






数据结构——查找篇
1.散列查找
基本介绍
描述
散列法又称为关键字—地址转化法
散列查找实际为一种以空间换时间的查找方式,当散列表中元素过多,装填因子过大的时候,就会导致查找效率大幅度下降;当散列表中元素较少的时候,查找效率则可以达到常数级别
概念
散列函数/哈希函数:
一个把关键字映射为该关键字对应的散列地址的函数,记为Hash(key)= Addr
这里的地址可以为数组下标、索引、或者内存地址等
构造函数的注意点:
1.定义域必须包含所有的关键词,值域取决于散列表的表长
2.不同的关键词计算出来的地址应该要等概率,较为均匀地分布在整个散列表中,以减少冲突的发生
3.函数应该尽可能简单,计算时间要短
散列表/哈希表:
根据关键字直接进行数据访问的数据结构,散列表建立了关键字和存储地址之间的一种映射关系(这种映射关系就是散列函数所描述的)
关键词key:
即为我们使用散列法存储在散列表中的目标数据
key可能并不是真正的用户需要查找的数据内容,而是一个守门人,找到了key,也就相当于找到了用户真正需要的数据,所以如何找到key才是关键(类比于我们使用搜索引擎搜索相关关键字,从而得到我们实际需要的数据的过程)
冲突:
如果多个key值代入散列函数/处理冲突的算法中,计算结果(即散列地址)相同,则称发生了冲突
通常key的值域远远大于表空间的地址集,所以冲突不可避免,但是要通过设计合理的散列函数把冲突出现的概率尽可能减低,或者通过一些方法来对已经发生的冲突状况进行合理解决
从数学的角度看,所谓冲突次数其实就是散列函数的“多对一”的映射的程度,最理想是全部为“一对一”,即完全不会发生冲突现象,但是这个是基本不可能实现的
同义词:
两个key,代入散列函数中,得到的散列地址完全相同(发生了冲突),则这两个key互为对方的同义词
装载因子/装入因子:
如果针对数组的存储形式,即为已经填入表中元素的个数除以散列表空间的大小
如果针对链表的存储形式(即使用了分离链接法),即为每一个链表的平均长度
散列表溢出:
如果使用了冲突的解决方法,依旧无法插入新元素,则称出现了散列表溢出的情况
懒惰删除:
散列表不会进行数据的完全删除,即一个key填入散列表的一个单元中,如果后续将这个key删除,则这个单元在删除key后所处状态和一个从来就没有元素填入的单元所处的状态,是不一样的,代码中通过单元的Info成员变量进行单元状态的区分
分离链:
为处理冲突的方法中的分离链接法中提及的概念,在同一个分离链中,各个结点的key都互为同义词,每一个分离链都是具有头结点的单链表,分离链中,结点的数据区域存放key,指针区域存放下一个结点的地址
平均查找次数:
“查找次数"指的是进行key值比较的次数,“平均"指的是每一项的查找次数之和,再除以项数
需要注意的是,无论是计算哪一种次数,都是要把确认"失败"或者"成功"的那一次计算在内,即计算公式中的那个”+1”
构造散列函数的方法
1.数字关键字的散列函数构造
-
直接定址法
- 散列函数为a x key + b(一个关于key的线性函数) -
除留余数法
- 散列函数为key%p
- 散列表长一般取关键词集合大小 / 允许的最大装填因子
- 一般p选取一个小于等于散列表长的素数,因为这样求得的散列地址比较均匀地分布在散列表中 的可能性会比较大,减少冲突发生 -
数字分析法
- 散列函数为把数字关键字中的某些随机性高的位上的数值提取出来,组合为一个数值,(还可以再进行除留余数法),得到散列地址
- 先对数字关键字的每一位的随机性进行评估,选取随机性高的几个位上的值,以此避免聚集效应
2.字符串关键字的散列函数构造
-
ASCII加和法
- 散列函数为把每一个字符对应的ASCII码相加,得到的结果再对散列表长进行取余 -
前三个字符移位法
- 散列函数为先把key中的前三个字符的ASCII码得到,然后把这三个整数分别当作27进制的各个位上的数值,不同的位乘以不同的权重,转化为一个十进制数值,再对散列表长进行取余 -
