








亚马逊云科技AWS官方生成式AI免费证书来了!内含免费AI基础课程!快速掌握AWS的前沿AI技术,后端开发程序员也可以速成AI专家,了解当下最🔥的AWS AI架构解决方案!
本证书内容包括AWS上的AI基础知识,以及当下最热门的AWS AI服务和大语言模型,以及云上的前沿AI系统架构设计。强推没有任何AWS和AI背景以及转码的小伙伴去学!
证书名字叫Introduction to Generative Artificial Intelligence,内含24节免费课程(你没听错,足足24节课,Udemy上不得要$20以上),通过10道测试题后拿Credly证书(5分钟就能拿到)。
小李哥同时准备了AWS全部考试题库和该证书题库,私聊小李哥获取
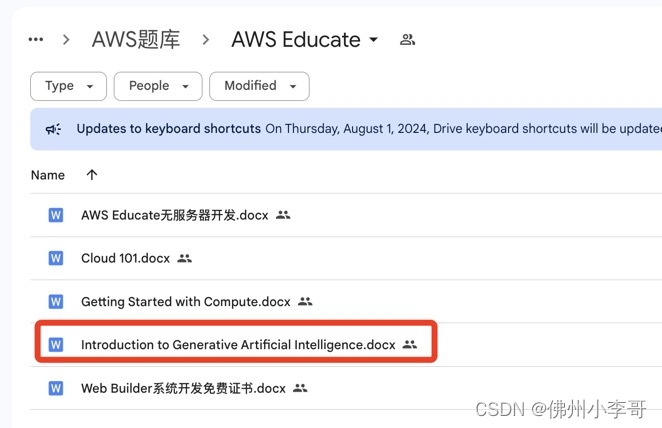
1️⃣ AI证书介绍
▶️ 首先介绍AWS Educate平台(免费教育计划)

这个平台是面向在校学生、AWS初学者,帮助他们学习、精通AWS的免费项目。包括包括数百小时的课程+免费实验,实验为真实AWS环境,大家不需要自己付费创建AWS资源,良心推荐。除了这张开发者证书,还有其他12张关于serverless无服务器开发、Web系统开发、数据库、网络、机器学习、DevOps、安全、DeepRacer(AWS 无人驾驶服务)的免费证书可以拿,其他的认证小李哥之前文章也分享过答案!
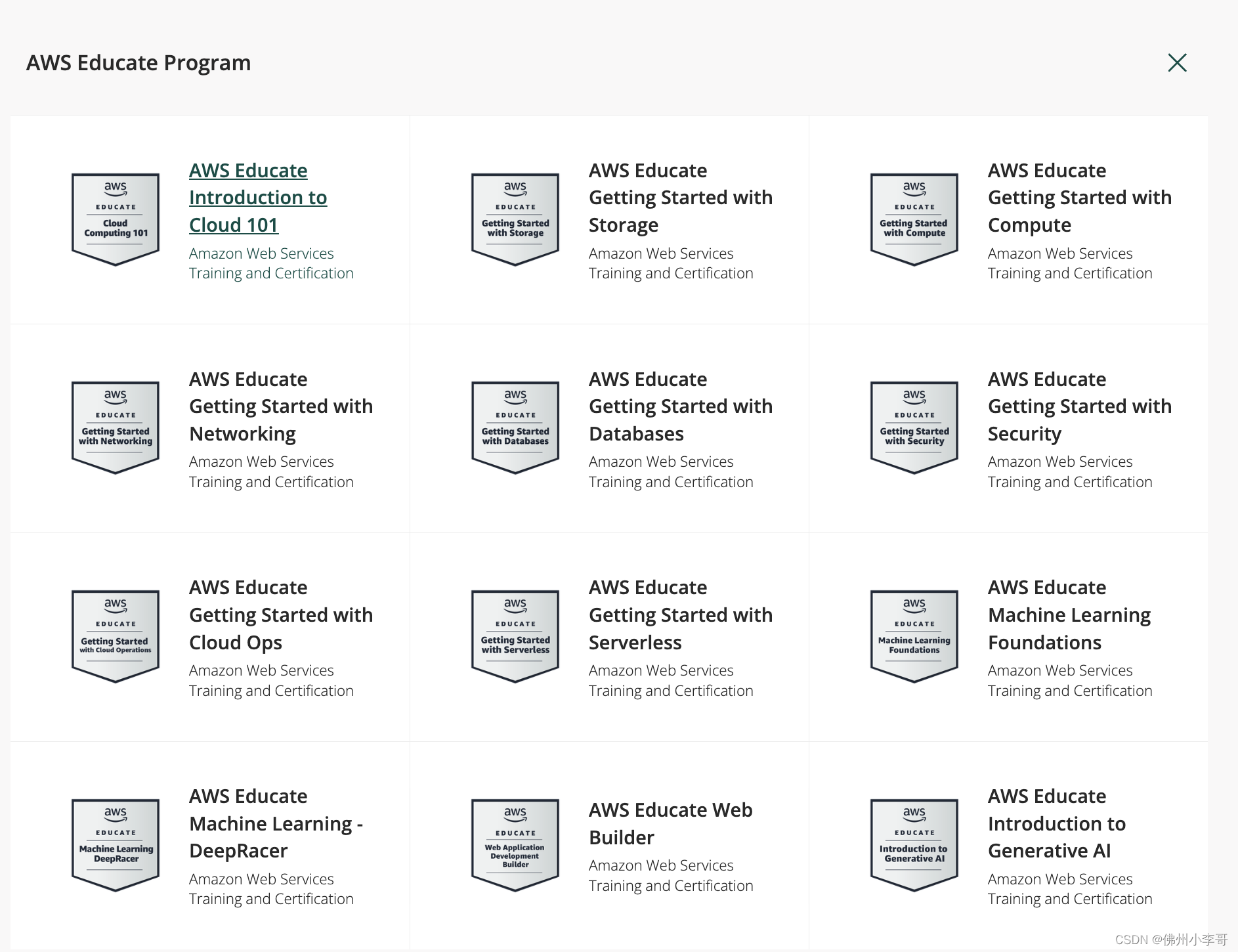
▶️这张证书的内容?
➡️ AI基础概念
