracy')
plt.plot(eval_acces, label='Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training and Testing Accuracy')
plt.legend()
plt.show()

















 3837
3837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











