






一.项目效果以及目的
实现如下图的手部识别即跟踪的效果,并且做成一个工具包,方便以后做其他项目时候直接使用其中的API
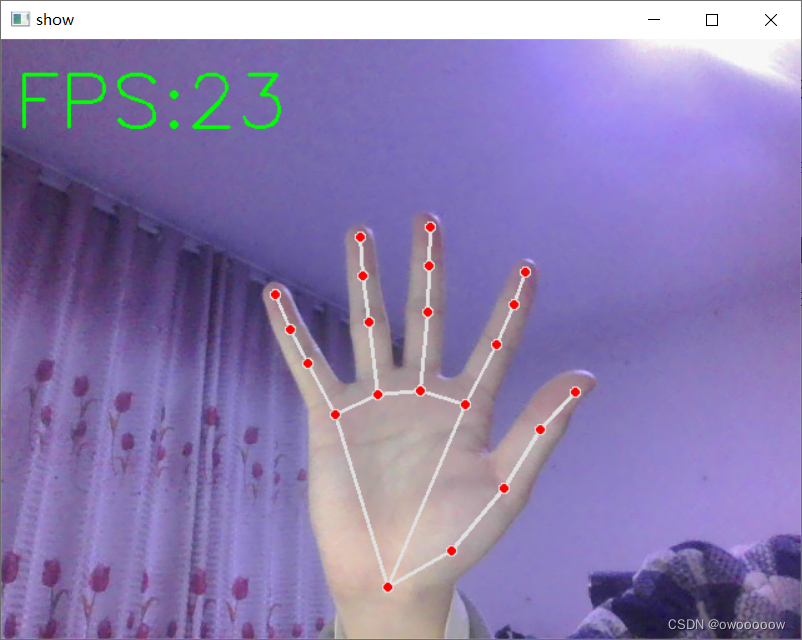
二.手部跟踪
1.所用到的包
使用pip install 或者在anaconda中下载即可
import cv2
import mediapipe as mp
import time
2.思路
用到opencv的地方不再多写,主要是记录mediapipe的用法
首先利用opencv调用电脑摄像头并且将其显示出来,再用mediapipe中的API进行手部识别与跟踪即可,具体用到的API如下
要进行手部跟踪,首先需要创建一个对象(如上文所示,吧mediapipe简称为mp,因此代码中的所有mp都是mediapipe)
mpHands = mp.solutions.hands
#四个参数,都有缺省值
#第一个参数为static_image_mode = False,当为True的时候一直是图像检测模式,
#当为False的时候,只在最开始的时候检测手部在哪里,之后只需要跟踪手部即可,当跟踪的过程中发现这个东西为手部的置信度小于某一个值的时候
#就会重新检测手部在哪里,继续跟踪.设置为False是比较节省资源的,因此使用它的缺省参数即可
#第二个参数为max_num_hands = 2,为能同时检测的手部的最大值,这里我们也用2即可
#第三个和第四个参数为置信度阈值,默认为0.5
hands = mpHands.Hands()
如注释所示,在老版本中,Hands()有四个参数,但是新版本增加到了五个,如下图所示:
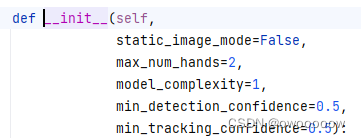
大概的工作流程就是,先检测手在哪里,并且检测到手的数量不能超过传入的参数max_num_hands设置的数量.然后如果第一个参数为False,就会进入跟踪模式,在此期间如果跟踪的东西为手的置信度小于传入的第四个和第五个参数的值,就会重新检测手在哪里,否则就一直跟踪.这种方法比较节省资源.如果第一个参数设置为True,就会每一帧每一帧一直检测手在哪里,会浪费资源并且速度变慢
results = hands.process(imgRGB)其中imgRGB是要进行处理的图片,它的通道格式移动式RGB的,但是opencv获取的图像默认是BGR的,因此还需要调用opencv的方法将其转换成RGB
results作为process方法的返回值,它有三个参数,都是列表的形式,记录手中21个关键节点的坐标的,其形式都差不多,用哪个都大致相同,这里利用的是multi_hand_landmarks
print(results.multi_hand_landmarks)如图,如果检测到手,就会显示其坐标,没有就会显示none,因此他还能当一个bool值来判断图像中有没有手
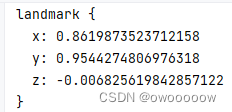
它的shape实际是一个列表套一个字典,最外面那一层[]里面存放的是一个手,因为一个屏幕中可能会出现多只手.在[]内部存21个关键点的坐标,{}里面存放的每一个点的具体坐标,
因此,首先用一层for循环遍历results.multi_hand_landmarks里面的所有手,再分别对每只手进行绘制或者获取坐标的操作
if results.multi_hand_landmarks:
#实际上muliti_hand_landmars返回的是一个列表,有多只手的信息,因此要写进for循环里绘制每一只手
for handLms in results.multi_hand_landmarks:
#要在原图BGR中绘制,因为opencv最终显示的是原图,加入第三个参数会连线,不加只会显示点
pass
有了21个点的坐标,可以用opencv绘制每个点,并且将点之间连线,但是太麻烦了,因此mediapipe直接给出了绘制手部21个关键点和连线的方法,首先还是创建一个对象
mpDraw = mp.solutions.drawing_utils再调用这个独享的draw_landmarks方法即可,其中handLms是上面for循环中写的一个变量,而mpHands.HAND_CONNECTIONS写上就会给点之间连线,不写就只会绘制21个点,其中mpHands是上文自己取得变量的名字
mpDraw.draw_landmarks(fream,handLms,mpHands.HAND_CONNECTIONS)这样就可以绘制出手部的关键点以及连线了,但是有时候还会用到手部某个关键点的坐标,因此还需要如下的知识:
handLms(自己定义的变量名)中还有一个参数,为landmark,是一个列表,列表中每一项又有两个参数,分别将其命名为id和lm,其中id为21个关键点的标号,从0到20,lm是该关键点的坐标
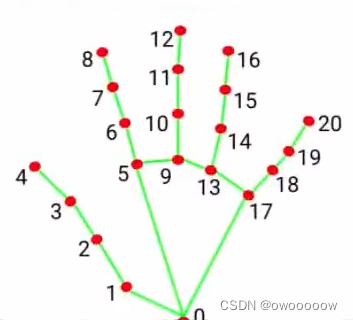
if results.multi_hand_landmarks:
#实际上muliti_hand_landmars返回的是一个列表,有多只手的信息,因此要写进for循环里绘制每一只手
for handLms in results.multi_hand_landmarks:
#分开打印每一个关节点的坐标
for id,lm in enumerate(handLms.landmark):
#两个参数分别是关节点在列表中的id和其坐标
print(id,lm)

