







在本篇文章中,我会构建一个基于生成式AI的应用,让大家能利用生成式AI的能力和视频交互,并且几乎不需要编写任何代码。
在本篇文章中,我将展示如何构建一个简单的AI应用,它可以总结冗长的YouTube视频并使其可交互,同样的方式大家可以应用到B站视频等。海外的开发者经常观看YouTube视频,目的包括学习、娱乐和工作。因为是从事IT行业,开发者有时候没有时间看完整个视频,但又非常想了解视频中提到的关键内容,以便进一步深入研究自己感兴趣的部分。今天大家可以可以利用这个应用来实现这个需求。
例如在下图中,我就用了这个应用总结了Matt Wood(亚马逊云科技AI副总裁)在亚马逊洛杉矶峰会上的1.5小时主题演讲,AI总结并生成内容的整个过程不到一分钟。然后我们就可以围绕自己感兴趣的关键点向AI提问,并通过对话进行深入探讨。

架构设计方案
AI视频交互助手架构详解
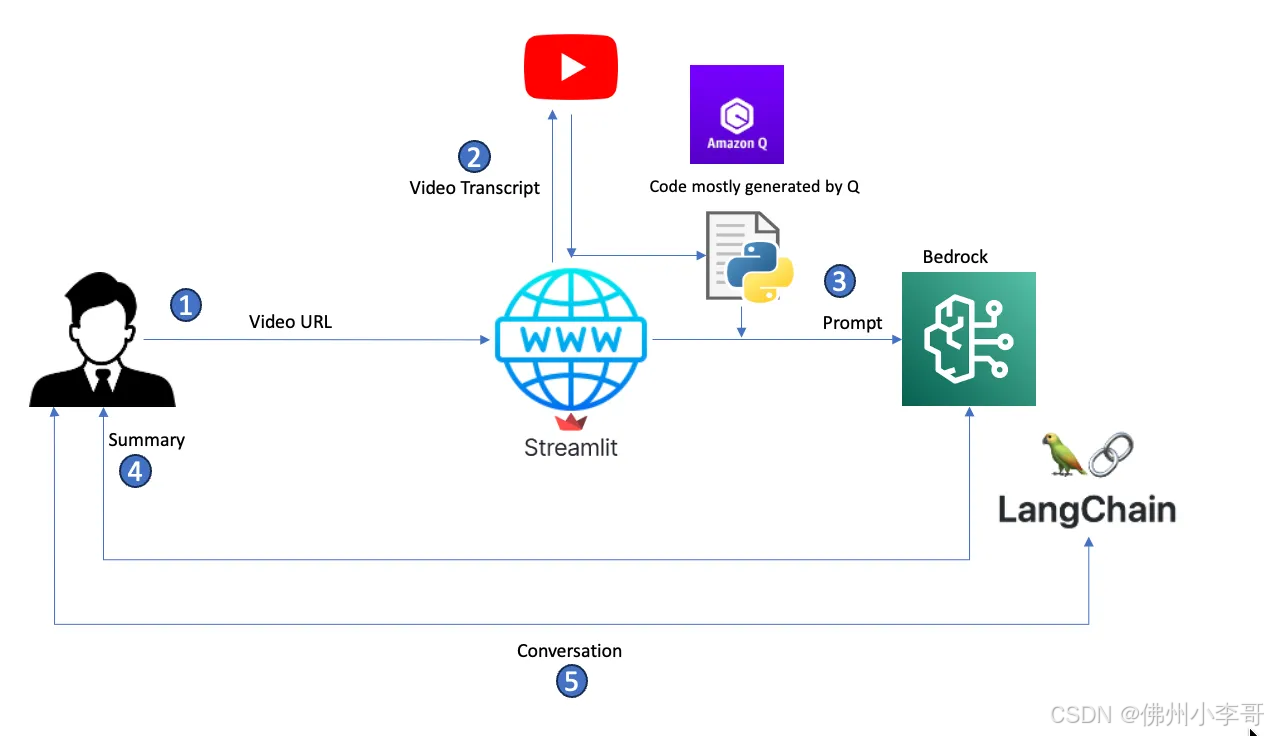
以下是整个云端解决方案的流程图
- 用户输入一个YouTube视频URL,让AI助手进行总结。
- Streamlit应用底层代码会提取URL,解析出视频ID,并调用YouTube API获取视频的转录文本。
- 应用从转录文本中构建一个提示词,并将其传递给Amazon Bedrock,使用预定义的模型进行内容总结。
- Bedrock根据提示词总结转录文本,并将响应回复返回给用户。
- 如果用户有后续问题,应用使用Langchain构建对话记忆,并基于原始转录内容回答用户的后续提问。
项目实操前提准备
如果大家对亚马逊云科技的生成式AI技术栈不熟悉,我建议先学习相关内容,然后再回来开始本项目的搭建。我们在动手之前,可以对以下组件进行了深入学习和了解,方便我们开始本篇文章中的项目。
- 在us-east-1区域设置Amazon Bedrock访问权限,并为Anthropic Claude 3模型启用访问权限。我选择这个AI大语言模型,因为它的最大Token数为200k,这让我能够在不增加我们的AI应用复杂度的情况下处理最长达3小时的视频转录文本。
- 在自己喜欢的代码IDE中安装Amazon Q Developer扩展。我使用的是Visual Studio Code。
- 熟悉Streamlit框架,以便部署AI Python应用——利用该框架的网页项目发布流程仅需一分钟。
代码组成部分
作为一名云端方案设计者,我认为理解各组件如何协同工作,以及了解模块修改对整体解决方案的影响是非常重要。我们应该对生成式AI应用的整体逻辑和架构有较好的理解,然而除了代码,我们还需要编写代码使其运行。因此在本方案中,我想利用AI代码生成助手Amazon Q,测试其如何帮助我最大程度地减少代码编写工作。通过多次迭代和参考大量现有示例,这个过程其实并不难。
代码主要由以下三个组件组成:
- bedrock.py:负责与LLM交互,创建Bedrock运行环境,进行内容总结,并利用LangChain管理聊天历史记录。
- utilities.py:负责获取视频转录文本,并基于转录内容构建提示词。
- app.py:主应用,负责与用户交互,包括接收视频URL、返回摘要、管理聊天会话等。
Bedrock模块详解
首先我向Amazon Q提出了这个问题:
