







引言
在上一篇博客中,我们解读了common文件中的heaptuple.cpp,接下来我们继续解读内存访问(access)文件夹下的另一个子文件夹heap,主要对heapam.cpp进行学习和解读
文件路径
opengauss-server\src\gausskernel\storage\access\heap\heapam.cpp
Function name:InitScanBlocks
定义了一个名为InitScanBlocks的函数,这个函数的主要目的是确定扫描的起始块和块数,或者提交错误信息。 完整代码以及注释如下:
/**Function name:InitScanBlocks*scan:This is a descriptor for the heap table scan. It contains information about the relation being scanned, the snapshot to use, and other scan parameters.* rangeScanInRedis:This is a structure that indicates whether the scan is a range scan in Redis and contains information about the total number of slices (sliceTotal) and the index of the current slice (sliceIndex).*Description:This code primarily initializes the block range of a HeapScanDesc (heap scan descriptor).*First, it determines the number of blocks (nblocks) that need to be scanned.*This value can be determined once at the start of the scan, as any tuples added during the scan process would be invisible to the current snapshot anyway.*/static inline void InitScanBlocks(HeapScanDesc scan, RangeScanInRedis rangeScanInRedis){BlockNumber nblocks;/** Determine the number of blocks we have to scan.** It is sufficient to do this once at scan start, since any tuples added* while the scan is in progress will be invisible to my snapshot anyway.* (That is not true when using a non-MVCC snapshot. However, we couldn't* guarantee to return tuples added after scan start anyway, since they* might go into pages we already scanned. To guarantee consistent* results for a non-MVCC snapshot, the caller must hold some higher-level* lock that ensures the interesting tuple(s) won't change.)