移位法(为前三个字符移位法的升级版,全部字符的ASCII码都参与计算)
- 散列函数为先把key中的全部字符的ASCII码得到,然后把所有的整数都分别当作32进制的各个位上的数值,不同的位乘以不同的权重,转化为一个十进制数值,再对散列表长进行取余
- 选取32进制的原因为,32=2^5,乘以32相当于对该十进制数值的二进制形式按位左移5位的得到的结果数值,方便C语言的代码实现
解决冲突的方法
1.开放地址法(开放地址法中的地址尝试都是循环式的)
-
线性探测法
- 每一次遇到冲突,都是尝试相邻的下一个地址
- 增量序列为1,2,3,…,散列表长-1
- 这种方式明显可以探查到整个散列表空间
- 可能会导致“一次聚集” -
平方探测法
- 遇到冲突,交叉尝试左右两边的地址
- 增量序列为12,-12,22,-22,32,…,q2,-q2(q<=散列表长开根号后向下取整的结果数值)
- 如果散列表长为某一个4*k+3的整数,则平方探测法可以探查到整个散列表空间
- 可能会导致“二次聚集” -
双散列探测法
- 遇到冲突,尝试的散列地址由另一个散列函数h2(key)计算得到
- 增量序列为h2(key),2*h2(key),3*h2(key)…
- h2(key)的值必须要保证不为0,否则会导致某一些key值一直无法插入散列表中
- 一个例子:h2(key)= p -(key % p),p为小于散列表表长的素数,也必须使用一个素数作为散列表表长,否则可能会导致探查不到整个散列表空间
- 使用双散列探测法会增加每次探测的计算量,但是相对于平方探测法,可以减少探测次数 -
再散列探测法
- 装填因子过大的时候,就进行散列表的加倍扩大,提高查找速度,但是将原表中的数据重新分配到新表中,这个搬运的过程会花费较多的时间(在交互系统中会让人感觉有"停顿",在一些对时延要求较低的系统中必须要谨慎使用该方法)
2.分离链接法
几个特点:
1.链式存储
不再使用顺序存储的方式进行key的存储,转而使用链式存储,同义词都以链表结点的形式存放在同一个分离链(一个具有头节点的单链表)中,以此来解决冲突问题
2.分离链的头节点
在线性表那篇中,我们发现如果带一个头节点,那么插入和删除的代码实现都会简洁很多,于是我们选择每一个分离链都带有一个头节点,而且把头节点全部放入一个结构体数组,进行统一管理
3.新key的存储
为了写代码的方便,也考虑到新的key被访问到的概率相对于之前存放的key较大,于是我们决定插入携带新的key的结点的时候,一律在分离链的头节点的后一个位置进行插入,这样可以提高访问效率
小贴士
散列法的两个基本内容?
1.构造散列函数的方法
2.解决冲突的方法
散列表的运作过程解析
1.关键字key的存储
通过构造一个散列函数,把要存储的key代入,计算出一个数值,这个数值可能就是目标存储单元的地址(“可能”表示如果发生了冲突,要使用处理冲突的算法不断尝试,换一个新地址进行数据存储)
2.关键字key的查找
依据给定的key,代入散列函数中,得到一个数值,这个数值可能就是目标存储单元的地址,在计算出地址以后,还要进行对应单元状态的查看和key的比对,查看是否为所要寻找的key
在查找过程中,会出现这些情况:
(1)如果单元状态为Empty(说明目标key未存入)或者存储的key和所要查询的key一致(说明目标key在散列表中存在,或者已经被删除了),返回这个地址,结束查找
(2)如果存储的数据内容和所要查询的数据内容不一致,说明当时存储这个目标key的时候,可能使用了处理冲突的算法把这个key存入了一个新地址中,所以此时也同样要运行相同的算法,继续尝试可能的地址,继续进行key的比较,继续查找
从上面的讲解中,可以发现,其实在完成数据查找的时候,也就完成了要插入的位置的查找(可以类比于二叉搜索树的插入算法,有异曲同工之妙)
为什么需要进行懒惰删除?
