






摘要:语言长久以来被视为人类推理不可或缺的工具。大型语言模型(LLM)的突破激发了利用这些模型解决复杂推理任务的浓厚研究兴趣。研究人员已经超越了简单的自回归词元生成,引入了“思维”的概念——即代表推理过程中间步骤的词元序列。这一创新范式使LLM能够模仿复杂的人类推理过程,如树搜索和反思性思维。近期,一种新兴的学习推理趋势采用强化学习(RL)来训练LLM掌握推理过程。这种方法通过试错搜索算法自动生成高质量的推理轨迹,为LLM提供了大量额外的训练数据,从而显著扩展了其推理能力。此外,最近的研究表明,在测试时推断过程中鼓励LLM使用更多词元进行“思考”,可以进一步显著提升推理准确性。因此,训练时和测试时的扩展相结合,展现了一个新的研究前沿——通往大型推理模型的路径。OpenAI的o1系列的推出标志着这一研究方向的重大里程碑。在本综述中,我们全面回顾了LLM推理领域的最新进展。我们首先介绍了LLM的基础背景,然后探讨了推动大型推理模型发展的关键技术组件,重点关注自动化数据构建、学习推理技术和测试时扩展。我们还分析了构建大型推理模型的流行开源项目,并总结了存在的挑战以及未来的研究方向。Huggingface链接:Paper page ,论文链接:2501.09686
1. 引言
背景与动机:
- 语言长久以来被视为人类推理不可或缺的工具。随着大型语言模型(LLMs)的突破,利用这些模型解决复杂推理任务的研究兴趣显著增强。
- LLMs通常采用Transformer架构,并在大规模文本语料库上进行预训练,以执行下一个词预测任务。随着模型规模和训练数据的增加,其性能显著提升。
- 除了自然语言处理任务外,LLMs还展现出解决代码生成、机器人控制、自主代理等多种任务的能力。其中,类似人类的推理能力尤为引人注目,因为它展示了LLMs泛化到复杂现实世界问题的巨大潜力。
研究趋势与挑战:
- 近期,一个新兴的研究趋势是学习推理,即利用强化学习(RL)训练LLMs掌握推理过程。这种方法通过试错搜索算法自动生成高质量的推理轨迹,显著扩展了LLMs的推理能力。
- 然而,训练数据缺乏是这一研究方向的主要挑战。人工标注成本高昂,特别是对于逐步推理轨迹的标注。因此,研究人员开始探索利用外部验证和LLM驱动的自动化搜索来生成推理轨迹。
2. 大型语言模型推理的基础
预训练阶段:
- 预训练是LLMs训练的基础阶段,对于发展推理能力至关重要。LLMs通常在大规模文本语料库上进行预训练,以获取核心语言知识和多样化的世界知识。
- 预训练阶段不仅使LLMs具备出色的上下文学习能力,还为其后续在复杂任务中的表现奠定了坚实基础。例如,包含丰富代码和数学内容的数据集对于开发健壮的推理技能至关重要。
微调与对齐:
- 微调技术被广泛应用于提高LLMs的推理能力。通过监督微调(SFT),LLMs可以在特定任务或领域上实现零样本学习和改进的性能。
- 对齐阶段则涉及使LLMs的输出与人类偏好和需求保持一致。这通常通过强化学习从人类反馈(RLHF)等方法实现,以指导模型生成有帮助、无害和诚实的内容。
高级推理的提示技术:
- 为了提高LLMs的推理能力,研究人员开发了各种提示技术。其中,“链式思考”(CoT)提示技术尤为有效,它能够在测试时无需额外训练即可引出逐步的人类推理过程。
- 多路径探索方法(如“树状思考”ToT)和分解方法(如“最少到最多”Least-to-Most Prompting)进一步扩展了LLMs的推理能力,使其能够处理更复杂的任务。
3. 数据构建:从人工标注到LLM自动化
人工标注的局限性:
- 人工标注在构建LLM推理数据集方面发挥着关键作用,但其成本高昂且难以扩展。随着LLM训练所需数据量的增加,人工标注的局限性日益凸显。
LLM自动化标注:
- 为了解决人工标注的局限性,研究人员开始探索利用LLMs进行自动化标注。这种方法通过利用LLMs的强大指令跟随能力和上下文学习能力,以较低的成本生成高质量的标注数据。
- 自动化标注方法包括使用外部更强的LLM进行标注、蒙特卡洛树搜索(MCTS)模拟等。这些方法显著提高了数据标注的效率和规模。
4. 学习推理:从监督学习到强化学习
监督微调:
- 监督微调是提高LLMs推理能力的常用方法。通过标注数据集进行微调,LLMs可以在特定任务上实现更好的性能。然而,监督微调可能面临数据稀缺和灾难性遗忘等问题。