➡️ 大语言模型原理和介绍当下热门大语言模型
➡️ 提示词工程
➡️ AI在不同行业的应用案例和架构设计方案
2️⃣ 我该如何拿到这张云从业者证书?
▶️ 从下图进课程
▶️ 进入下图登录界面,输入账号密码并登录
▶️ 点击下图左边栏的,点击红框进入课程
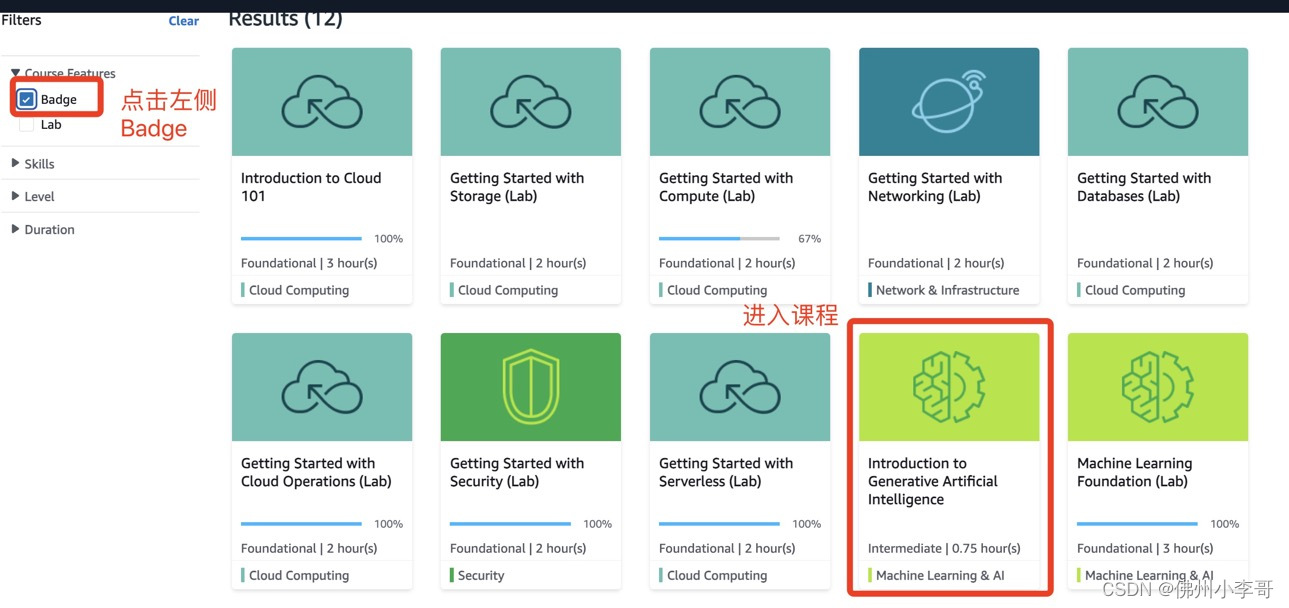
▶️ 点击下图的红框开始考证(可以不看,点Next直接跳过到最后的测试)
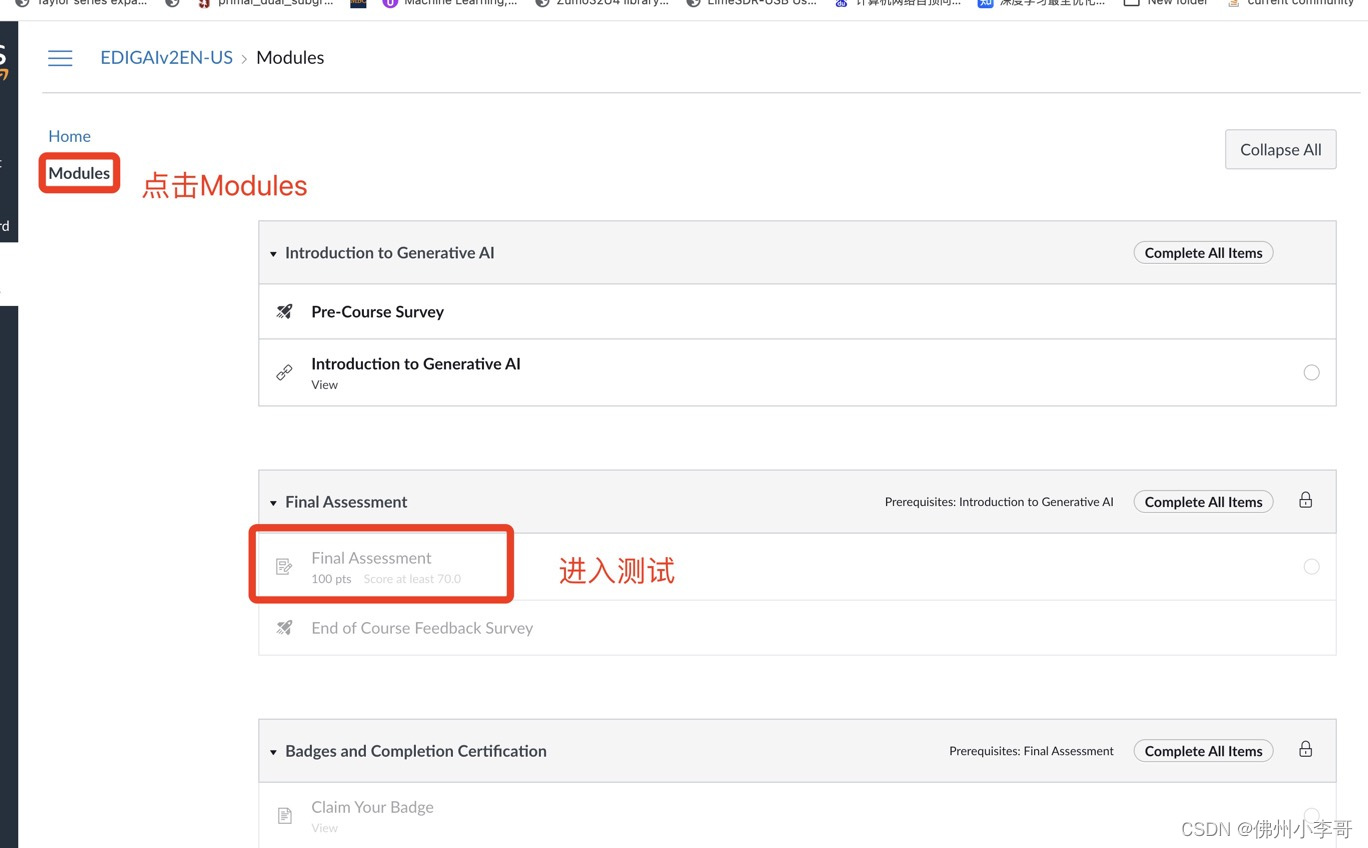
▶️ 考过最后下图中的Final Assessment(10道题,70%通过)就可以获得证书了

未来小李哥还会持续分享最前沿的亚马逊云科技及云计算技术学习、认证考试资源,欢迎持续大家关注!