可以看到,坐标都是归一化的,也就是0到1之间的,因此要获得真正的坐标,还得在此基础上乘上长或者宽即可
"""当检测到屏幕内有手的时候,绘制手部图像"""
if results.multi_hand_landmarks:
#实际上muliti_hand_landmars返回的是一个列表,有多只手的信息,因此要写进for循环里绘制每一只手
for handLms in results.multi_hand_landmarks:
#分开打印每一个关节点的坐标
for id,lm in enumerate(handLms.landmark):
#两个参数分别是关节点在列表中的id和其坐标
print(id,lm)
#返回的坐标都是0到1之间的,因此要过的真实的坐标,还需要乘以图片的长和宽
h,w,c = fream.shape
cx,cy = int(lm.x*w),int(lm.y*h)
#得到了cx和cy就可以单独对某一个关节点进行操作了
#要在原图BGR中绘制,因为opencv最终显示的是原图,加入第三个参数会连线,不加只会显示点
mpDraw.draw_landmarks(fream,handLms,mpHands.HAND_CONNECTIONS)
此外还希望计算视频的帧率,并且显示在屏幕上,帧率的计算方式如下:
3.完整代码:
import cv2
import mediapipe as mp
import time
"""创建mediapipe的首部检测对象"""
#mediapipe有两种检测模式,一种是hand,也就是21个关键节点的手部检测
mpHands = mp.solutions.hands
#四个参数,都有缺省值
#第一个参数为static_image_mode = False,当为True的时候一直是图像检测模式,
#当为False的时候,只在最开始的时候检测手部在哪里,之后只需要跟踪手部即可,当跟踪的过程中发现这个东西为手部的置信度小于某一个值的时候
#就会重新检测手部在哪里,继续跟踪.设置为False是比较节省资源的,因此使用它的缺省参数即可
#第二个参数为max_num_hands = 2,为能同时检测的手部的最大值,这里我们也用2即可
#第三个和第四个参数为置信度阈值,默认为0.5
hands = mpHands.Hands()
"""由于检测到的手部有21个点,用opencv画出来是十分复杂的,因此mediapipe给提供了现成的方法,和上面一样也是先创建对象"""
mpDraw = mp.solutions.drawing_utils
"""计算fps用到的参数"""
pTime = 0#上一次的时间
cTime = 0#当前时间 现在的的时间减去上一帧的时间是一帧所用的时间,再除以1就是fps
"""利用opencv调用摄像头"""
cap = cv2.VideoCapture(0)
while True:
ret,fream = cap.read()
"""mediapipe的Hands类只能处理RGB图像,因此先用openCV转换以下,再进行处理"""
imgRGB = cv2.cvtColor(fream,cv2.COLOR_BGR2RGB)
results = hands.process(imgRGB)
#这个方法,如果图片内检测到手,会返回True并却返回坐标,否则返回none
#print(results.multi_hand_landmarks)
"""当检测到屏幕内有手的时候,绘制手部图像"""
if results.multi_hand_landmarks:
#实际上muliti_hand_landmars返回的是一个列表,有多只手的信息,因此要写进for循环里绘制每一只手
for handLms in results.multi_hand_landmarks:
#分开打印每一个关节点的坐标
for id,lm in enumerate(handLms.landmark):
#两个参数分别是关节点在列表中的id和其坐标
print(id,lm)
#返回的坐标都是0到1之间的,因此要过的真实的坐标,还需要乘以图片的长和宽
h,w,c = fream.shape
cx,cy = int(lm.x*w),int(lm.y*h)
#得到了cx和cy就可以单独对某一个关节点进行操作了
#要在原图BGR中绘制,因为opencv最终显示的是原图,加入第三个参数会连线,不加只会显示点
mpDraw.draw_landmarks(fream,handLms,mpHands.HAND_CONNECTIONS)
"""计算fps"""
cTime = time.time()#当前时间
fps = 1/(cTime - pTime)
pTime = cTime
"""显示fps"""
cv2.putText(fream,"FPS:"+str(int(fps)),(10,70),cv2.FONT_HERSHEY_SIMPLEX,2,(0,255,0),2)
cv2.imshow("show",fream)
key = cv2.waitKey(1)
if key == 27:
break;
cap.release()
cv2.destroyAllWindows()
三.把上述代码改成一个工具包
需要改的地方不多,只不过把一些功能写到一个类里面,提供两个方法,一个是寻找手部的代码,另一个是查询坐标的代码,具体细节看注释即可
import cv2
import mediapipe as mp
import time
"""手部查找器"""