首先明确一点,在查找key的时候必须使用和key插入时相同的计算方法去找到目标地址,才能把key找到。具体来说,如果在key插入时,使用了处理冲突的算法,根据处理冲突的算法的原理:发生冲突了,就会继续运行算法中的代码,直到找到一个单元状态为Empty的单元或者找到一个单元状态不是Empty,而存储的key就是要查找的key的单元才会结束查找,返回该单元地址
假设进行的不是懒惰删除(即进行key删除的时候,直接把单元状态设置为Empty),会导致我们在查找的时候,如果像存放目标key的时候一样,使用相同的处理冲突的算法去寻找目标key,在运行算法的过程中,尝试到了某一个地址,而这个单元在我们插入要查找的目标key之后,进行了该单元key的直接删除,即直接把单元状态设置为Empty,按照查找算法的原理,此时找到一个单元状态为Empty的单元,会直接退出循环,进行返回这个单元状态为Empty的单元,表示目标key在散列表中不存在,但是我们知道,实际上目标key的的确确是存在于这个散列表当中的,"进行了key的删除操作,直接把单元状态设置为Empty"这样的操作就造成了要查找的目标key在散列表中不存在的假象,这种现象我们称为发生了断链
平均查找次数的具体计算方法?
值得注意的一点是,如果发现地址对应的key并不是目标key,此时会启动处理冲突的算法,而不是结束函数,这是和以前的查找所不同的地方
1.开放地址表示法的成功查找的平均查找次数(即每一个元素的成功查找次数相加/元素个数)
因为计算的是“成功查找”,于是项数为哈希表中已存储的元素的个数(因为只有确实存储了这个key,才能够实现成功查找),对于每个元素的成功查找次数的计算,要考虑是否出现了冲突的情况,要考虑使用的是哪个处理冲突的方法,每一个元素的成功查找次数为 查找过程的冲突数+1(这个1是最后成功找到目标key的那一次查找)
2.开放地址表示法的失败查找的平均查找次数(即哈希表中所有可以被哈希函数计算出来对应地址的格子对应的失败查找次数相加/格子个数)
因为计算的是“失败查找”,而失败的原因在于查找的key不在哈希表中,项数为哈希表中所有可以被哈希函数计算出来对应地址的格子的个数,要考虑是否出现了冲突的情况,要考虑使用的是哪个处理冲突的方法,每一个格子对应的失败查找次数为 查找过程的冲突数+1(这个1是最后确认散列表中不存在目标key的那一次查找,即查找到状态为Empty的单元)
3.分离链接法的成功查找的平均查找次数(即每一个元素的成功查找次数相加/元素个数)
项数为哈希表中已存储的元素的个数,由于每一个分离链都是一个单向链表,只能从头节点开始向后进行查找,于是每一个元素的成功查找次数即为对应的结点在其分离链中的次序(头结点算第0个结点)
4.分离链接法的失败查找的平均查找次数(即把每一个分离链的长度相加,结果除以分离链的个数)
和开放地址表示法的失败查找的平均查找次数的计算差不多,上面的项数为哈希表中所有可以被哈希函数计算出来对应地址的格子数,这里的项数其实就是分离链的个数,每一项的失败查找的次数,这里就是每一个分离链的长度,于是计算公式为:把每一个分离链的长度相加,结果除以分离链的个数
代码实现
关键参数的宏定义及类型重命名
#define MaxTableSize 1000 //起一个散列表表长的限制作用,避免为了寻找大于用户输入数据的素数,而导致散列表占用空间过大,浪费资源
typedef int Key_Type; //表示key的类型为int类型
typedef int Index; //表示散列地址(实际就是一个数组下标)的类型为int类型
typedef enum Entry_Type //使用枚举类型的常量表示单元的状态
{
Legitimate, //表示已经有key存储在本单元中
Empty, //表示本单元无数据存储过
Delete //表示本单元的key已经被删除(懒惰删除,为了防止导致查找的时候出现断链)
}Entry_Type;
结构定义
typedef struct CNode //单元的定义
{
Key_Type Data;
Entry_Type Info;
}*Cell;
typedef struct HNode //散列表这个数据结构的定义
{
int TableSize;
