







PP-Structure 快速入门
- 1. 环境准备
- 2.快速使用
- 2.1 命令行使用
- 2.1.1 图像定位+布局分析+表格识别
- 2.1.2 布局分析+表格识别
- 2.1.3 布局分析
- 2.1.4 表格识别
- 2.1.5 关键信息提取
- 2.1.6 布局恢复
- 2.2 python 脚本使用
- 2.2.1 图像方向+布局分析+表格识别
- 2.2.2 布局分析+表格识别
- 2.2.3 布局分析
- 2.2.4 表格识别
- 2.2.5 关键信息提取
- 2.2.6 布局恢复
- 2.3 结果描述
- 2.3.1 布局分析+表格识别
- 2.3.2 关键信息提取
-2.4 参数说明
-3. 概要
English | 简体中文
PP-Structure 文档分析
1. 简介
PP-Structure是PaddleOCR团队自研的智能文档分析系统,旨在帮助开发者更好的完成版面分析、表格识别等文档理解相关任务。
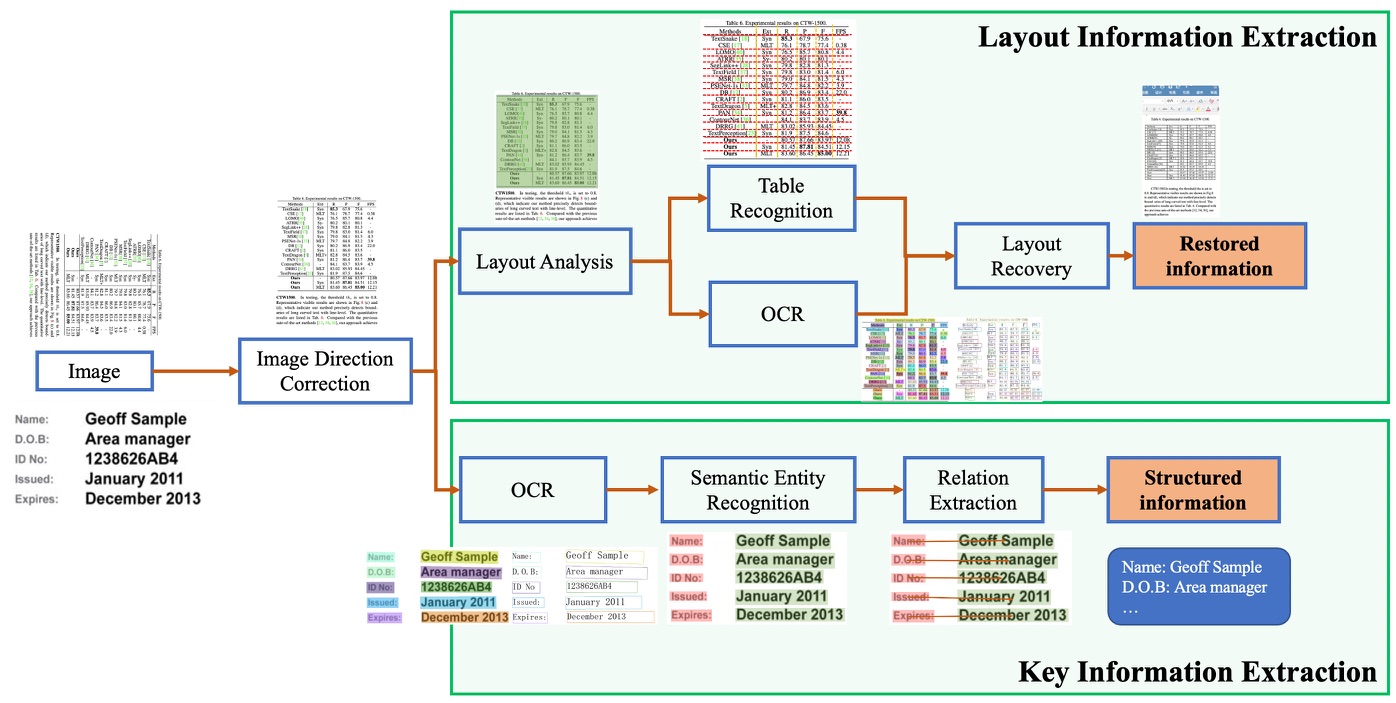
PP-StructureV2系统流程图如下所示,文档图像首先经过图像矫正模块,判断整图方向并完成转正,随后可以完成版面信息分析与关键信息抽取2类任务。
- 版面分析任务中,图像首先经过版面分析模型,将图像划分为文本、表格、图像等不同区域,随后对这些区域分别进行识别,如,将表格区域送入表格识别模块进行结构化识别,将文本区域送入OCR引擎进行文字识别,最后使用版面恢复模块将其恢复为与原始图像布局一致的word或者pdf格式的文件;
- 关键信息抽取任务中,首先使用OCR引擎提取文本内容,然后由语义实体识别模块获取图像中的语义实体,最后经关系抽取模块获取语义实体之间的对应关系,从而提取需要的关键信息。
更多技术细节:👉 PP-StructureV2技术报告 中文版,英文版。
PP-StructureV2支持各个模块独立使用或灵活搭配,如,可以单独使用版面分析,或单独使用表格识别,点击下面相应链接获取各个独立模块的使用教程:
2. 特性
PP-StructureV2的主要特性如下:
- 支持对图片/pdf形式的文档进行版面分析,可以划分文字、标题、表格、图片、公式等区域;
- 支持通用的中英文表格检测任务;
- 支持表格区域进行结构化识别,最终结果输出Excel文件;
- 支持基于多模态的关键信息抽取(Key Information Extraction,KIE)任务-语义实体识别(Semantic Entity Recognition,SER)和关系抽取(Relation Extraction,RE);
- 支持版面复原,即恢复为与原始图像布局一致的word或者pdf格式的文件;
- 支持自定义训练及python whl包调用等多种推理部署方式,简单易用;
- 与半自动数据标注工具PPOCRLabel打通,支持版面分析、表格识别、SER三种任务的标注。
3. 效果展示
PP-StructureV2支持各个模块独立使用或灵活搭配,如,可以单独使用版面分析,或单独使用表格识别,这里仅展示几种代表性使用方式的可视化效果。
3.1 版面分析和表格识别
