






摘要:通过自动编码实现的视觉标记化,将像素压缩到潜在空间,从而赋能了最先进的图像和视频生成模型。尽管基于Transformer的生成器的扩展一直是近期进展的核心,但标记器组件本身却很少被扩展,这使得自动编码器设计选择如何影响其重建目标和下游生成性能的问题仍然悬而未决。我们的工作旨在探索自动编码器的扩展,以填补这一空白。为了促进这一探索,我们用增强的视觉Transformer架构替换了典型的卷积主干网,用于标记化(ViTok)。我们在远超ImageNet-1K规模的大型图像和视频数据集上训练ViTok,消除了标记器扩展中的数据限制。我们首先研究了扩展自动编码器瓶颈如何影响重建和生成,并发现虽然它与重建高度相关,但与生成的关系则更为复杂。接下来,我们探索了分别扩展自动编码器的编码器和解码器对重建和生成性能的影响。关键的是,我们发现扩展编码器对重建或生成的提升微乎其微,而扩展解码器则能显著提升重建性能,但对生成性能的益处则喜忧参半。基于我们的探索,我们设计了ViTok作为一种轻量级自动编码器,在ImageNet-1K和COCO重建任务(256p和512p)上取得了与最先进的自动编码器相媲美的性能,同时在UCF-101的16帧128p视频重建任务上超越了现有自动编码器,且所有这些都以2-5倍更少的浮点运算数(FLOPs)实现。当与扩散Transformer集成时,ViTok在ImageNet-1K的图像生成任务上展现了具有竞争力的性能,并在UCF-101的类条件视频生成任务上设立了新的最先进基准。
Huggingface链接:Paper page ,论文链接:2501.09755
1. 引言
- 视觉标记化与生成模型:视觉标记化通过自动编码将像素压缩到潜在空间,从而赋能了最先进的图像和视频生成模型。这一过程允许生成模型在潜在空间中进行采样和转换,然后解码回图像或视频域,大大提高了生成效率和质量。
- Transformer的扩展:尽管基于Transformer的生成器扩展一直是近期研究的核心,但标记器组件本身的扩展却相对被忽视。这引发了一个问题:自动编码器的设计选择如何影响其重建目标和下游生成性能?
- 研究目标:本文旨在探索自动编码器的扩展,以填补这一研究空白。通过引入增强的视觉Transformer架构(ViTok),并在大型图像和视频数据集上进行训练,本文研究了自动编码器瓶颈、编码器和解码器的扩展对重建和生成性能的影响。
2. 背景
2.1 连续视觉标记化
- 变分自编码器(VAE):VAE是一种框架,通过编码器将视觉输入编码为潜在代码,并通过解码器重建输入。其主要目标是最小化重建图像与原始图像之间的均方误差(L_REC),并通过KL散度正则化项(L_KL)将潜在分布正则化为单位高斯先验。
- 损失函数:为了改进视觉保真度,VAE损失函数中还加入了基于VGG特征的感知损失(L_LPIPS)和对抗性GAN损失(L_GAN)。
2.2 可扩展的自动编码框架
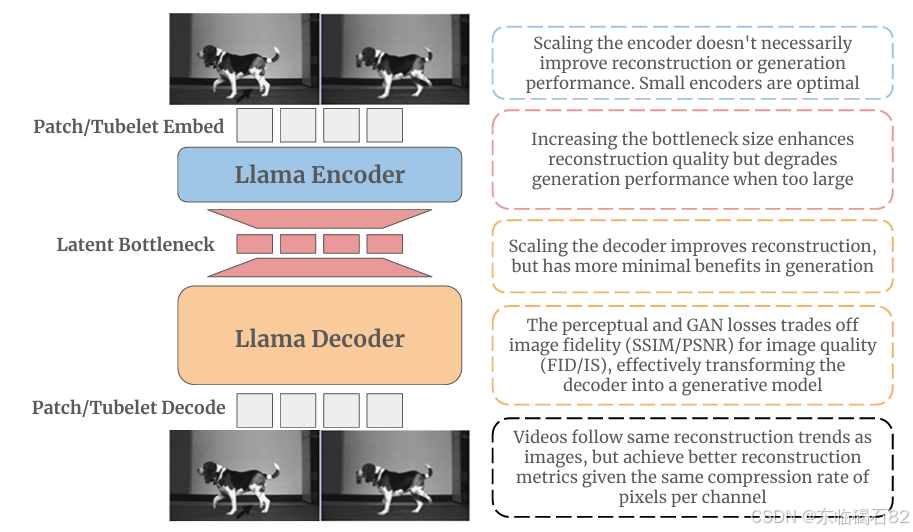
- ViTok架构:本文提出了ViTok,一种基于视觉Transformer(ViT)的自动编码器架构。它使用3D卷积将输入标记化为序列,然后通过ViT编码器和解码器处理这些序列,最后通过3D转置卷积恢复原始输入分辨率。
- 模型训练:为了稳定训练过程,本文采用了两阶段训练策略。第一阶段仅使用MSE、LPIPS和KL损失,确保自动编码器性能稳定。第二阶段引入对抗性损失,同时冻结编码器,仅微调解码器,以提高生成性能。
3. 模型与实验设置
3.1 ViTok模型
- 模型尺寸:ViTok提供了多种模型尺寸,包括小型(S)、基础(B)和大型(L)编码器和解码器配置。例如,ViTok S-B/4x16表示一个小型编码器、基础解码器,以及4x16的块/步长参数。
- 训练数据:为了消除数据限制,本文在大型图像(如Shutterstock图像数据集和ImageNet-1K)和视频(如Shutterstock视频数据集和UCF-101)数据集上训练ViTok。
3.2 实验设置
- 训练阶段:第一阶段训练运行100,000步,第二阶段微调再运行100,000步。使用AdamW优化器,并采用bfloat16自动转换以加速训练。
- 评估指标:重建质量通过Fréchet Inception Distance(FID)、Inception Score(IS)、Structural Similarity Index Measure(SSIM)和Peak Signal-to-Noise Ratio(PSNR)来评估。生成质量则通过gFID和gIS来评估。
4. 瓶颈、扩展与权衡
4.1 瓶颈尺寸对重建的影响