4. 如何API调用亚马逊云科技上的AI/ML模型?
通过发送InvokeModel或InvokeModelWithResponseStream请求,通过 API 对模型进行推理和调用。大家可以在 contentType 和 accept 字段中为请求和响应正文指定媒体类型。如果您不指定值,这两个字段的默认值为 application/json。
除模型外 AI21 LabsJurassic-2,所有文本输出模型都支持流式传输。通过流式调用,可以更高效的获取模型的响应内容,降低延迟。
以下是Python调用Amazon Bedrock模型托管平台的代码:
普通调用代码:
import boto3
import json
brt = boto3.client(service_name='bedrock-runtime')
body = json.dumps({
"prompt": "\n\nHuman: explain black holes to 8th graders\n\nAssistant:",
"max_tokens_to_sample": 300,
"temperature": 0.1,
"top_p": 0.9,
})
modelId = 'anthropic.claude-v2'
accept = 'application/json'
contentType = 'application/json'
response = brt.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
# text
print(response_body.get('completion'))流式调用代码:
import boto3
import json
brt = boto3.client(service_name='bedrock-runtime')
body = json.dumps({
"prompt": "\n\nHuman: explain black holes to 8th graders\n\nAssistant:",
"max_tokens_to_sample": 300,
"temperature": 0.1,
"top_p": 0.9,
})
modelId = 'anthropic.claude-v2'
accept = 'application/json'
contentType = 'application/json'
response = brt.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
# text
print(response_body.get('completion'))在Aamzon Bedrock上调用最新的Anthropic大模型Claude 3.5:
import boto3
from botocore.exceptions import ClientError
MODEL_ID = "anthropic.claude-3-5-sonnet-20240620-v1:0"
IMAGE_NAME = "primary-energy-hydro.png"
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
with open(IMAGE_NAME, "rb") as f:
image = f.read()
user_message = "Which countries consume more than 1000 TWh from hydropower? Think step by step and look at all regions. Output in JSON."
messages = [
{
"role": "user",
"content": [
{"image": {"format": "png", "source": {"bytes": image}}},
{"text": user_message},
],
}
]
response = bedrock_runtime.converse(
modelId=MODEL_ID,
messages=messages,
)
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)简单场景例子:
# Use the native inference API to send a text message to Amazon Titan Text G1 - Express.
import boto3
import json
from botocore.exceptions import ClientError
# Create an Amazon Bedrock Runtime client in the AWS Region of your choice.
brt = boto3.client("bedrock-runtime", region_name="us-east-1")
# Set the model ID, e.g., Amazon Titan Text G1 - Express.
model_id = "amazon.titan-text-express-v1"
# Define the prompt for the model.
prompt = "Describe the purpose of a 'hello world' program in one line."
# Format the request payload using the model's native structure.
native_request = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512,
"temperature": 0.5,
"topP": 0.9
},
}
# Convert the native request to JSON.
request = json.dumps(native_request)
try:
# Invoke the model with the request.
response = brt.invoke_model(modelId=model_id, body=request)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)
# Decode the response body.
model_response = json.loads(response["body"].read())
# Extract and print the response text.
response_text = model_response["results"][0]["outputText"]
print(response_text)5. 如何获取Amazon Bedrock上的AI大模型信息
获取模型细节
def get_foundation_model(self, model_identifier):
"""
Get details about an Amazon Bedrock foundation model.
:return: The foundation model's details.
"""
try:
return self.bedrock_client.get_foundation_model(
modelIdentifier=model_identifier
)["modelDetails"]
except ClientError:
logger.error(
f"Couldn't get foundation models details for {model_identifier}"
)
raise
列出所有模型
def list_foundation_models(self):
"""
List the available Amazon Bedrock foundation models.
:return: The list of available bedrock foundation models.