下图展示了版面分析+表格识别的整体流程,图片先有版面分析划分为图像、文本、标题和表格四种区域,然后对图像、文本和标题三种区域进行OCR的检测识别,对表格进行表格识别,其中图像还会被存储下来以便使用。
3.1.1 版面识别返回单字坐标
下图展示了基于上一节版面分析对文字进行定位的效果, 可参考文档。
3.2 版面恢复
下图展示了基于上一节版面分析和表格识别的结果进行版面恢复的效果。
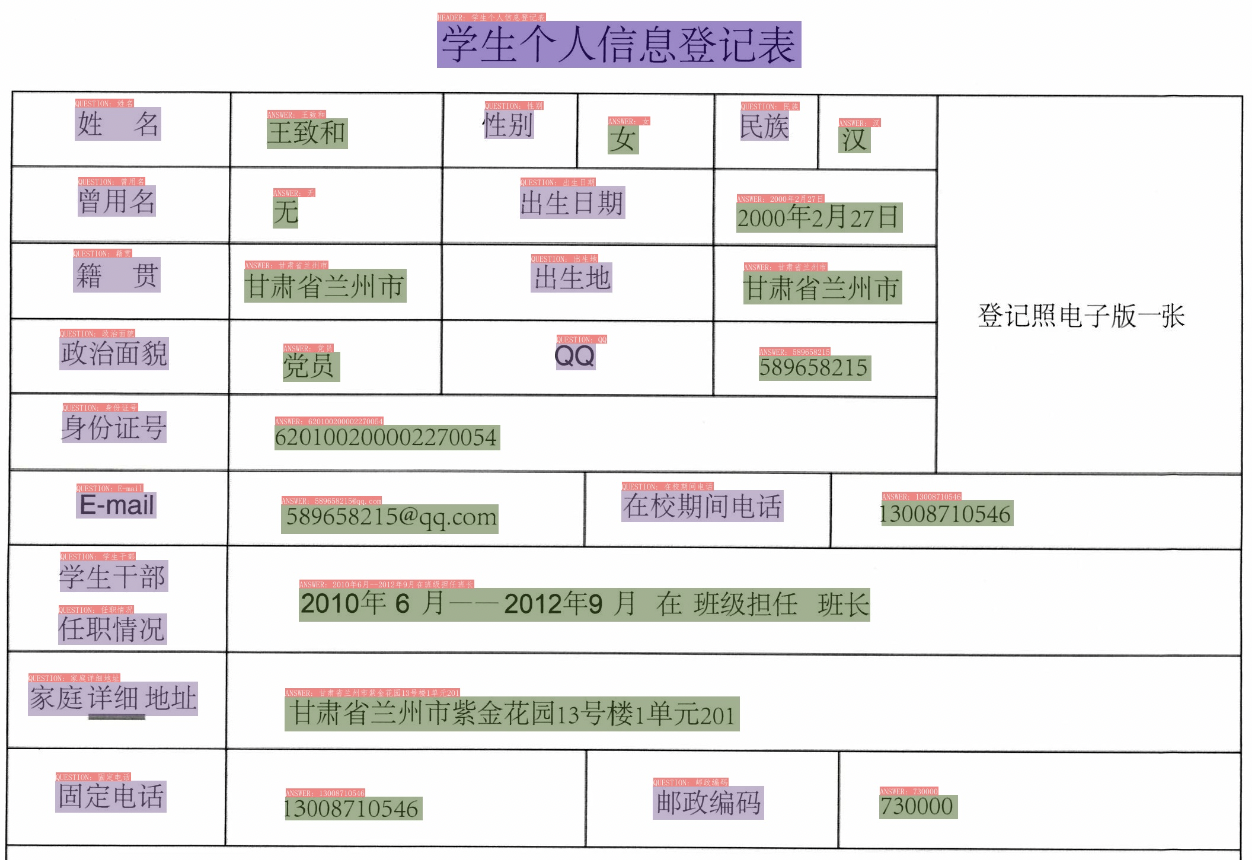
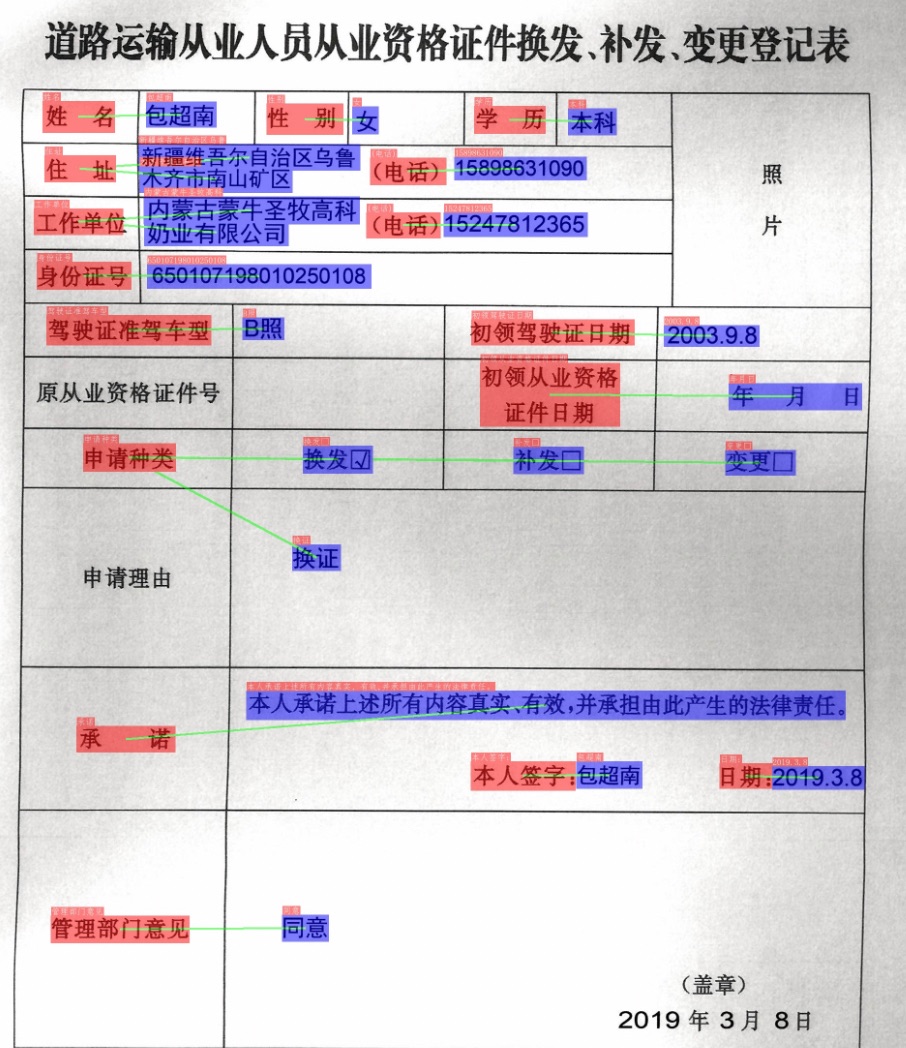
3.3 关键信息抽取
- SER
图中不同颜色的框表示不同的类别。


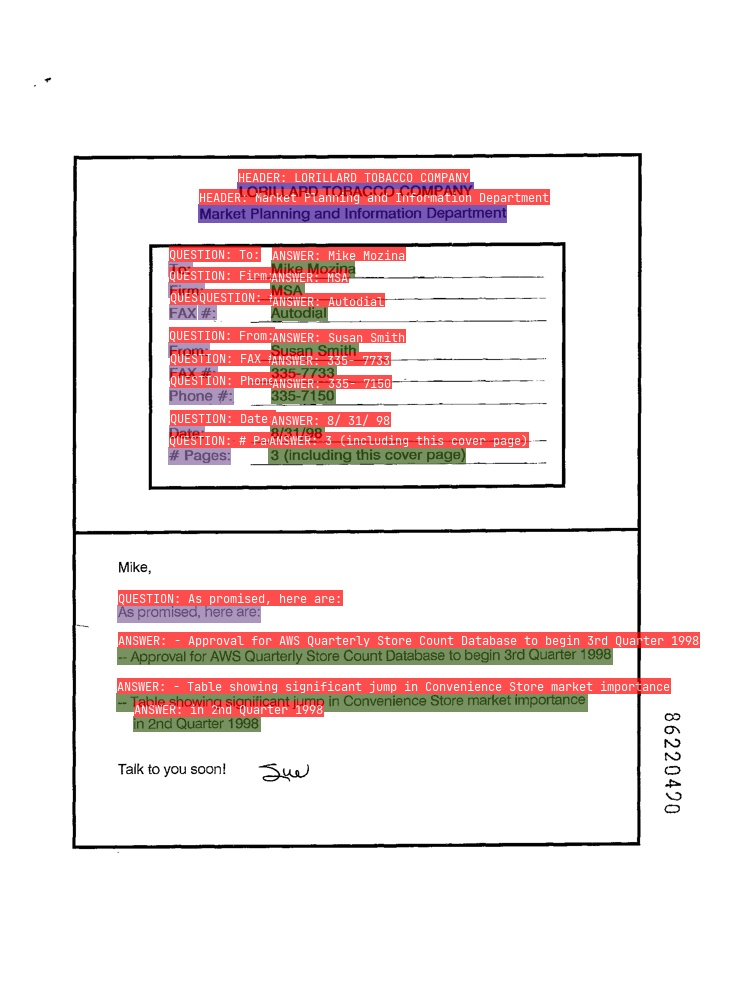

- RE
图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。
4. 快速体验
请参考快速使用教程。
5. 模型库
部分任务需要同时用到结构化分析模型和OCR模型,如表格识别需要使用表格识别模型进行结构化解析,同时也要用到OCR模型对表格内的文字进行识别,请根据具体需求选择合适的模型。
结构化分析相关模型下载可以参考:
OCR相关模型下载可以参考:
1. 环境准备
1.1 安装 PaddlePaddle
如果你没有 Python 环境,请参考 环境准备。
- 如果你的机器上安装了 CUDA 9 或 CUDA 10,请运行以下命令进行安装
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
- 如果你的机器上没有可用的 GPU,请运行以下命令安装 CPU 版本
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
更多软件版本要求请参考安装文档中的说明进行操作。
1.2 安装PaddleOCR Whl包
# 安装paddleocr,建议2.6版本
pip3 install "paddleocr>=2.6.0.3"
# 安装图片方向分类依赖包paddleclas(如果不用图片方向分类可以跳过)
pip3 install paddleclas>=2.4.3
2. 快速使用
2.1 命令行使用
2.1.1 图像方向+布局分析+表格识别
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --image_orientation=true
2.1.2 布局分析+表格识别
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure
2.1.3 布局分析
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --table=false --ocr=false
2.1.4 表格识别
paddleocr --image_dir=ppstructure/docs/table/table.jpg --type=structure --layout=false
2.1.5 关键信息提取
关键信息提取目前不支持 whl 包使用,详细使用教程请参考:推理文档。
2.1.6 布局恢复(PDF 转 Word)
提供两种布局恢复方式,详细使用教程请参考:布局恢复。