Cell Table;
}*HashTable;
(1)返回第一个大于N的素数作为散列表的实际表长 的函数
int NextPrime(int N) //在p不能大于MaxTableSize的前提下,计算大于N的第一个素数p,作为散列表的实际表长进行返回
{
int i;
int p = (N % 2) ? N + 2 : N + 1; //从大于N的第一个奇数开始评估其是不是素数
while (p <= MaxTableSize) //当尝试的p值到达一定的大小,不再继续寻找素数,直接返回p
{
for (i = 2; i <= (int)sqrt(p); i++) //用来判断一个数是否为素数的代码
{
if (p % i == 0)
break; //如果可以被除自己和1以外的数整除(即不是素数),提前结束循环
}
if (i > (int)sqrt(p))
break; //如果是素数,打破while循环,直接返回该素数
else
p = p + 2; //如果不是素数,则尝试下一个奇数
}
return p;
}
(2)散列函数
Index Hash(Key_Type key, int TableSize) //散列函数,使用的是数字关键字的散列函数构造法中的除留余数法
{
return key % TableSize;
}
(3)初始化
HashTable Init_Table(int TableSize) //初始化一个散列表
{
int i;
HashTable table = (HashTable)malloc(sizeof(struct HNode));
table->TableSize = NextPrime(TableSize); //计算第一个大于用户输入的TableSize的素数作为散列表的实际表长,
//即用户传入的表长会小于等于实际创建的散列表表长
table->Table = (Cell)malloc(table->TableSize * sizeof(struct CNode));
for (i = 0; i < table->TableSize; i++)
table->Table[i].Info = Empty; //把散列表的每一个单元的状态设置为空状态
return table;
}
使用除余留数法进行哈希函数构造,使用开放地址法中的平方探测法解决冲突
(4)查找key
Index Find(HashTable table, Key_Type key, int* CNum) //实现查找key的位置,这里是使用平方探测法解决出现的冲突问题
{ //返回的地址有三种情况:1.如果目标key从未插入过,返回一个单元状态为空的散列地址
//2.如果目标key插入过,但是被删除了,返回这个单元的散列地址 3.如果目标key插入过,且未被删除,返回这个单元的散列地址
Index NewP, InitP; //NewP存储的是发生冲突以后,调整以后的散列地址;InitP存储的是把key代入散列函数中,得到的那个初始散列地址
NewP = InitP = Hash(key, table->TableSize); //计算出要查找的key的初始散列地址
while (table->Table[NewP].Info != Empty && table->Table[NewP].Data != key) //当散列地址对应单元的状态非空(即为存在,或者删除状态),并且单元存储的key不是目标key
{ //就认为遇到冲突,进入循环,使用平方探测法解决,不断调整散列地址,进行尝试
//整型指针CNum指向的int类型的变量用来存储发生冲突的数目
if (++(*CNum) % 2) //由于使用的是平方探测法,于是需要对冲突数目进行奇偶判断,再根据具体的冲突数进行相应的散列地址调整
{
NewP = InitP + (*CNum + 1) * (*CNum + 1) / 4;
if (NewP >= table->TableSize)
NewP = NewP % table->TableSize;
}
else
{
NewP = InitP - (*CNum) * (*CNum) / 4;
while (NewP < 0)
