






 本文介绍了如何通过Selenium模拟浏览器行为来应对网站的浏览器指纹识别反爬策略,包括直接从API获取数据和伪装webdriver的方法,重点讲解了JavaScript代码中的判断逻辑和如何使用ChromeOptions设置来突破反爬机制。
本文介绍了如何通过Selenium模拟浏览器行为来应对网站的浏览器指纹识别反爬策略,包括直接从API获取数据和伪装webdriver的方法,重点讲解了JavaScript代码中的判断逻辑和如何使用ChromeOptions设置来突破反爬机制。
目录
最后附上使用selenium破解目标网站浏览器指纹的完整代码:
概述
浏览器指纹是由浏览器类型、版本号、操作系统、屏幕分辨率、时区、插件、字体等信息组合而成的唯一标识,可以用于区分不同的用户。通过比对请求中的浏览器指纹与真实用户的指纹进行对比,可以识别出爬虫请求并进行相应的处理,例如拒绝访问、验证码验证等,以保护网站的正常运行和数据的安全。
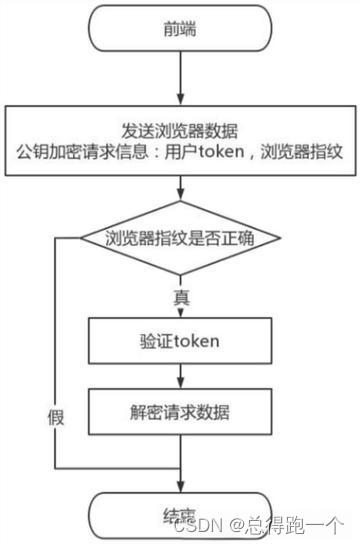
收集浏览器指纹
⬇️
分析浏览器指纹
⬇️
验证浏览器指纹
⬇️
判断处理
案例实操
目标
练习网页地址如下:
打开该页面,和上期出的时间戳反爬教程一样:页面上储存了由NordPass发布的2022年全球最常用密码列表,我们训练的目标是使用selenium的webdriver成功获取其中的数据。
分析
F12打开检查,选择sources,网站已经预先加载好了一些项目,我们打开JS,发现是没有JS混淆的。
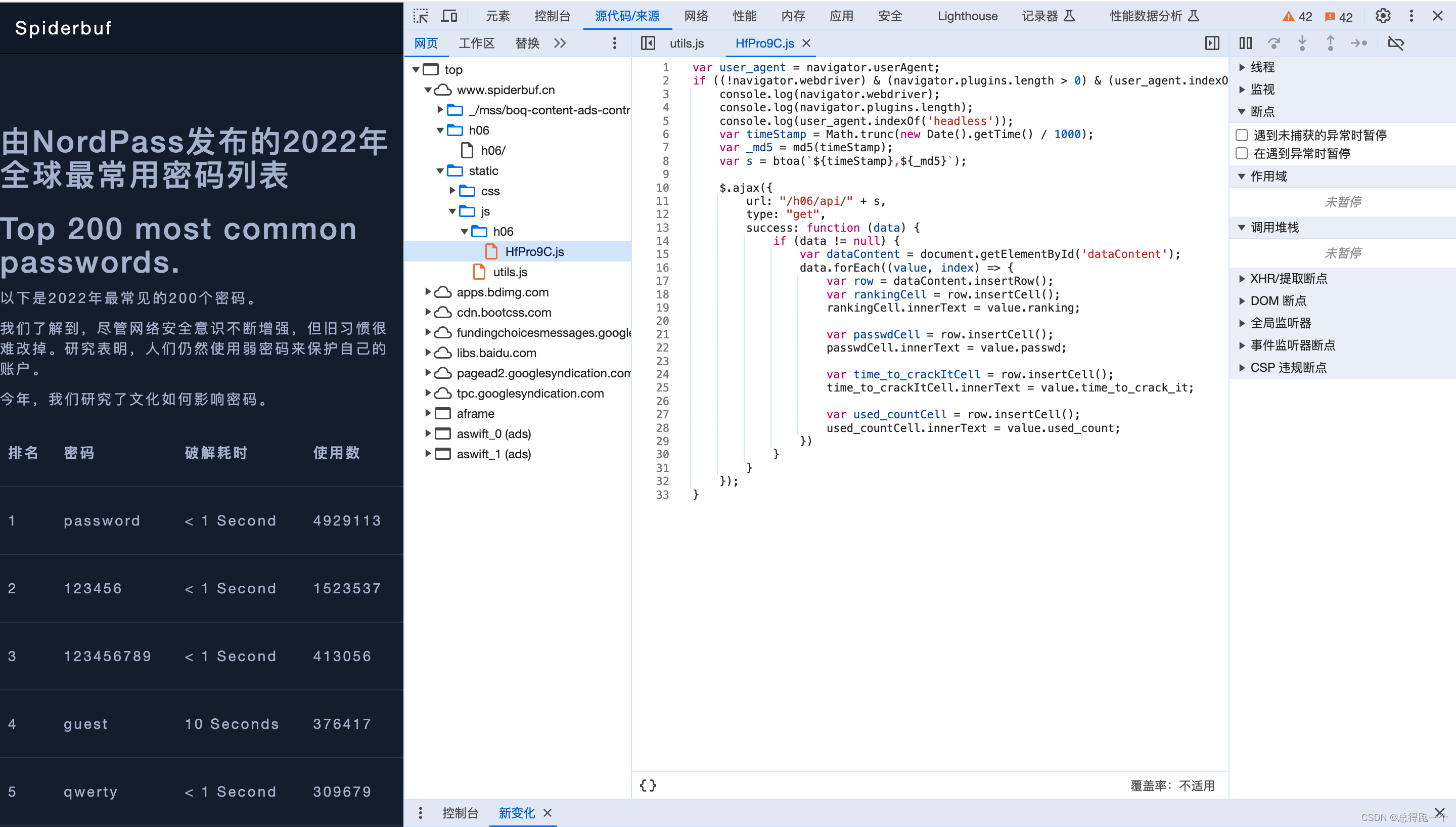
首先我们看一下第一句:
var user_agent = navigator.userAgent;
if ((!navigator.webdriver) & (navigator.plugins.length > 0) & (user_agent.indexOf('headless') < 0)) {
console.log(navigator.webdriver);
console.log(navigator.plugins.length);
console.log(user_agent.indexOf('headless'));
var timeStamp = Math.trunc(new Date().getTime() / 1000);
var _md5 = md5(timeStamp);
var s = btoa(`${timeStamp},${_md5}`);他是取浏览器的一个user agent放到一个变量里面,做了一个判断,包括webdriver以及plugin的长度,还有就是看一下user agent里面有没有headless这样的关键词,如果没有,他就打印一下日志,然后开始取时间戳,取到秒(JS默认取出来是到毫秒的)
补充
关于时间戳反爬,可以看我之前的博客:
第六行.getTime()/1000,即是做了一个取整操作,然后对取整后的时间戳使用MD5加密,再把时间戳和MD5用英文逗号隔开,拼接成一个字符串,放置在变量s里面。
$.ajax({
url: "/h06/api/" + s,
type: "get",
success: function (data) {
if (data != null) {
var dataContent = document.getElementById('dataContent');
data.forEach((value, index) => {
var row = dataContent.insertRow();
var rankingCell = row.insertCell();
rankingCell.innerText = value.ranking;
var passwdCell = row.insertCell();
passwdCell.innerText = value.passwd;
var time_to_crackItCell = row.insertCell();
time_to_crackItCell.innerText = value.time_to_crack_it;
var used_countCell = row.insertCell();
used_countCell.innerText = value.used_count;紧接着这里是用jquery的库,对这个H06进行一个请求操作,请求H06的api,方法是get,取戳来之后这个data如果不为空,那我们就开始按照ID来取这个网页的div,然后就开始遍历我们的JSON——一个一个地插入进页面。
开始
这样一来思路就很清晰了。
首先是相对固定的操作,导包,写一些基本信息:
# coding=utf-8
import base64
import hashlib
import time
import requests
base_url = 'http://www.spiderbuf.cn/h06'
myheaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'}
经过上文的分析我们可以知道几个关键点:取时间戳、加密、get请求。
由此可以得到方法一:直接从api拿数据
url = 'http://spiderbuf.cn/h06/api/'
timestamp = str(int(time.time()))
md5_hash = hashlib.md5()
md5_hash.update(timestamp.encode('utf-8'))
md5 = md5_hash.hexdigest()