- PDF解析
- OCR
使用PDF解析恢复(仅支持pdf作为输入):
paddleocr --image_dir=ppstructure/docs/recovery/UnrealText.pdf --type=structure --recovery=true --use_pdf2docx_api=true
使用OCR恢复:
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --recovery=true --lang='en'
2.2 python脚本使用
2.2.1 图像方向+布局分析+表格识别
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine = PPStructure(show_log=True, image_orientation=True)
save_folder = './output'
img_path = 'ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
from PIL import图片
font_path = 'doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
2.2.2 布局分析+表格识别
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine = PPStructure(show_log=True)
save_folder = './output'
img_path = 'ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
from PIL import Image
font_path = 'doc/fonts/simfang.ttf' # PaddleOCR 提供的字体
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
2.2.3 布局分析
import os
import cv2
from paddleocr import PPStructure,save_structure_res
table_engine = PPStructure(table=False,ocr=False,show_log=True)
save_folder = './output'
img_path = 'ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result,save_folder,os.path.basename(img_path)。split('.')[0])
对于结果中的行:
line.pop('img')
print(line)
import os
import cv2
from paddleocr import PPStructure,save_structure_res
ocr_engine = PPStructure(table=False, ocr=True, show_log=True)
save_folder = './output'
img_path = 'ppstructure/docs/recovery/UnrealText.pdf'
result = ocr_engine(img_path)
for index, res in enumerate(result):
save_structure_res(res, save_folder, os.path.basename(img_path).split('.')[0], index)
for res in result:
for line in res:
line.pop('img')
print(line)
import os
import cv2
import numpy as np
from paddleocr import PPStructure,save_structure_res
from paddle.utils import try_import
from PIL import Image
ocr_engine = PPStructure(table=False, ocr=True, show_log=True)
save_folder = './output'
img_path = 'ppstructure/docs/recovery/UnrealText.pdf'
fitz = try_import("fitz")
imgs = []
with fitz.open(img_path) as pdf:
for pg in range(0, pdf.page_count):
page = pdf[pg]
mat = fitz.Matrix(2, 2)
pm = page.get_pixmap(matrix=mat, alpha=False)
# if width or height > 2000 pixels, don't enlarge the image
if pm.width > 2000 or pm.height > 2000:
pm = page.get_pixmap(matrix=fitz.Matrix(1, 1), alpha=False)
img = Image.frombytes("RGB", [pm.width, pm.height], pm.samples)
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
imgs.append(img)
for index, img in enumerate(imgs):
result = ocr_engine(img)
save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0], index)
for line in result:
line.pop('img')
print(line)
2.2.4 表格识别
import os
import cv2
from paddleocr import PPStructure,save_structure_res
table_engine = PPStructure(layout=False, show_log=True)
save_folder = './output'
