







基于PaddleNLP开源的抽取式UIE进行医学命名实体识别
简介
UIE(Universal Information Extraction)是Yaojie Lu等人在ACL-2022中提出了通用信息抽取统一框架。PaddleNLP借鉴该论文的方法,基于ERNIE 3.0知识增强预训练模型,开源了基于Prompt的抽取式UIE。
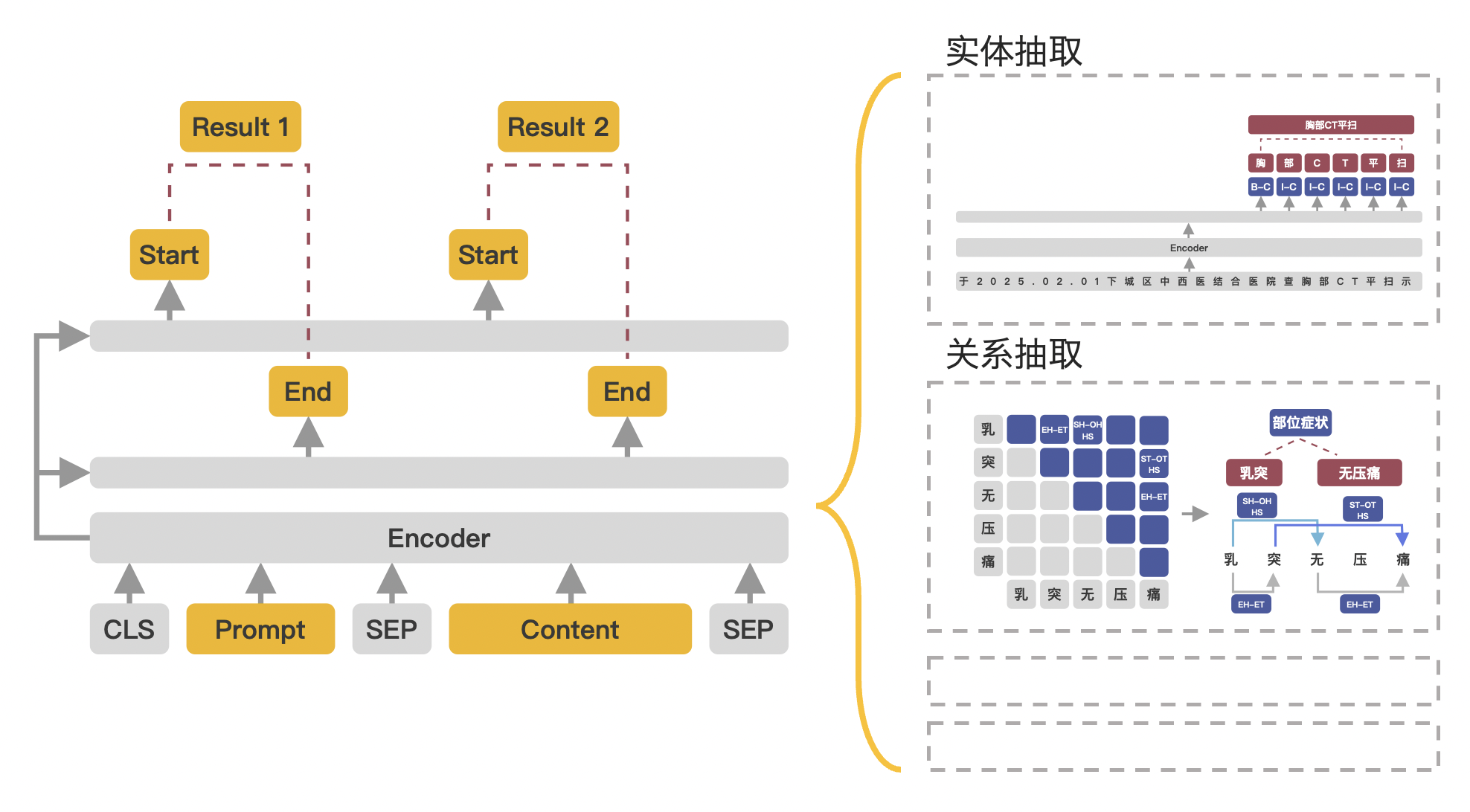
本项目使用torch进行复现微调,并在CMeEE数据集上进行效果测试。本项目仅做了命名实体部分,后续会在ark-nlp项目中加入关系抽取和事件抽取等任务。
数据下载
- CMeEE:https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414
环境
pip install ark-nlp
pip install pandas
使用说明
项目目录按以下格式设置
│
├── data # 数据文件夹
│ ├── source_datasets
│ ├── task_datasets
│ └── output_datasets
│
├── checkpoint # 存放训练好的模型
│ ├── ...
│ └── ...
│
└── example.ipynb # 代码
下载数据并解压到data/source_datasets中,运行example.ipynb文件
import warnings
warnings.filterwarnings("ignore")
import os
import jieba
import torch
import pickle
import torch.nn as nn
import torch.optim as optim
import pandas as pd
from tokenizer import TransfomerTokenizer as Tokenizer
from utils import convert_ner_task_uie_df
from prompt_uie import PromptUIE as Module
from prompt_uie_information_extraction_dataset import PromptUIEDataset as Dataset
from prompt_uie_information_extraction_task import PromptUIETask as Task
from ark_nlp.nn import BertConfig as ModuleConfig
from ark_nlp.factory.optimizer import get_default_bert_optimizer as get_default_model_optimizer
train_data_path = './data/source_datasets/CMeEE/CMeEE_train.json'
dev_data_path = './data/source_datasets/CMeEE/CMeEE_dev.json'
model_path = 'freedomking/prompt-uie-base'
一、数据读入与处理
1.1 数据读入
train_data_df = pd.read_json(train_data_path)
dev_data_df = pd.read_json(dev_data_path)
train_data_df = train_data_df.rename(columns={'entities': 'label'})
dev_data_df = dev_data_df.rename(columns={'entities': 'label'})
type2name = {
'dis': '疾病',
'sym': '临床表现',
'pro': '医疗程序',
'equ': '医疗设备',
'dru': '药物',
'ite': '医学检验项目',
'bod': '身体',
'dep': '科室',
'mic': '微生物类'
}
def convert_entity_type(labels):
converted_labels = []
for label in labels:
converted_labels.append({
'start_idx': label['start_idx'],
'end_idx': label['end_idx'],
'type': type2name[label['type']],
'entity': label['entity']
})
return converted_labels
