






摘要:指令遵循能力使得现代大型语言模型(LLM)成为得力助手。然而,如何驾驭大型语言模型以执行复杂指令的关键仍然扑朔迷离,因为开源社区训练的模型与领先公司训练的模型之间存在巨大差距。为了缩小这一差距,我们提出了一种简单且可扩展的方法UltraIF,用于构建能够利用开源数据遵循复杂指令的大型语言模型。UltraIF首先将真实世界的用户提示分解为更简单的查询、约束条件以及针对这些约束条件的相应评估问题。然后,我们训练了一个UltraComposer来组合与约束条件相关的提示和评估问题。这个提示组合器使我们能够合成复杂的指令,并通过评估问题过滤响应。在我们的实验中,我们首次成功地使LLaMA-3.1-8B-Base模型在不使用任何基准信息的情况下,仅在5个指令遵循基准测试上追上了其指令版模型的性能,且仅使用8B模型作为响应生成器和评估器。对齐后的模型在其他基准测试上也取得了具有竞争力的分数。此外,我们还展示了UltraIF能够通过自我对齐进一步提升LLaMA-3.1-8B-Instruct的性能,从而激发了该方法更广泛的应用场景。我们的代码将在https://github.com/kkk-an/UltraIF上提供。Huggingface链接:Paper page,论文链接:2502.04153
1. 引言
1.1 大型语言模型与指令遵循
大型语言模型(LLMs)如Meta的LLaMA和OpenAI的GPT系列,已展现出在遵循复杂指令方面的卓越能力。这种能力使得LLMs成为有用的助手,能够理解和执行多样化的任务。然而,尽管这些模型在指令遵循方面取得了显著进展,但如何使它们更好地处理复杂指令仍然是一个未解之谜。
1.2 开源与商业模型的差距
开源社区训练的LLMs与领先公司训练的模型在性能上存在巨大差距。这主要是由于训练数据、方法和资源的不同。领先公司通常拥有大量的高质量指令遵循数据,而开源社区则难以获取这些资源。
1.3 UltraIF的提出
为了缩小这一差距,本文提出了一种简单且可扩展的方法UltraIF,旨在利用开源数据构建能够遵循复杂指令的LLMs。UltraIF通过分解真实世界的用户提示,训练一个专门的模型来合成复杂指令,并通过评估问题过滤响应,从而提高LLMs的指令遵循能力。
2. UltraIF方法概述
2.1 UltraIF的核心思想
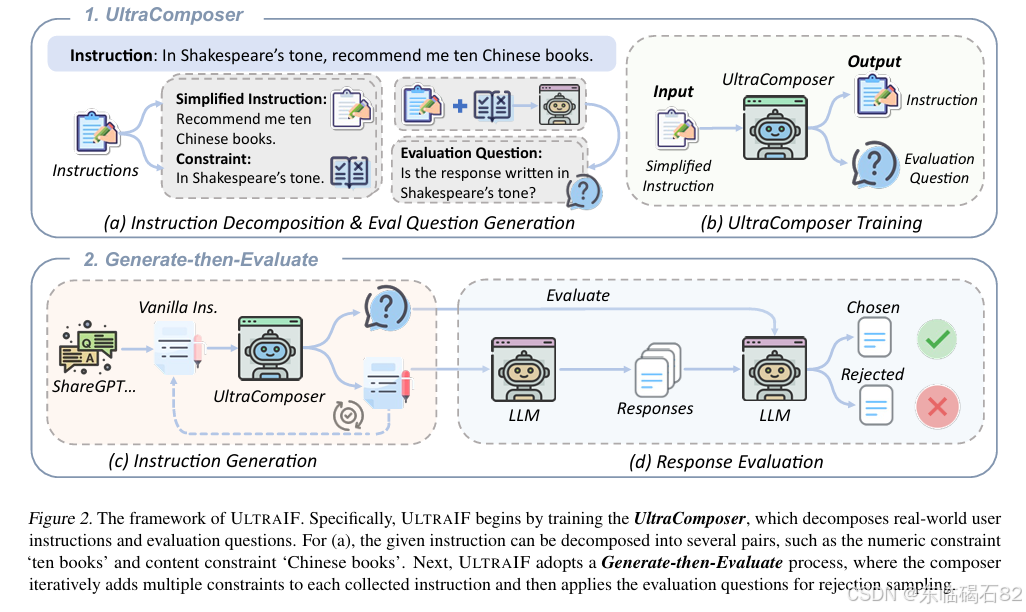
UltraIF的核心思想是将真实世界的用户提示分解为更简单的查询、约束条件和评估问题,然后训练一个UltraComposer模型来组合这些元素,生成复杂的指令。通过这种方式,UltraIF能够利用开源数据合成大规模的指令遵循数据集,从而提高LLMs的性能。
2.2 UltraComposer的训练
UltraComposer的训练过程包括三个关键步骤:指令分解、评估问题生成和UltraComposer训练。首先,利用LLMs将复杂的用户提示分解为简化的查询和约束条件。然后,为每个约束条件生成相应的评估问题,以验证响应是否满足要求。最后,训练UltraComposer模型,以简化的查询为输入,输出原始指令及其评估问题。
2.3 Generate-then-Evaluate过程
UltraIF采用Generate-then-Evaluate过程来生成高质量的指令遵循数据。首先,使用UltraComposer将收集到的用户提示合成为更复杂的指令。然后,提示LLMs为每个合成的指令生成响应。最后,使用评估问题来评估响应的质量,并选择高质量的响应作为训练数据。
3. 实验与结果
3.1 实验设置
在实验中,我们使用了多个开源数据集来训练UltraComposer,包括ShareGPT、OpenHermes 2.5和No Robots。我们选择了LLaMA-3.1-8B-Base作为基线模型,并通过UltraIF生成的数据对其进行微调。此外,我们还尝试了两种训练策略:监督微调(SFT)和迭代在线直接偏好优化(DPO)。
3.2 主要结果
- UltraIF的性能:在五个指令遵循基准测试上,UltraIF显著优于所有基线方法。特别是在IFEval和Multi-IF基准测试上,UltraIF实现了显著的性能提升。
- DPO的有效性:迭代DPO过程进一步提高了模型的性能,特别是在需要LLM评估的基准测试上。与SFT相比,DPO平均提高了5%的性能。