*/if (RelationIsPartitioned(scan->rs_base.rs_rd)) {/* partition table just set Initial Value, in BitmapHeapTblNext will update */nblocks = InvalidBlockNumber;} else if (scan->rs_parallel != NULL && scan->rs_parallel->isplain) {nblocks = scan->rs_parallel->phs_nblocks;//If it's not a partitioned table, but the scan is parallel and is a plain scan,//then it will use the number of blocks from the parallel scan structure.}else {nblocks = RelationGetNumberOfBlocks(scan->rs_base.rs_rd);}if (nblocks > 0 && rangeScanInRedis.isRangeScanInRedis) {ItemPointerData start_ctid;ItemPointerData end_ctid;RelationGetCtids(scan->rs_base.rs_rd, &start_ctid, &end_ctid);//get the start_ctid and the end_ctidif (rangeScanInRedis.sliceTotal <= 1) {Assert(rangeScanInRedis.sliceIndex == 0);scan->rs_base.rs_nblocks = RedisCtidGetBlockNumber(&end_ctid) - RedisCtidGetBlockNumber(&start_ctid) + 1;scan->rs_base.rs_startblock = RedisCtidGetBlockNumber(&start_ctid);//calculate the start block and the number of blocks for the scan if the rangeScanInRedis.sliceTotal<=1} else {ItemPointer sctid = eval_redis_func_direct_slice(&start_ctid, &end_ctid, true,rangeScanInRedis.sliceTotal,rangeScanInRedis.sliceIndex);ItemPointer ectid = eval_redis_func_direct_slice(&start_ctid, &end_ctid, false,rangeScanInRedis.sliceTotal,rangeScanInRedis.sliceIndex);scan->rs_base.rs_startblock = RedisCtidGetBlockNumber(sctid);scan->rs_base.rs_nblocks = RedisCtidGetBlockNumber(ectid) - scan->rs_base.rs_startblock + 1;}//calculate the start and end CTID for each sliceereport(LOG, (errmsg("start block is %d, nblock is %d, start_ctid