img_path = 'ppstructure/docs/table/table.jpg'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
2.2.5 密钥信息提取
密钥信息提取目前不支持 whl 包使用,详细使用教程请参考:密钥信息提取。
2.2.6 布局恢复
import os
import cv2
from paddleocr import PPStructure,save_structure_res
from paddleocr.ppstructure.recovery.recovery_to_doc import sorted_layout_boxes, convert_info_docx
# Chinese image
table_engine = PPStructure(recovery=True)
# English image
# table_engine = PPStructure(recovery=True, lang='en')
save_folder = './output'
img_path = 'ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
h, w, _ = img.shape
res = sorted_layout_boxes(result, w)
convert_info_docx(img, res, save_folder, os.path.basename(img_path).split('.')[0])
2.3 结果说明
PP-Structure 返回的是一串字典,示例如下:
2.3.1 布局分析 + 表格识别
[
{ 'type': 'Text',
'bbox': [34, 432, 345, 462],
'res': ([[36.0, 437.0, 341.0, 437.0, 341.0, 446.0, 36.0, 447.0], [41.0, 454.0, 125.0, 453.0, 125.0, 459.0, 41.0, 460.0]],
[('Tigure-6. CNN 和 IPT 模型使用 difforen', 0.90060663), ('Tent ', 0.465441)])
}
]
dict中各个字段说明如下:
| field | description |
|---|---|
| type | 图片区域的类型。 |
| bbox | 图片区域在原图中的坐标,分别为[左上角x,左上角y,右下角x,右下角y]。 |
| res | 图片区域的OCR或者表格识别结果。 table:一个dict,字段说明如下: html:表格的html str。代码使用方式中,设置return_ocr_result_in_table=True,调用时可得到表格区域内每段文字的检测识别结果,对应以下字段: boxes:文字检测框。rec_res:文字识别结果。OCR:包含每段文字的检测框和识别结果的元组。 |
识别完成后,每幅图像在output字段指定的目录下都会有一个同名的目录,图像中每张表格都会被存储为excel,图片区域会被裁剪保存,excel和图片的文件名都是它们在图像中的坐标。
/output/table/1/
└─ res.txt