train_data_df['label'] = train_data_df['label'].apply(lambda x: convert_entity_type(x))
dev_data_df['label'] = dev_data_df['label'].apply(lambda x: convert_entity_type(x))
train_data_df = convert_ner_task_uie_df(train_data_df, negative_ratio=2)
dev_data_df = convert_ner_task_uie_df(dev_data_df, negative_ratio=0)
ner_train_dataset = Dataset(train_data_df)
ner_dev_dataset = Dataset(dev_data_df)
2. 词典创建和生成分词器
tokenizer = Tokenizer(vocab=model_path, max_seq_len=100)
3. ID化
ner_train_dataset.convert_to_ids(tokenizer)
ner_dev_dataset.convert_to_ids(tokenizer)
二、模型构建
1. 模型参数设置
config = ModuleConfig.from_pretrained(model_path)
2. 模型创建
torch.cuda.empty_cache()
dl_module = Module.from_pretrained(model_path, config=config)
三、任务构建
1. 任务参数和必要部件设定
设置运行次数
num_epoches = 5
batch_size = 32
optimizer = get_default_model_optimizer(dl_module)
2. 任务创建
model = Task(dl_module, optimizer, None, cuda_device=0)
```
### 3. 训练
```
model.fit(ner_train_dataset,
ner_dev_dataset,
lr=1e-5,
epochs=num_epoches,
batch_size=batch_size
)
import json
from tqdm import tqdm
from prompt_uie_information_extraction_predictor import PromptUIEPredictor as Predictor
ner_predictor_instance = Predictor(model.module, tokenizer)
test_df = pd.read_json('./data/source_datasets/CMeEE/CMeEE_test.json')
submit = []
for _text in tqdm(test_df['text'].to_list()):
entities = []
for source_type, prompt_type in type2name.items():
for entity in ner_predictor_instance.predict_one_sample([_text, prompt_type]):
entities.append({
'start_idx': entity['start_idx'],
'end_idx': entity['end_idx'],
'type': source_type,
'entity': entity['entity'],
})
submit.append({
'text': _text,
'entities': entities
})
output_path = './submit_CMeEE_test.json'
with open(output_path,'w', encoding='utf-8') as f:
f.write(json.dumps(submit, ensure_ascii=False))
权重文件
为了方便使用,已将paddle模型的权重转化成huggingface的格式,并上传至huggingface:https://huggingface.co/freedomking/prompt-uie-base

效果
运行一到两轮后提交至CBLUE进行测评,大概在65-66左右,已高于大部分的基线模型
















 7458
7458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