is %d, end_ctid is %d, sliceTotal is %d, ""sliceIndex is %d", scan->rs_base.rs_startblock, scan->rs_base.rs_nblocks, RedisCtidGetBlockNumber(&start_ctid),RedisCtidGetBlockNumber(&end_ctid), rangeScanInRedis.sliceTotal, rangeScanInRedis.sliceIndex)));} else {scan->rs_base.rs_nblocks = nblocks;}}
Function name:TrySubPartitionOidGetPartition
定义了一个名为TrySubPartitionOidGetPartition的函数,这个函数的主要目的是获得子分区的OID。 完整代码以及注释如下:
/** Functiion name: TrySubPartitionOidGetPartition* rel:a relation that represents the partitioned table* subPartOid:the OID of the sub-partition to be retrieved* lockmode:the lock mode to be applied when opening the partition* Description:This function is used to get a sub-partition from a partitioned table in a PostgreSQL database*/static Partition TrySubPartitionOidGetPartition(Relation rel, Oid subPartOid, LOCKMODE lockmode){Oid parentOid = partid_get_parentid(subPartOid);Assert(rel->rd_id == partid_get_parentid(parentOid));//It retrieves the parent partition OID of the given sub-partition OID using the partid_get_parentid function.//And it asserts that the relation’s OID is equal to the parent partition’s OID.Partition part = tryPartitionOpen(rel, parentOid, lockmode);//It try to open the parent partition with the given lock mode using the tryPartitionOpen function.if (part == NULL) {return NULL;}Relation partRel = partitionGetRelation(rel, part);//If the parent partition is successfully opened, it gets the relation of the parent partition using the partitionGetRelation function.Partition subPart = tryPartitionOpen(partRel, subPartOid, lockmode);//The function then tries to open the