class handDetector():
"""五个参数分别为创建Hands所需要的五个参数,直接从Hands.py中复制过来即可,缺省值不用变"""
def __init__(self,static_image_mode = False,
max_num_hands = 2,
model_complexity = 1,
min_detection_confidence = 0.5,
min_tracking_confidence = 0.5):
self.mode = static_image_mode
self.max_num = max_num_hands
self.model_complexity = model_complexity
self.min_de = min_detection_confidence
self.min_track = min_tracking_confidence
self.mpHands = mp.solutions.hands
self.hands = self.mpHands.Hands(self.mode,self.max_num,self.model_complexity,self.min_de,self.min_track)
self.mpDraw = mp.solutions.drawing_utils
"""fream为原图,draw为True的时候绘制关键点和骨架,为False的时候不绘制"""
"""返回值是经过处理后的图像,实际上第二个参数为False的时候没有意义"""
def findHands(self,fream,draw = True):
imgRGB = cv2.cvtColor(fream, cv2.COLOR_BGR2RGB)
self.results = self.hands.process(imgRGB)
if self.results.multi_hand_landmarks:
for handLms in self.results.multi_hand_landmarks:
if draw:
self.mpDraw.draw_landmarks(fream, handLms, self.mpHands.HAND_CONNECTIONS)
return fream
"""fream为原图,handNo为需要返回第几个手的坐标,draw=True的时候,会给21个关键点标上更粗的紫色圆圈,draw没实际用处,因此默认为False"""
"""返回值为一个列表,存放的是这只手21个点的坐标,可以用索引分别查询每一个点的坐标"""
def findPositon(self,fream,handNo=0,draw=False):
lmList = []
if self.results.multi_hand_landmarks:
myHand = self.results.multi_hand_landmarks[handNo]
for id, lm in enumerate(myHand.landmark):
h, w, c = fream.shape
cx, cy = int(lm.x * w), int(lm.y * h)
lmList.append([id,cx,cy])
if(draw):
cv2.circle(fream,(cx,cy),15,(255,0,255),cv2.FILLED)
return lmList
"""main函数是为了测试上面的类能否正常使用的,在别的文件内导包直接调用上面类的函数即可"""
def main():
pTime = 0
cTime = 0
cap = cv2.VideoCapture(0)
detector = handDetector()
while True:
ret, fream = cap.read()
cTime = time.time() # 当前时间
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(fream, "FPS:" + str(int(fps)), (10, 70), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 255, 0), 2)
fream = detector.findHands(fream)
lmList = detector.findPositon(fream)
if len(lmList) !=0:
print(lmList[0])
cv2.imshow("show", fream)
key = cv2.waitKey(1)
if key == 27:
break;
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
在别的文件,直接import 这个python文件的文件名,比如我这里命名的是HandTrackingModule.py,就
import HandTrackingModule然后创建handDetector类,直接调用其中的函数就行了
detector = handDetector()
fream = detector.findHands(fream)
lmList = detector.findPositon(fream)


















 1819
1819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