"""
try:
response = self.bedrock_client.list_foundation_models()
models = response["modelSummaries"]
logger.info("Got %s foundation models.", len(models))
return models
except ClientError:
logger.error("Couldn't list foundation models.")
raise
在Bedrock上调用Meta Llama 3
import boto3
import json
# Set up the SageMaker client
session = boto3.Session()
sagemaker_client = session.client("sagemaker-runtime")
# Set the inference endpoint URL
endpoint_name = "<YOUR_ENDPOINT_NAME>"
def query_endpoint(payload):
client = boto3.client('runtime.sagemaker')
response = client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType='application/json',
Body=json.dumps(payload).encode('utf-8'),
)
response = response["Body"].read().decode("utf8")
response = json.loads(response)
return response
def print_completion(prompt: str, response: str) -> None:
bold, unbold = '\033[1m', '\033[0m'
print(f"{bold}> Input{unbold}\n{prompt}{bold}\n> Output{unbold}\n{response[0]['generated_text']}\n")
# Define the input prompt
prompt = """\
<s>[INST]
<<SYS>>You are an expert code assistant that can teach a junior developer how to code. Your language of choice is Python. Don't explain the code, just generate the code block itself. Always use Amazon SageMaker SDK for python code generation. Add test case to test the code<</SYS>>
Generate a Python code that defines and trains a Transformer model for text classification on movie dataset. The python code should use Amazon SageMaker's TensorFlow estimator and be ready for deployment on SageMaker.
[/INST]
"""
# Send the request to the endpoint and decode the response
payload = {"inputs": prompt,
"parameters": {"max_new_tokens": 2000, "temperature": 0.2, "top_p": 0.9},
}
response = query_endpoint(payload)
print_completion(prompt, response)输出内容:
[RESP]
import os
import json
import sagemaker
import boto3
import numpy as np
import pandas as pd
from sagemaker.tensorflow import TensorFlow
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_20newsgroups
# Set up SageMaker session
sagemaker_session = sagemaker.Session()
region = boto3.Session().region_name
bucket = sagemaker_session.default_bucket()
prefix = "sagemaker/DEMO-xSum"
# Download dataset
train = fetch_20newsgroups(subset="train")
test = fetch_20newsgroups(subset="test")
# Prepare dataset
train_data = pd.DataFrame(
{"text": train.data, "label": train.target.astype(np.int32)}
)
test_data = pd.DataFrame({"text": test.data, "label": test.target.astype(np.int32)})
# Split dataset
train_data, validation_data = train_test_split(train_data, test_size=0.2)
# Upload dataset to S3
train_input = sagemaker_session.upload_data(
path=train_data.to_csv(header=False, index=False),
bucket=bucket,
key_prefix=os.path.join(prefix, "train"),
)
validation_input = sagemaker_session.upload_data(
path=validation_data.to_csv(header=False, index=False),
bucket=bucket,
key_prefix=os.path.join(prefix, "validation"),
)
test_input = sagemaker_session.upload_data(
path=test_data.to_csv(header=False, index=False),
bucket=bucket,
key_prefix=os.path.join(prefix, "test"),
)
# Define hyperparameters
hyperparameters = {
"epochs": 1,
"batch_size": 64,
"max_seq_length": 256,
"model_dir": "/opt/ml/model",
"train_dir": "/opt/ml/input/data/train",
"validation_dir": "/opt/ml/input/data/validation",
"test_dir": "/opt/ml/input/data/test",
"train_filename": "train.csv",
"validation_filename": "validation.csv",
"test_filename": "test.csv",
"freeze_bert_layer": True,
"learning_rate": 0.0001,
"epsilon": 1e-08,
"bert_trainable_layers": None,
"bert_layer": -2,
"lambda_regularizer": 0.01,
"gradient_accumulation_steps": 2,
"steps_per_epoch": 100,
"validation_steps": 10,
"test_steps": 10,
"output_dir": "/opt/ml/output",
}
# Define estimator
estimator = TensorFlow(
entry_point="train.py",
source_dir="code",
role=sagemaker.get_execution_role(),
instance_count=1,
instance_type="ml.p3.2xlarge",
framework_version="2.4.1",
py_version="py37",
hyperparameters=hyperparameters,
)
# Train model
estimator.fit(
{
"train": train_input,
"validation": validation_input,
"test": test_input,
},
wait=True,
logs=True,
)
# Deploy model
predictor = estimator.deploy(
initial_instance_count=1, instance_type="ml.p3.2xlarge", wait=True
)
# Predict
predictor.predict(json.dumps({"instances": [test_data.iloc[0]["text"]]}))
<</RESP>>希望上述内容可以帮助大家在亚马逊云科技上调用AI构建软件应用,欢迎大家关注小李哥获取全球AI最新内容!















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