NewP = NewP + table->TableSize;
}
}
return NewP;
}
(5)插入key
bool Insert(HashTable table, Key_Type key, int* CNum) //实现key的插入
{
*CNum = 0; //每一次查找之前都要把冲突计数器置为0,重新开始新一轮的计数
Index p = Find(table, key, CNum);
if (table->Table[p].Info != Legitimate)
{ //当返回的散列地址对应情况为1,2时,我们进行key的插入
table->Table[p].Info = Legitimate;
table->Table[p].Data = key;
return true;
}
else //当返回的散列地址对应情况为3时,插入失败
return false;
}
使用除余留数法进行哈希函数构造,使用开放地址法中的线性探测法解决冲突
(4)查找key
Index Find(HashTable table, int key, int* CNum)
{
Index NewP, InitP;
InitP = NewP = Hash(key, table->TableSize);
while (table->Table[NewP].Data != key && table->Table[NewP].Info != Empty) //当散列地址对应单元的状态非空(即为存在,或者删除状态),并且单元存储的key不是目标key
{ 就认为遇到冲突,进入循环,使用线性探测法解决,不断调整散列地址,进行尝试
(*CNum)++;
NewP = InitP + (*CNum);
if (NewP >= table->TableSize)
NewP = NewP % table->TableSize;
}
return NewP;
}
(5)插入key
bool Insert(HashTable table, int key, int* CNum)
{
*CNum = 0;
Index p = Find(table, key, CNum);
if (table->Table[p].Info != Legitimate)
{
table->Table[p].Info = Legitimate;
table->Table[p].Data = key;
return true;
}
else
{
return false;
}
}
(6)打印散列表
void Print(HashTable table) //打印散列表,单元状态为Delete或者Empty的时候,打印NULL
{ //只有单元状态为Legitimate时,才会打印单元存储的key
int i;
for (i = 0; i < table->TableSize; i++)
{
printf("|------");
}
printf("|\n");
for (i = 0; i < table->TableSize; i++)
{
printf("| %4d ", i);
}
printf("|\n");
for (i = 0; i < table->TableSize; i++)
{
printf("|------");
}
printf("|\n");
for (i = 0; i < table->TableSize; i++)
{
if (table->Table[i].Info == Legitimate)
printf("| %4d ", table->Table[i].Data);
else
printf("| NULL ");
}
printf("|\n");
return;
}
主函数测试
#define maxop 20
int main()
{
srand((unsigned)time(NULL));
int i, op;
Key_Type key;
int Cnum = 0;
int* CNum = &Cnum;
bool flag;
HashTable table = Init_Table(25);
for (i = 0; i < maxop; i++)
{
op = rand() % 4;
