






摘要:图像生成领域已迅速演变,从早期的基于生成对抗网络(GAN)的方法,到扩散模型,再到最近旨在弥合理解与生成任务之间差距的统一生成架构。近期进展,尤其是GPT-4o,已展示了高保真度多模态生成的可行性,但其架构设计仍然神秘且未公开。这引发了一个问题:图像和文本生成是否已成功集成到这些方法的统一框架中。在本研究中,我们对GPT-4o的图像生成能力进行了实证研究,将其与领先的开源模型和商业模型进行了对比。我们的评估涵盖四个主要类别,包括文本到图像、图像到图像、图像到三维以及图像到任意模态(X)的生成,涉及20多项任务。我们的分析突显了GPT-4o在不同设置下的优势和局限性,并将其置于生成建模更广泛的演变背景中。通过这项研究,我们为未来的统一生成模型指明了有前景的方向,强调了架构设计和数据扩展的作用。Huggingface链接:Paper page,论文链接:2504.05979
研究背景和目的
研究背景
近年来,图像生成领域经历了从早期基于生成对抗网络(GAN)的方法,到扩散模型,再到统一生成架构的显著演变。这些进展不断推动着图像生成技术的边界,从生成图像的逼真度和多样性,到实现图像与文本等多模态数据之间的深度融合。然而,尽管现有方法已经取得了令人瞩目的成就,但图像和文本生成任务是否已成功集成到一个统一的框架中,仍然是一个悬而未决的问题。
特别是GPT-4o的发布,标志着多模态生成模型的一个重要里程碑。GPT-4o展示了在生成高保真度、逼真图像方面的强大能力,同时实现了视觉和语言生成的无缝统一。然而,GPT-4o的闭源性质,尤其是其架构设计、训练过程和推理机制的缺乏公开性,给科学界带来了挑战。因此,对GPT-4o的图像生成能力进行实证研究,以了解其在实际应用中的表现,显得尤为重要。
研究目的
本研究旨在通过实证研究,全面评估GPT-4o的图像生成能力,并将其与领先的开源和商业模型进行基准比较。具体研究目的包括:
- 评估GPT-4o在多模态图像生成任务中的表现:包括文本到图像、图像到图像、图像到三维以及图像到任意模态(X)的生成。
- 分析GPT-4o在不同设置下的优势和局限性:通过详细的案例研究,探讨GPT-4o在不同图像生成任务中的性能表现。
- 探索未来统一生成模型的发展方向:基于GPT-4o的研究结果,提出针对未来统一生成模型的有前景的研究方向,特别是强调架构设计和数据扩展的作用。
研究方法
数据集与基准模型
为了全面评估GPT-4o的图像生成能力,本研究选择了多个数据集和基准模型进行对比。数据集涵盖了广泛的图像生成任务,包括文本到图像、图像到图像、图像到三维等。基准模型则包括Gemini2.0Flash、Flux.1-Pro等领先的开源和商业模型。
评估指标
为了量化GPT-4o与其他基准模型在图像生成任务中的性能差异,本研究采用了多种评估指标,包括FID(Fréchet Inception Distance)分数、CLIP分数、美学分数、人类偏好分数(Human Preference Score, HPS)等。这些指标能够从不同角度衡量生成图像的质量、逼真度以及与输入文本或图像的对齐程度。
实验设计
本研究设计了一系列实验来全面评估GPT-4o的图像生成能力。实验涵盖了四个主要类别:
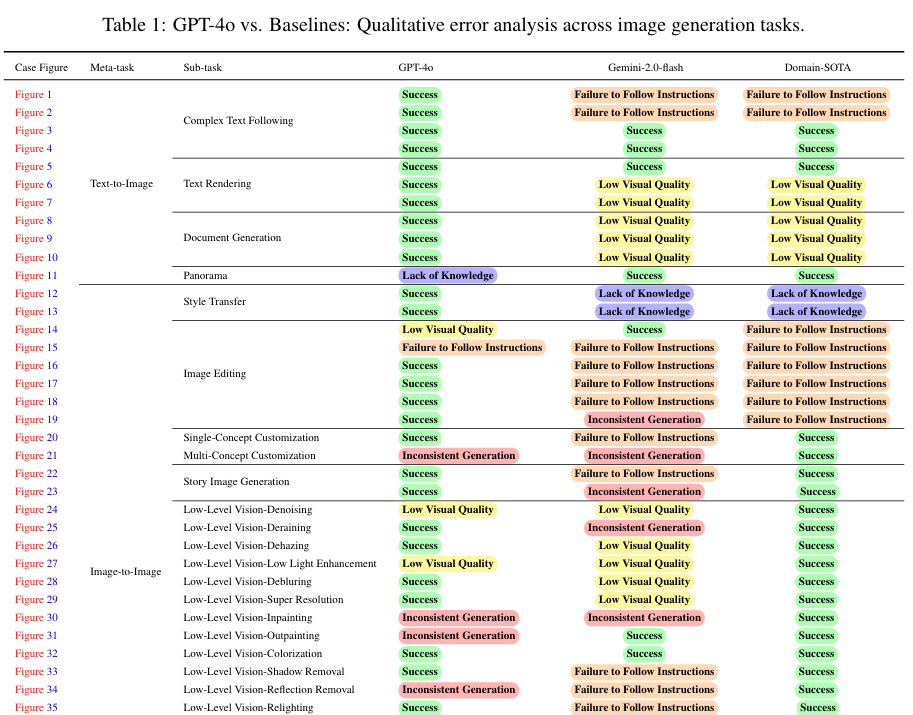