write a python function that sets up a conversational AI system using the Amazon Bedrock service and the Claude language model (claude3). The AI can engage in a back-and-forth conversation with a user, maintaining context and providing relevant responses based on the prompt template and conversation history and then return the conversation with the user
它为我生成了示例代码,我只需进行少量调整,就能使其能够在Streamlit环境中运行。最终代码如下所示:
import boto3
from langchain.prompts import PromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_models import BedrockChat
import streamlit as st
from botocore.config import Config
retry_config = Config(
region_name = 'us-east-1',
retries = {
'max_attempts': 10,
'mode': 'standard'
}
)
def bedrock_chain():
ACCESS_KEY = st.secrets["ACCESS_KEY"]
SECRET_KEY = st.secrets["SECRET_KEY"]
session = boto3.Session(
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY
)
bedrock_runtime = session.client("bedrock-runtime", config=retry_config)
model_id = "anthropic.claude-3-sonnet-20240229-v1:0"
model_kwargs = {
"max_tokens": 2048, # Claude-3 use “max_tokens” However Claud-2 requires “max_tokens_to_sample”.
"temperature": 0.0,
"top_k": 250,
"top_p": 1,
"stop_sequences": ["\n\nHuman"],
}
model = BedrockChat(
client=bedrock_runtime,
model_id=model_id,
model_kwargs=model_kwargs,
)
prompt_template = """System: TThe following is a video transcript. I want you to provide a comprehensive summary of this text and then list the key points. The entire summary should be around 400 word.