s = ('%s,%s' % (timestamp, md5))
print(s)
payload = str(base64.b64encode(s.encode('utf-8')), 'utf-8')
print(payload)
html = requests.get(url + payload, headers=myheaders).text
print(html)
#将字符串转换为字典
dict_data = eval(html)
print(dict_data)
for item in dict_data:
print(item)
运行解析出来,发现全部都是我们需要的字符串。
方法二:伪装selenium.webdriver
测试
第一步同样,导包,写一些基本信息:
# coding=utf-8
import time
from lxml import etree
from selenium import webdriver
base_url = 'http://www.spiderbuf.cn/h06'
myheaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'}首先写一段最基础的获取html的代码,然后使用selenium测试一下是否能得到想要的数据:
def getHTML(url,file_name=''):
client = webdriver.Chrome()
client.get(url)
html = client.page_source
#print(html)
client.quit()
if file_name != '':
with open(file_name, 'w', encoding='utf-8') as f:
f.write(html)
return html运行,看到selenium打开一个浏览器,但是里面的数据是空的……
html = getHTML(base_url, './data/h06/h06.html')
print(html)看到它返回的HTML代码,下面的数据也是空的,也就是说,网站现在是检测到我们使用的是selenium,然后就被反爬了,不输出数据。
那么我们这时候就需要回头看一下,selenium是怎么被反爬的。
我们先写一个本地的测试用的HTML。
console.log(navigator.webdriver);
console.log(navigator.plugins.length);
console.log(user_agent.indexOf('headless'));看一下我们之前在这个网页检查sources中看的JS,测试一下这三句话究竟做了什么。
测试用HTML如下:
<html>
<head>
<title>test</title>
</head>
<body>
<h2>test for m0_66653437's blog</h2>
<script type="text/javascript">
console.log(navigator.webdriver);
console.log(navigator.plugins.length);
console.log(user_agent.indexOf('headless'));
</script>
</body>
</html>
我们看一下这里的判断究竟做了什么。
还是运行我们上文中的代码:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.set_capability('goog:loggingPrefs', {'browser': 'ALL'})
options.add_argument('--disable-blink-features=AutomationControlled')
client = webdriver.Chrome(options=options)
client.get('file:Users/dingyifan/Desktop/test.html')
print(client.page_source)
for i in client.get_log('browser'):
print(i['message'])
client.quit()
(笔者webdriver没更新懒得弄了,这里就先不展示输出界面,直接上结论)
爬取失败——分析与思考
运行发现,上述HTML中输出部分第一句,检测我们是否使用webdriver发起请求,再者便是检测plungin插件个数以及ChromeOption的属性。
上述代码中,如果去掉:
options.add_argument('--disable-blink-features=AutomationControlled')发现“console.log(navigator.webdriver);”输出的一个参数从False变成了True,这个值不一样了,这个值是干什么的?
这个值是检测现在的请求是不是用webdriver发起的,就是它会问你的浏览器,你是不是webdriver,他就老老实实回答:“我是!”
再者“console.log(navigator.plugins.length);”输出结果会是0,那么这样他就知道你使用的是webdriver了,你使用的是爬虫。
于是下面的这句话可以直接写死:
options.add_argument('--disable-blink-features=AutomationControlled')或者当ChromeOptions中出现“headless”关键词,也有可能被识别为爬虫:你都不打开我的页面,都不在看的,那你访问我的网址有集贸用?
改进