- 文本到图像生成:评估GPT-4o在根据文本指令生成图像方面的能力,包括复杂文本跟随、文本渲染、文档图像生成等子任务。
- 图像到图像生成:评估GPT-4o在将输入图像转换为特定风格或执行特定编辑操作方面的能力,包括风格迁移、图像编辑、故事图像生成等子任务。
- 图像到三维生成:评估GPT-4o在根据二维图像生成三维模型或视图方面的能力,包括图像到三维建模、UV地图到三维渲染、新颖视图合成等子任务。
- 图像到任意模态(X)生成:评估GPT-4o在将图像转换为其他模态数据(如深度图、法线图、语义分割图等)方面的能力。
研究结果
文本到图像生成
在文本到图像生成任务中,GPT-4o展示了出色的复杂文本跟随能力,能够准确地将文本描述中的对象、属性、关系等映射到生成的图像中。此外,GPT-4o在文本渲染方面也表现出色,能够生成清晰、准确的文本内容,特别是在长文本生成任务中表现尤为突出。然而,GPT-4o在生成具有复杂几何形状或文化特定元素的图像时,仍存在一定的局限性。
图像到图像生成
在图像到图像生成任务中,GPT-4o在风格迁移、图像编辑等子任务中均表现出色。它能够根据输入指令将图像转换为特定风格,同时保持图像的语义内容。在图像编辑任务中,GPT-4o能够准确地执行各种编辑操作,如添加、删除或替换对象,改变背景颜色或纹理等。然而,GPT-4o在保持原始图像特征的一致性方面仍存在一定的挑战。
图像到三维生成
在图像到三维生成任务中,GPT-4o能够根据二维图像生成具有一致形状和纹理的三维模型或视图。然而,GPT-4o在生成精细的三维结构或处理复杂场景时仍存在一定的局限性。
图像到任意模态(X)生成
在图像到任意模态(X)生成任务中,GPT-4o展示了强大的跨模态生成能力。它能够将图像转换为多种模态的数据,如深度图、法线图、语义分割图等。这些结果表明,GPT-4o在统一生成框架中具有重要的应用价值。
研究局限
尽管GPT-4o在图像生成任务中表现出色,但仍存在一些局限性。首先,GPT-4o的闭源性质使得其架构设计和训练过程无法被详细分析,这限制了对其性能优化的理解。其次,GPT-4o在生成具有复杂几何形状或文化特定元素的图像时仍存在一定的挑战。此外,GPT-4o在保持原始图像特征的一致性方面也存在一定的问题。
未来研究方向
基于本研究的结果,未来统一生成模型的研究可以从以下几个方面展开:
- 探索更高效的架构设计:未来的研究可以探索更高效的架构设计,以减少模型参数和计算开销,同时提高生成图像的质量和多样性。
- 加强多模态融合能力:未来的研究可以进一步加强多模态融合能力,实现更精细的图像与文本之间的对齐和交互。
- 提升生成图像的逼真度和多样性:未来的研究可以探索新的训练策略和数据增强技术,以提升生成图像的逼真度和多样性。
- 开发开源的基准模型:为了推动统一生成模型的研究和发展,未来的研究可以开发更多开源的基准模型和数据集,以供学术界和工业界共同使用和评估。
总之,本研究通过实证研究全面评估了GPT-4o的图像生成能力,并揭示了其在不同任务中的优势和局限性。未来的研究将在此基础上继续探索更高效的架构设计、更强的多模态融合能力以及更精细的图像生成技术,以推动统一生成模型的不断发展和应用。

















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