Current conversation:
{history}
User: {input}
Bot:"""
prompt = PromptTemplate(
input_variables=["history", "input"], template=prompt_template
)
memory = ConversationBufferMemory(human_prefix="User", ai_prefix="Bot")
conversation = ConversationChain(
prompt=prompt,
llm=model,
verbose=True,
memory=memory,
)
return conversation
工具函数模块详解
我让Amazon Q为我构建了以下三个函数代码:
- 从YouTube URL获取视频ID
- 根据视频ID获取视频转录文本
- 从转录文本生成提示词
代码如下所示:
import logging
from youtube_transcript_api import YouTubeTranscriptApi
logger = logging.getLogger()
logger.setLevel("INFO")
def get_video_id_from_url(youtube_url):
logger.info("Inside get_video_id_from_url ..")
watch_param = 'watch?v='
video_id = youtube_url.split('/')[-1].strip()
if video_id == '':
video_id = youtube_url.split('/')[-2].strip()
if watch_param in video_id:
video_id = video_id[len(watch_param):]
logger.info("video_id")
logger.info(video_id)
return video_id
def get_transcript(video_id):
logger.info("Inside get_transcript ..")
transcript = YouTubeTranscriptApi.get_transcript(video_id)
logger.info("transcript")
logger.info(transcript)
return transcript
def generate_prompt_from_transcript(transcript):
logger.info("Inside generate_prompt_from_transcript ..")
prompt = "Summarize the following video:\n"
for trans in transcript:
prompt += " " + trans.get('text', '')
logger.info("prompt")
logger.info(prompt)
return promptStreamlit应用模块详解
app.py是Streamlit网页前端应用代码,它提供用户界面,让用户可以输入视频URL进行摘要,并与视频内容进行对话。
在这个文件中,大部分代码涉及用户会话管理、UI设计以及如何呈现应用的交互逻辑。其中最核心的函数是handle_input(),它负责检测用户输入(是摘要请求还是后续提问)、返回对应的摘要或聊天回复,并相应地重置用户状态。
import logging
from youtube_transcript_api import YouTubeTranscriptApi
logger = logging.getLogger()
logger.setLevel("INFO")
def get_video_id_from_url(youtube_url):
logger.info("Inside get_video_id_from_url ..")
watch_param = 'watch?v='
video_id = youtube_url.split('/')[-1].strip()
if video_id == '':
video_id = youtube_url.split('/')[-2].strip()
if watch_param in video_id:
video_id = video_id[len(watch_param):]
logger.info("video_id")
logger.info(video_id)
return video_id
def get_transcript(video_id):
logger.info("Inside get_transcript ..")
transcript = YouTubeTranscriptApi.get_transcript(video_id)
logger.info("transcript")
logger.info(transcript)
return transcript
def generate_prompt_from_transcript(transcript):
logger.info("Inside generate_prompt_from_transcript ..")
prompt = "Summarize the following video:\n"
for trans in transcript:
prompt += " " + trans.get('text', '')
logger.info("prompt")
logger.info(prompt)
return prompt部署
在完成代码开发完成后,我们通过Streamlit非常简单的就部署这个应用并让其他人可以使用。这一平台让构建和部署生成式AI应用变得异常简单。
结论
AI代码助手极大的提升了该项目的开发效率,整个过程花了我几周时间,每周抽出一两个小时来开发。但如果没有AI助手,这个过程肯定会耗费更长的时间。总体来说,完成这个项目的时间大约是5-6小时。
在这篇文章中,我展示了如何结合Amazon Q、Amazon Bedrock和Streamlit构建一个简单的应用,实现YouTube视频摘要和交互式对话。我还演示了如何利用生成式AI加速开发过程,并使用Amazon Q快速生成可用于POC(概念性验证)的代码。

















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