sub-partition with the given lock mode.releaseDummyRelation(&partRel);//It free the dummy relation of the parent partition using releaseDummyRelation.partitionClose(rel, part, NoLock);//It closes the parent partition using partitionClose and returns the sub-partition.return subPart;}
并行扫描
摩尔定律的挑战:随着晶体管尺寸的缩小,增加单个处理器核心的性能变得越来越困难。如下图所示。
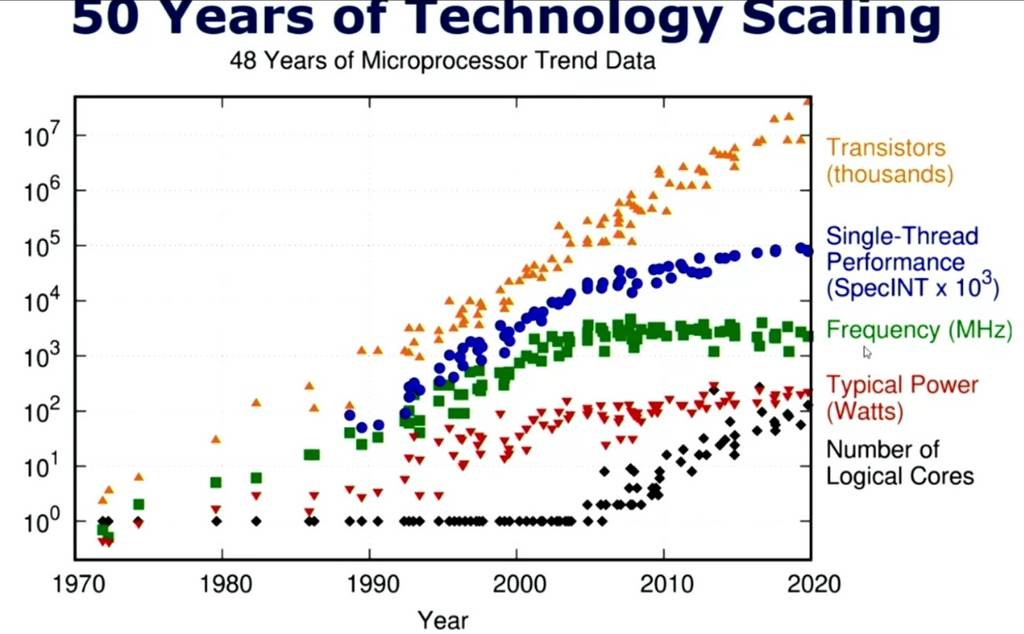
因此多核处理技术应运而生,而为了在数据库查询时释放多核的性能,并行扫描技术也随之诞生。
并行扫描是一种数据库查询优化技术,它允许多个进程同时扫描表的不同部分,以加快查询速度。在传统的单进程查询中,数据库需要按顺序扫描每一行数据来查找匹配的记录。然而,在并行扫描中,查询被分解成多个小任务,每个任务扫描表的一部分,这些任务可以在多个CPU核心上同时执行。
-
数据分割:首先,数据被分割成多个部分,每个部分可以单独处理。这些部分可以是数据库的表,文件的块,或者其他形式的数据集合。
-
任务分配:然后,每个数据部分被分配给一个处理单元(如一个CPU核心)。这通常由一个调度程序或操作系统来完成。
-
并行处理:一旦任务被分配,每个处理单元开始独立地处理其分配的数据部分。这可能涉及到读取数据,执行计算,或者进行其他形式的处理。
-
结果合并:最后,所有处理单元的结果被收集和合并。这可能涉及到将结果写入一个共享的数据结构,或者进行其他形式的同步操作。
具体步骤如下图所示:
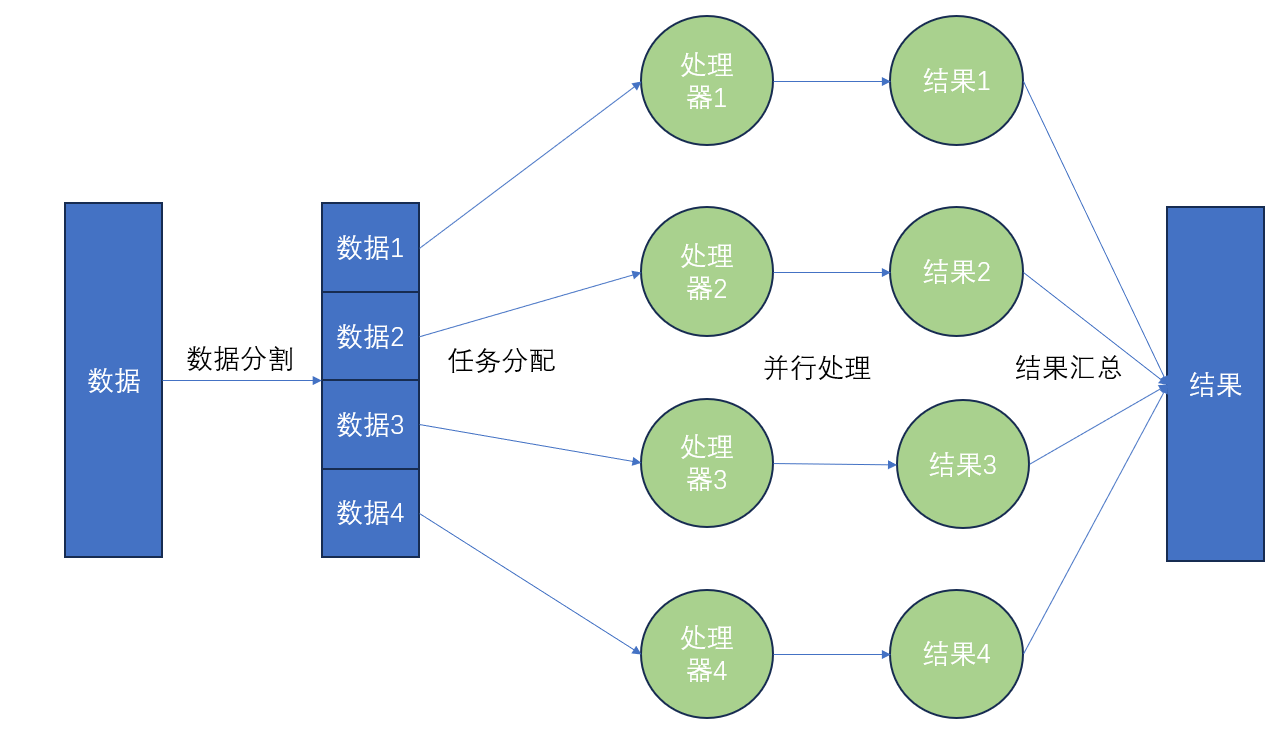
以下是并行扫描的一些关键特点和用途: 多核处理: 并行扫描充分利用了多核处理器的性能。不同的处理单元可以同时访问和处理数据块,加快查询的执行速度。
数据分割: 数据表通常被分割成多个数据块或分区。每个处理单元可以独立地扫描和处理一个数据块,减少了竞争和冲突。
查询分解: 查询被拆分成多个子查询,每个子查询由一个处理单元执行。这样可以提高并行性,加速查询。
聚合和排序: 并行扫描可用于同时执行聚合和排序操作。这对于处理大型数据集时特别有用。
硬件加速: 现代数据库系统通常支持硬件加速,如GPU,以进一步提高并行扫描的性能。
并行性控制: 数据库管理员可以配置并行扫描的程度,以避免过多的并行操作对系统性能造成不利影响 并行扫描的效果取决于许多因素,包括硬件性能(如CPU核心数和磁盘I/O速度)、查询的复杂性、表的大小和结构等。在理想情况下,如果有足够的硬件资源,并行扫描可以显著提高大型数据库查询的速度。
需要注意的是,并行扫描并不总是提高性能。例如,对于小表或者索引扫描,单进程扫描可能就足够快了。此外,并行处理也会增加系统的复杂性,并可能导致资源竞争。因此,在实际应用中,数据库系统通常会根据查询和系统状态动态决定是否使用并行扫描。换言之,并行扫描并不是完美无缺的,其相对于普通表的优缺点如下表所列:
| 优点 | 缺点 |
|---|---|
| 提高性能:并行扫描可以显著提高数据处理的速度,特别是在处理大量数据时。 | 编程复杂性:并行程序的设计和实现比串行程序更复杂。开发者需要处理数据依赖、同步、死锁等问题。 |
| 充分利用硬件:并行扫描可以充分利用多核处理器和多处理器系统的性能。 | 硬件需求:并行扫描需要多核或多处理器的硬件支持,这可能会增加硬件成本。 |