└─ [454, 360, 824, 658].xlsx表格识别结果
└─ [16, 2, 828, 305].jpg图片中
└─ [17, 361, 404, 711].xlsx表格识别结果
2.3.2 关键信息提取
请参考:关键信息提取 。
2.4 参数说明
| field | description | default |
|---|---|---|
| output | 结果保存路径 | ./output/table |
| table_max_len | 表格结构模型中图片长边调整大小 | 488 |
| table_model_dir | 表格结构模型推理模型路径 | None |
| table_char_dict_path | 表格结构模型字典路径 | …/ppocr/utils/dict/table_structure_dict.txt |
| merge_no_span_structure | 表格识别模型中是否合并 ‘<td>’ 和 ‘</td>’ | False |
| layout_model_dir | 布局分析模型推理模型路径 | None |
| layout_dict_path | 布局分析模型字典路径 | …/ppocr/utils/dict/layout_publaynet_dict.txt |
| layout_score_threshold | 布局分析模型的框阈值路径 | 0.5 |
| layout_nms_threshold | 布局分析模型的nms阈值路径 | 0.5 |
| kie_algorithm | kie模型算法 | LayoutXLM |
| ser_model_dir | Ser模型推理模型路径 | None |
| ser_dict_path | Ser模型的字典路径 | …/train_data/XFUND/class_list_xfun.txt |
| mode | structure or kie | structure |
| image_orientation | forward中是否进行图像方向分类 | False |
| layout | forward中是否进行布局分析 | True |
| table | forward中是否进行表格识别 | True |
| ocr | 布局分析中是否对非表格区域进行ocr,当layout为False时会自动设置为False | True |
| recovery | forward中是否进行布局恢复 | False |
| save_pdf | recovery时是否将docx转换为pdf | False |
| structure_version | 结构版本,可选PP-structure和PP-structurev2 | PP-structure |
大部分参数与PaddleOCR whl包一致,参见whl包文档
3. 总结
通过本节内容,您可以掌握通过PaddleOCR whl包使用PP-Structure相关函数的方法。更详细的使用教程包括模型训练、推理和部署等,请参考文档教程。


















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