强化学习与直接偏好优化:
- 强化学习(RL)为训练LLMs掌握推理过程提供了新的框架。通过试错搜索和奖励信号,RL使LLMs能够学习最优策略以实现特定目标。
- 直接偏好优化(DPO)进一步简化了RL过程,通过直接优化偏好数据而非训练奖励模型来对齐LLMs的输出与人类偏好。
5. 测试时扩展:从CoT到PRM引导搜索
引发深思熟虑的思考:
- 除了训练时的优化外,测试时的提示技术(如CoT和ToT)也能显著提高LLMs的推理能力。这些技术通过引导LLMs在测试时进行逐步推理,从而生成更准确的结果。
PRM引导搜索:
- 过程奖励模型(PRM)在测试时扩展中发挥着重要作用。通过为推理过程中的每一步提供奖励信号,PRM能够引导LLMs生成高质量的推理轨迹。
- PRM引导搜索方法包括多数投票、树搜索、波束搜索和前瞻搜索等。这些方法通过优化推理路径的选择来提高LLMs的推理准确性。
6. 迈向大型推理模型的路径
OpenAI o1系列的发展:
- OpenAI的o1系列模型是大型推理模型发展的重要里程碑。这些模型在复杂任务(如数学、编程和科学问题解决)中表现出色,显著推动了LLMs推理能力的发展。
- o1系列模型的有效知识整合、系统问题分解和可靠连贯的推理能力使其能够在各种基准测试中取得优异成绩。
开源项目的发展:
- 开源项目在推动大型推理模型的发展方面也发挥着重要作用。例如,OpenR、LLaMA-Berry和Journey Learning等项目致力于复制OpenAI o1系列的强大推理能力,并为研究人员提供了有价值的见解。
7. 其他测试时增强技术
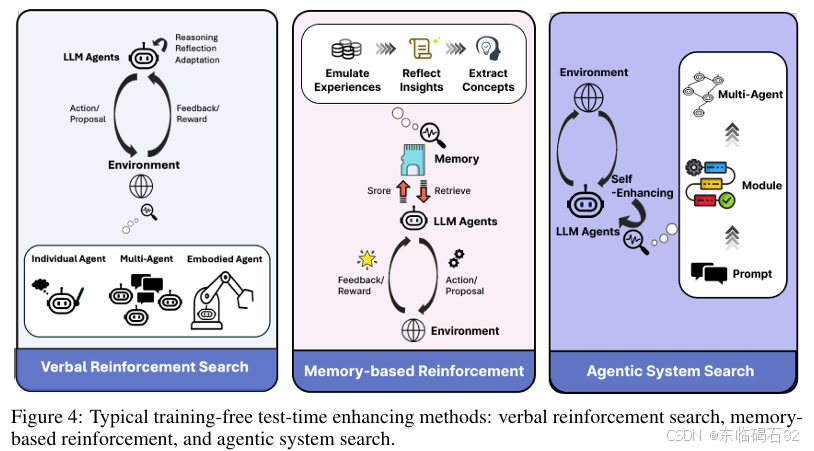
语言强化搜索:
- 语言强化搜索(VRS)是一种利用LLMs的预训练推理和语义能力来探索和优化解决方案空间的方法。通过迭代反馈循环,VRS能够在不增加额外训练的情况下提高LLMs的推理能力。
基于记忆的强化:
- 基于记忆的强化方法通过为LLMs配备外部记忆模块来增强其在开放任务中的推理能力。这些记忆模块存储过去的观察和行动,并为后续推理提供有用的信息。
代理系统搜索:
- 代理系统搜索方法通过利用LLMs来搜索和优化代理系统的工作流程,从而提高其推理能力。这种方法包括在提示级别、模块级别和代理级别进行搜索。
8. 评估基准
数学问题:
- 数学推理是评估LLMs推理能力的重要基准。从基础算术到高级大学数学,数学问题基准为评估LLMs的数学理解和问题解决能力提供了系统的方法。
逻辑问题:
- 逻辑推理是评估LLMs认知能力的另一个重要方面。这包括演绎推理、归纳推理和溯因推理等多种类型。
常识问题:
- 常识推理是NLP领域的一个重大挑战。各种基准数据集旨在评估LLMs在理解和应用日常常识知识方面的能力。
编码问题:
- 随着LLMs在代码生成任务中表现出色,编码问题基准成为评估其推理能力的重要工具。这些基准通过评估LLMs在生成准确、高效和可靠代码方面的能力来考察其编程技能。
代理问题:
- 代理基准为评估LLMs作为独立代理在交互式环境中的表现提供了重要手段。这些基准涵盖决策制定、推理和环境交互等多个方面。
9. 启示与未来研究方向
训练后阶段的扩展定律:
- OpenAI o1系列的成功启示我们,训练后阶段的扩展定律可能成为大型语言模型未来发展的驱动力。通过自我对抗学习和过程奖励学习等方法,我们可以进一步提高LLMs的推理能力。
慢速思考与推理:
- 慢速思考的概念为LLMs的推理能力提供了新的视角。通过模仿人类大脑的“系统1+系统2”机制,我们可以设计更有效的推理数据生成、奖励函数和学习过程。
下游应用与开放问题:
- LLMs的推理能力不仅限于基准任务,还广泛适用于各种下游应用。未来的研究应关注如何将LLMs的推理能力应用于更广泛的领域,并解决当前研究中的互补性问题。
结论
大型语言模型的突破为发展大型推理模型提供了重要机遇。通过引入“思维”的概念、利用强化学习进行训练时扩展以及采用搜索算法进行测试时扩展,我们正在迈向能够解决复杂认知任务的大型推理模型。未来的研究将继续探索LLMs的推理能力极限,并推动人工智能在解决现实世界问题中的应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