- 数据规模的影响:通过增加训练数据的规模,UltraIF能够进一步提高模型的性能。在175k数据的SFT阶段和20k数据的DPO阶段后,UltraIF在多个基准测试上达到了与LLaMA-3.1-8B-Instruct相当的性能。
3.3 跨域验证
我们还在数学、推理、编码和对话任务等四个一般领域评估了UltraIF的性能。结果表明,UltraIF在编码和对话任务上实现了显著的性能提升,同时在数学和推理任务上也保持了竞争力。这验证了UltraIF在不同领域中的泛化能力。
4. 分析
4.1 迭代DPO过程的影响
迭代DPO过程通过逐渐增加指令的复杂性,逐步提高了模型的性能。然而,随着迭代次数的增加,优化目标开始偏离,导致性能下降。为了缓解这一问题,我们在最后一次迭代中引入了噪声对比估计(NCA)损失,从而稳定了训练过程并提高了性能。
4.2 UltraIF的可扩展性
UltraIF通过捕捉真实世界指令的分布,有效地减少了约束条件与原始指令之间的不一致性。与基线方法相比,UltraIF在数据集合成方面表现出更高的通过率,从而降低了成本并提高了效率。此外,在拒绝采样阶段,UltraIF仅需一次LLM调用即可完成评估,而基线方法则需要多次函数调用。
4.3 自我对齐的潜力
我们还探索了UltraIF在自我对齐方面的潜力。通过使用LLaMA-3.1-8B-Instruct生成的数据来训练自身,UltraIF显著提高了模型的性能。这表明UltraIF不仅能够优化基础模型,还能够进一步提升已经很强的模型。
4.4 多轮数据的影响
我们分析了在SFT阶段加入多轮数据对UltraIF性能的影响。结果表明,多轮数据的加入显著提高了模型在多轮指令遵循基准测试上的性能。这强调了多轮交互在训练中的重要性,因为它允许模型更好地理解对话上下文和依赖关系。
4.5 消融研究
我们还对UltraIF进行了消融研究,以评估不同组件的重要性。结果表明,随着指令复杂性的增加,模型的性能也相应提高。此外,评估问题过滤模块在保持高质量训练数据方面发挥了关键作用。
5. 相关工作
5.1 指令遵循
指令遵循已成为LLMs研究的关键领域。早期方法主要依赖于人工标注的指令遵循数据集,而近期方法则开始利用LLMs来自动化这一过程。然而,这些方法仍然面临数据质量和多样性的挑战。相比之下,UltraIF通过分解真实世界的用户提示来合成高质量的指令遵循数据,从而提高了数据的多样性和质量。
5.2 偏好学习与指令遵循
偏好学习通过优化模型以生成高质量的响应来提高指令遵循能力。然而,传统方法如RLHF需要大量的人类反馈,这限制了其可扩展性。近期方法如DPO通过直接优化偏好来减少对人类反馈的依赖。UltraIF通过生成评估问题来指导偏好学习,从而提高了训练效率和可扩展性。
6. 结论
在本文中,我们提出了一种简单且可扩展的方法UltraIF,用于合成高质量的指令遵循数据。通过分解真实世界的用户提示并训练UltraComposer模型,UltraIF能够生成复杂的指令并通过评估问题过滤响应。实验结果表明,UltraIF显著提高了LLMs的指令遵循能力,并在多个基准测试上实现了具有竞争力的性能。此外,我们还展示了UltraIF在自我对齐和多轮指令遵循方面的潜力。未来工作将进一步探索UltraIF在其他领域和任务中的应用,并改进其性能和可扩展性。
7. 影响声明
7.1 透明度与可复现性
UltraIF通过利用开源数据来训练模型,提高了透明度和可复现性。这有助于促进LLMs研究的发展,并鼓励更多研究者参与到这一领域中来。
7.2 民主化与可访问性
UltraIF的贡献在于推动了LLMs开发的民主化,使得更多研究者和开发者能够访问和使用先进的模型。这有助于降低技术门槛,并促进创新和技术进步。
7.3 社会影响与伦理考量
尽管UltraIF具有诸多优点,但其潜在的社会影响和伦理问题也不容忽视。例如,使用开源数据可能引入偏差和误导性信息,从而影响模型的性能和可靠性。此外,LLMs的广泛应用也可能引发隐私和安全问题。因此,在使用UltraIF和其他LLMs技术时,需要仔细权衡其利弊并制定相应的伦理准则和规范。
8. 参考文献
本文引用了大量相关文献来支持我们的研究工作。这些文献涵盖了指令遵循、偏好学习、大型语言模型等多个领域,为我们提供了丰富的背景知识和理论基础。我们感谢这些文献的作者们为LLMs研究做出的贡献,并希望我们的工作能够进一步推动这一领域的发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