- 主要发现:实验表明,潜在代码中浮点数的总数(E)是重建性能的主要瓶颈。无论代码形状或浮点运算数(FLOPs)如何变化,E都与重建质量高度相关。
- 视觉质量:随着E的减小,高频细节逐渐丢失,当E小于4096时,显著的细节损失变得明显。
4.2 瓶颈尺寸对生成的影响
- 复杂关系:与重建不同,E与生成性能之间的关系更为复杂。每个块大小都有一个最优的E值,过高的E值会由于过大的通道尺寸(c)而降低生成性能。
- 配置优化:实验发现,通过调整E和c可以平衡重建和生成性能。例如,对于p=16的块大小,最优配置为c=16和E=4096。
4.3 编码器和解码器的扩展
- 编码器扩展:扩展编码器对重建或生成性能的提升微乎其微,甚至可能有害。增加编码器尺寸不仅增加了计算负担,还可能降低生成性能。
- 解码器扩展:扩展解码器能显著提升重建性能,但对生成性能的益处则不一而足。尽管增加解码器尺寸可以提高重建质量,但对生成性能的提升并不总是显著。
4.4 解码器作为生成模型的延伸
- 损失权衡:实验表明,增强FID/IS得分(衡量视觉质量)需要牺牲一些SSIM/PSNR(衡量视觉保真度)。这反映了解码器在生成内容方面的作用逐渐增强。
- 对抗性微调:通过对抗性微调解码器,可以进一步提高生成性能,但这通常以牺牲一些SSIM/PSNR为代价。
5. 视频结果
5.1 视频重建
- 类似趋势:视频重建表现出与图像重建相似的瓶颈特性。然而,由于视频数据的内在冗余性,E可以更有效地扩展,以实现与图像相当的重建质量。
- 帧计数:增加视频帧数可以提高重建指标,表明更长的视频在相对压缩比方面更具可压缩性。
5.2 视频生成
- 新基准:在UCF-101数据集上,ViTok与扩散Transformer(DiT)结合,在类条件视频生成任务上设立了新的最先进基准。
- 高效压缩:ViTok通过有效利用视频数据的冗余性,实现了高效的压缩和生成性能。
6. 实验比较
6.1 图像重建与生成
- 重建性能:在ImageNet-1K和COCO数据集上,ViTok在256p和512p分辨率下实现了与最先进的自动编码器相媲美的重建性能,同时显著减少了FLOPs。
- 生成性能:在图像生成任务上,ViTok与DiT结合,在ImageNet-1K数据集上展现了具有竞争力的性能。
6.2 视频重建与生成
- 重建基准:在UCF-101数据集上,ViTok在16帧128p视频重建任务上超越了现有方法,同时显著减少了FLOPs。
- 生成基准:在类条件视频生成任务上,ViTok与DiT结合,设立了新的最先进基准。
7. 相关工作
7.1 图像标记化
- 传统方法:传统方法主要基于卷积神经网络(CNN),如VQVAE和VQGAN。这些方法通过向量量化步骤在瓶颈中离散化潜在空间。
- Transformer方法:近年来,基于Transformer的方法逐渐兴起,如ViTVQGAN和TiTok。这些方法通过引入Transformer架构来提高标记化性能。
7.2 视频标记化
- 现有方法:现有视频标记化方法主要基于3D卷积和VQVAE,如TATS和Phenaki。这些方法通过复制填充和因式分解注意力来处理可变长度视频。
- 新方法:本文提出的ViTok通过引入连续潜在代码和增强的Vision Transformer架构,为视频标记化提供了新的思路。
7.3 高分辨率生成
- GAN与扩散模型:高分辨率图像生成通常通过GAN和扩散模型实现。近年来,扩散模型因其稳定性和生成质量而逐渐受到青睐。
- Transformer生成器:基于Transformer的生成器如MaskGIT和Diffusion Transformers在图像和视频生成任务上展现了强大的性能。
8. 结论
- 主要发现:本文通过扩展自动编码器瓶颈、编码器和解码器,深入研究了它们对重建和生成性能的影响。实验结果表明,扩展解码器能显著提升重建性能,但对生成性能的益处则因情况而异。
- ViTok设计:基于这些发现,本文设计了ViTok作为一种轻量级自动编码器,在图像和视频重建及生成任务上取得了与最先进方法相媲美的性能,同时显著减少了计算负担。
- 未来展望:本文的工作为视觉标记化和生成模型的研究提供了新的视角和思路。未来工作可以进一步探索更有效的Transformer架构和训练策略,以提高视觉生成模型的性能和效率。
本文通过系统的实验和深入的分析,揭示了自动编码器扩展对重建和生成性能的影响,并提出了ViTok作为一种高效、轻量级的视觉标记化方法。ViTok在图像和视频重建及生成任务上展现了强大的性能,为视觉生成模型的研究提供了新的思路和方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