key = rand() % 100;
switch (op)
{
case 0: {
printf("插入关键字 %d %d ", key, flag = Insert(table, key, CNum));
if (flag)
printf("冲突次数为%d", *CNum);
printf("\n");
break;
}
case 1: {
printf("插入关键字 %d %d ", key, flag = Insert(table, key, CNum));
if (flag)
printf("冲突次数为%d", *CNum);
printf("\n");
break;
}
case 2: {
printf("插入关键字 %d %d ", key, flag = Insert(table, key, CNum));
if (flag) //当插入失败的时候,不打印冲突数
printf("冲突次数为%d", *CNum);
printf("\n");
break;
}
case 3: {
printf("插入关键字 %d %d ", key, flag = Insert(table, key, CNum));
if (flag)
printf("冲突次数为%d", *CNum);
printf("\n");
break;
}
}
Print(table);
printf("\n");
}
return 0;
}
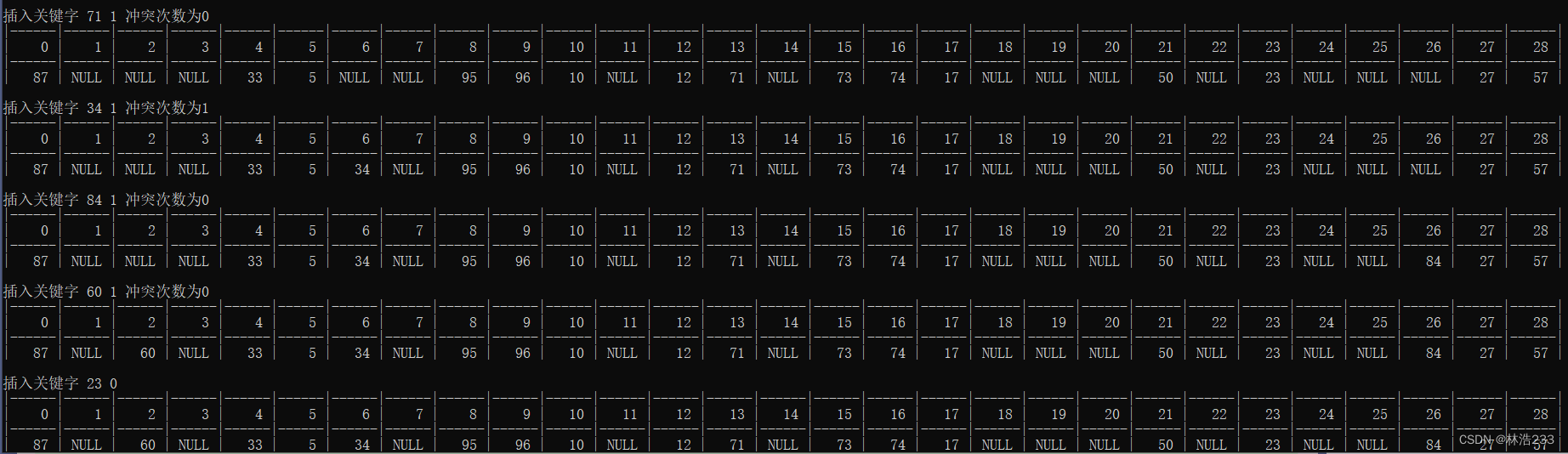
效果(除余留数法+平方探测法)
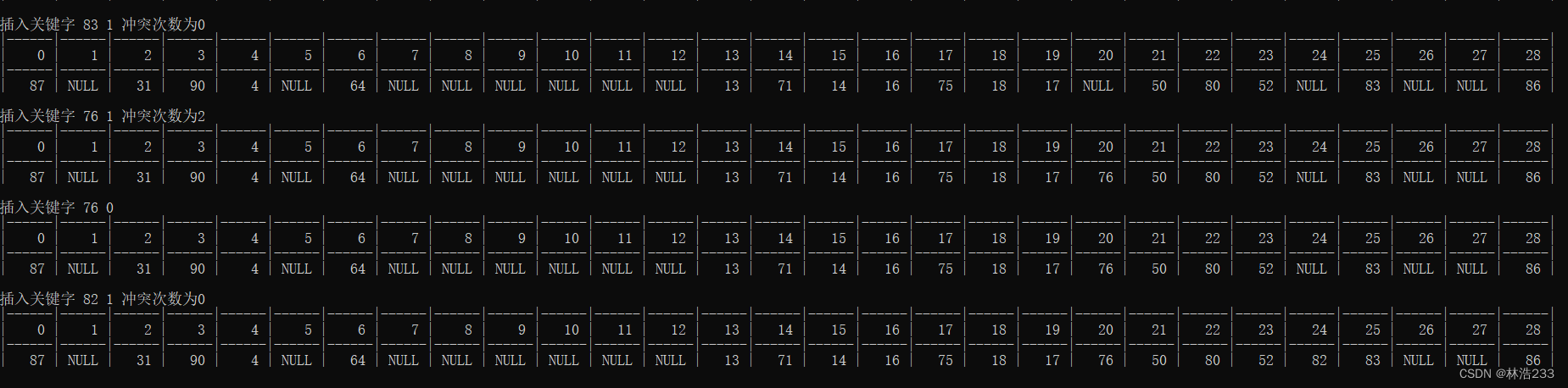
效果(除余留数法+线性探测法)
使用除余留数法进行哈希函数构造,使用分离链接法解决冲突
关键参数的宏定义及类型重命名
#define MaxTableSize 100
typedef int Key_Type; //表示key的类型为int类型
typedef int Index; //表示散列地址为int类型,实际就是数组下标
结构定义
typedef struct LNode //分离链结点的定义,分离链除头节点之外的结点才是用来存储key的
{
Key_Type Key;
struct LNode* Next;
}*PToLNode;
typedef PToLNode List; //表示List类型为指向结构体struct LNode的指针类型,下面的 散列表定义struct HashTable 中这个指针类型对应的变量就是指向真正的哈希表的指针
typedef struct HNode //散列表这个数据结构定义
{
int TableSize;
List Table;
}*HashTable; //表示HashTable类型为指向结构体struct HashTable的指针类型,以下所有的代码中,这个指针类型对应的变量就是指向哈希表这个数据结构的指针
(1)散列函数
Index Hash(Key_Type key, int TableSize) //散列函数,使用的是数字关键字的散列函数构造法中的除留余数法
{
return key % TableSize;
}
(2)初始化
HashTable Init_Table(int TableSize) //初始化散列表
{
int i;
HashTable table = (HashTable)malloc(sizeof(struct HNode));
table->TableSize = NextPrime(TableSize); //计算第一个大于用户输入的TableSize的素数作为散列表的实际表长
table->Table = (List)malloc(table->TableSize * sizeof(struct LNode));
for (i = 0; i < table->TableSize; i++)
table->Table[i].Next = NULL; //把各个分离链的头节点的指针区域全部初始化为NULL,此时散列表中没有插入key
return table;
}
(3)查找key
PToLNode Find(HashTable table, Key_Type key) //查找key,返回所在单元的内存地址