| 可扩展性:随着处理器核心数量的增加,并行扫描的性能可以线性增长。 | 负载均衡:在并行环境中,保持所有处理器核心的负载均衡是一个挑战。 |
if (RelationIsPartitioned(scan->rs_base.rs_rd)) {/* partition table just set Initial Value, in BitmapHeapTblNext will update */nblocks = InvalidBlockNumber;}
分区表
分区表是一种特殊的数据库表,它将数据分布在多个子表中,每个子表被称为一个分区。每个分区可以独立于其他分区进行管理和查询,从而提高查询性能和管理效率。分区表的主要优点是可以提高查询性能(特别是对大型表的查询),简化数据管理,并提高数据可用性。 在刚才的代码中,分区表出现在以下位置:
if (RelationIsPartitioned(scan->rs_base.rs_rd)) {/* partition table just set Initial Value, in BitmapHeapTblNext will update */nblocks = InvalidBlockNumber;}
它具有以下特点:
-
数据管理:通过将大表划分为较小的分区,你可以更容易地管理和查询你的数据。
-
性能提升:如果查询在分区列的值上使用了合格的过滤器,BigQuery可以扫描与过滤器匹配的分区,并跳过其余的分区。这个过程被称为修剪。
-
成本控制:通过减少查询读取的字节数,你可以提高查询性能并控制成本。
-
元数据:每个分区表都维护了关于所有修改操作的排序属性的各种元数据。元数据让BigQuery在运行查询之前更准确地估计查询成本。
-
备份和维护:可以更快地备份和维护一个或多个分区。
-
数据访问:可以更快、更有效地传输或访问数据子集,同时保持整个数据集合的完整性。
-
查询性能:可能会提高查询性能。
可以说分区表这样的数据库设计策略的出现,对本篇博客提到的并行查询实现起到了不可或缺的支撑作用。是数据库设计中的一种非常重要的组织数据的方式,可以在处理大规模数据时提供很多好处 OpenGauss的前身是PostgreSQL9.2.4,它在PG9版本使用继承式分区,并在,PG10版本新增了声明式分区,在PG11新增了哈希分区。
参考华为官网创建和管理分区表_云数据库 GaussDB_1.x版本_数据库使用_其他操作_华为云可知OpenGauss数据库支持的分区表类型为范围分区表。
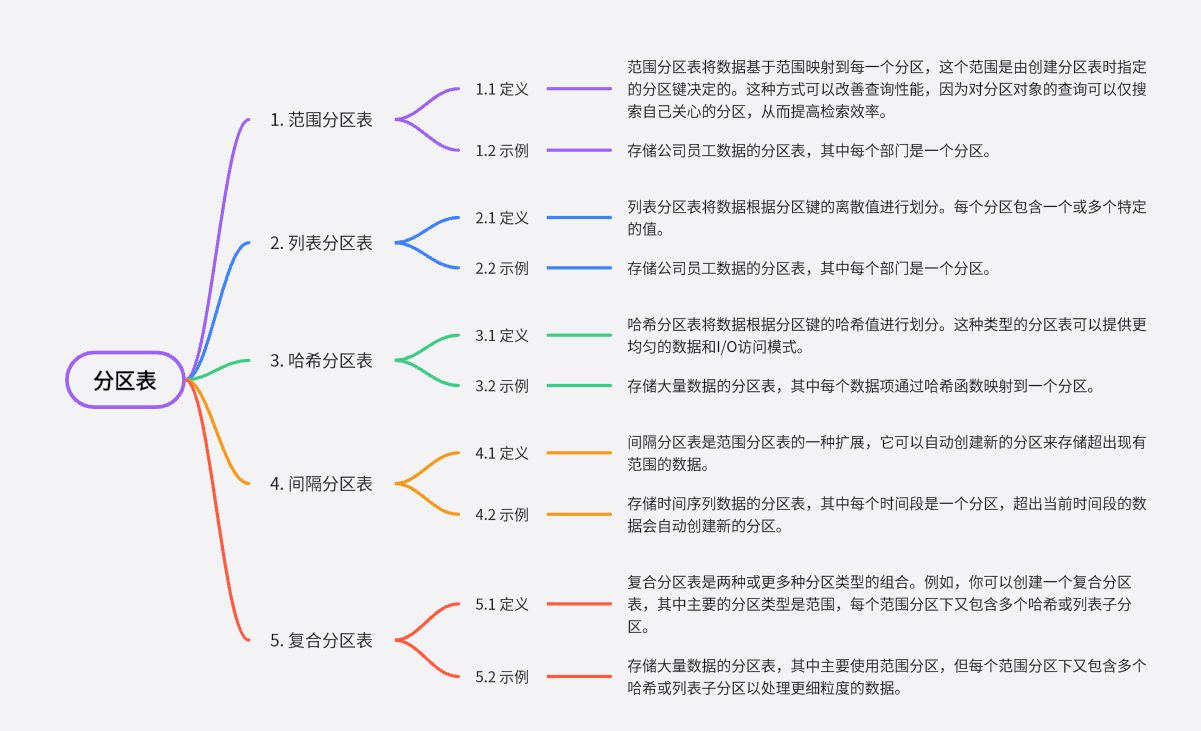
范围分区表将数据基于范围映射到每一个分区,这个范围是由创建分区表时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期,例如将销售数据按照月份进行分区。这种方式可以改善查询性能,因为对分区对象的查询可以仅搜索自己关心的分区,从而提高检索效率。
除了范围分区表,数据库中还有其他几种常见的分区表类型:
列表分区表:这种类型的分区表将数据根据分区键的离散值进行划分。每个分区包含一个或多个特定的值。例如,你可以创建一个列表分区表来存储一个公司的员工数据,其中每个分区对应一个部门。
哈希分区表:哈希分区表将数据根据分区键的哈希值进行划分。这种类型的分区表可以提供更均匀的数据和I/O访问模式。
间隔分区表:间隔分区表是范围分区表的一种扩展,它可以自动创建新的分区来存储超出现有范围的数据。
复合分区表:复合分区表是两种或更多种分区类型的组合。例如,你可以创建一个复合分区表,其中主要的分区类型是范围,每个范围分区下又包含多个哈希或列表子分区。















 2842
2842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