那么我们就把段代码加入到之前获取HTML的代码段中,看一下是否能返回我们需要的内容。
def getHTML(url,file_name=''):
client = webdriver.Chrome()
client.get(url)
html = client.page_source
print(html)
client.quit()
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.set_capability('goog:loggingPrefs', {'browser': 'ALL'}) # 输出浏览器console 日志:console.log
options.add_argument('--disable-blink-features=AutomationControlled') # 改变navigator.webdriver 属性值
client = webdriver.Chrome(options=options)
client.get(url)
print(client.page_source)
html = client.page_source
client.quit()
if file_name != '':
with open(file_name, 'w', encoding='utf-8') as f:
f.write(html)
return html运行:
html = getHTML(base_url, './data/h06/h06.html')
print(html)试一下,发现成功输出了我们想要的结果:
[{"ranking":1,"passwd":"password","time_to_crack_it":"\u003c 1 Second","used_count":4929113,"year":2022},{"ranking":2,"passwd":"123456","time_to_crack_it":"\u003c 1 Second","used_count":1523537,"year":2022},{"ranking":3,"passwd":"123456789","time_to_crack_it":"\u003c 1 Second","used_count":413056,"year":2022},
………………………………………………
最后附上使用selenium破解目标网站浏览器指纹的完整代码:
# coding=utf-8
from lxml import etree
from selenium import webdriver
base_url = 'http://www.spiderbuf.cn/h06'
myheaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'}
def getHTML(url,file_name=''):
client = webdriver.Chrome()
client.get(url)
html = client.page_source
print(html)
client.quit()
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.set_capability('goog:loggingPrefs', {'browser': 'ALL'}) # 输出浏览器console 日志:console.log
options.add_argument('--disable-blink-features=AutomationControlled') # 改变navigator.webdriver 属性值
client = webdriver.Chrome(options=options)
client.get(url)
print(client.page_source)
html = client.page_source
client.quit()
if file_name != '':
with open(file_name, 'w', encoding='utf-8') as f:
f.write(html)
return html
def parseHTML(html,file_name=''):
root = etree.HTML(html)
trs = root.xpath('//tr')
if file_name != '':
f = open(file_name, 'w', encoding='utf-8')
for tr in trs:
tds = tr.xpath('./td')
s = ''
for td in tds:
s = s + str(td.xpath('string(.)')) + '|'
# s = s + str(td.text) + '|'
print(s)
if (s != '') & (file_name != ''):
f.write(s + '\n')
f.close()
if __name__ == '__main__':
html = getHTML(base_url, './data/h06/h06.html')
print(html)
parseHTML(html, './data/h06/h06.txt')觉得有帮助的小伙伴还请点个关注
后续会持续分享 免费、高质量 的高校相关以及Python学习文章
(拒绝AI水文章)

















 4452
4452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