{
PToLNode pos = NULL;
Index p = Hash(key, table->TableSize); //代入key,得到初始散列地址,大致定位目标key的位置
pos = table->Table[p].Next; //指针pos指向初始散列地址对应的分离链的真正的第一个结点
while (pos != NULL && pos->Key != key) //结束while循环的情况有两种:1.pos == NULL,即未找到key 2.pos->Key == key,即找到了目标key
pos = pos->Next;
return pos;
}
(4)插入key
bool Insert(HashTable table, Key_Type key)
{
PToLNode pos = Find(table, key); //调用Find函数查找目标key的地址,如果不存在,则返回NULL;如果存在,则返回对应结点的内存地址
Index p = Hash(key, table->TableSize); //代入key,得到初始散列地址
if (pos == NULL) //确定目标key是否存在
{
//下面四行代码用来把目标key的插入到初始散列地址对应的分离链的头结点的后面
PToLNode n = (PToLNode)malloc(sizeof(struct LNode));
n->Key = key;
n->Next = table->Table[p].Next;
table->Table[p].Next = n;
return true;
}
else
return false; //如果目标key存在,返回false表示无法插入
}
(5)打印散列表
void Print(HashTable table) //打印散列表
{
PToLNode pos = NULL;
Index p;
for (p = 0; p < table->TableSize; p++)
{
printf("分离链%2d头结点:", p);
pos = table->Table[p].Next;
while (pos != NULL)
{
printf("-> %2d", pos->Key);
pos = pos->Next;
}
printf("\n");
}
return;
}
主函数测试
#define maxop 20
int main()
{
srand((unsigned)time(NULL));
int i, op;
Key_Type key;
HashTable table = Init_Table(10);
for (i = 0; i < maxop; i++)
{
op = rand() % 4;
key = rand() % 100;
switch (op)
{
case 0: {
printf("插入关键字 %d %d ", key, Insert(table, key));
printf("\n");
break;
}
case 1: {
printf("插入关键字 %d %d ", key, Insert(table, key));
printf("\n");
break;
}
case 2: {
printf("插入关键字 %d %d ", key, Insert(table, key));
printf("\n");
break;
}
case 3: {
printf("插入关键字 %d %d ", key, Insert(table, key));
printf("\n");
break;
}
}
Print(table);
printf("\n");
}
return 0;
}
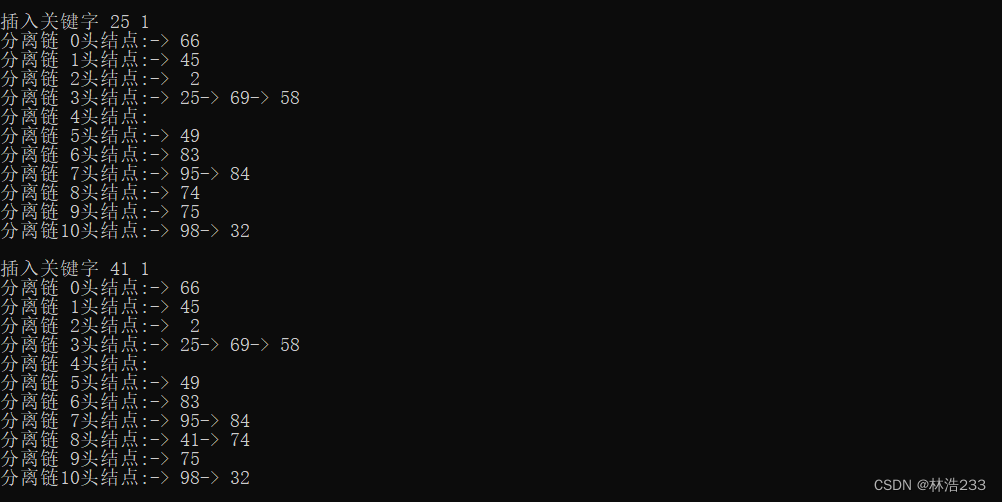
效果
来自作者的话:
此文章的内容还在逐步修进中,希望各位读者可以不吝赐教,有问题都可以在评论区提出来,我看到了会尽快进行更改
于 2022/12/5 第一次整改完毕















 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









