






现有的端到端语音大型语言模型(LLMs)通常依赖大规模标注数据进行训练,而数据高效训练方面尚未得到深入探讨。我们关注语音和文本之间的两个根本问题:表示空间差距和序列长度不一致性。为此,我们提出了Soundwave,它采用了一种高效的训练策略和新颖的架构来解决这些问题。结果表明,在仅使用五十分之一训练数据的情况下,Soundwave在语音翻译和AIR-Bench语音任务上的表现优于先进的Qwen2-Audio。进一步的分析显示,Soundwave在对话中仍然保持着其智能性。该项目可在https://github.com/FreedomIntelligence/Soundwave上获取。Huggingface链接:Paper page,论文链接:2502.12900
1. 引言
大型语言模型(LLMs)已深刻改变了自然语言处理(NLP)的范式,其卓越的理解和推理能力令人瞩目。近年来,多模态LLMs也迅速发展,GPT-4等模型的成功凸显了语音聚焦LLMs的潜力。然而,实现LLMs与语音的无缝交互仍面临重大挑战,即需要LLMs能够准确解释语音,这本质上是使LLMs具备“听力”。目前,大多数语音LLMs依赖于庞大的标注数据集和大量的计算资源来实现语音感知。例如,Qwen2-Audio模型需要约50万小时的数据才能达到跨模态功能,而先进的自动语音识别(ASR)模型则需要1000小时的数据来达到可比结果。这种数据需求与计算资源的巨大差异凸显了开发高效语音LLMs方法的必要性。
2. 方法论
2.1 总体设计
为了克服语音和文本之间的表示空间差距和序列长度不一致性,我们提出了Soundwave模型。该模型采用三阶段训练框架,包括对齐阶段、缩小阶段和监督微调(SFT)阶段。训练过程涉及多个模块,包括音频编码器、对齐适配器、缩小适配器和LLMs适配器。
- 音频编码器:使用预训练的Whisper Large V3模型,以产生语义特征而非向量量化特征或自监督特征。
- 对齐适配器:由线性层和Transformer层组成,用于将音频特征转换为与LLMs兼容的表示空间。
- 缩小适配器:通过选择关键内容和融合辅助信息(如音调和音高)来缩短音频序列,同时保持信息无损。
- LLMs适配器:使用LoRA进行高效微调,以适应特定任务。
2.2 对齐阶段
该阶段旨在解决表示空间差距问题。我们使用辅助CTC损失来加速对齐过程,并通过高质量数据来提高收敛速度。具体做法包括:
- 辅助CTC损失:通过线性层和Transformer层将音频特征转换为与LLMs兼容的表示,并使用CTC损失进行训练。
- 高质量对齐数据:使用验证过的ASR数据和标准化的声音数据来支持对齐过程。验证过的ASR数据具有较低的词错误率(WER),而标准化的声音数据则通过统一标签格式和音频长度来提高质量。
2.3 缩小阶段
该阶段旨在解决序列长度不一致性问题,并通过引入各种基础音频任务来提高模型的泛化能力。具体做法包括:
- 动态缩小:使用CTC预测来选择关键内容,并通过注意力机制融合辅助信息,以缩短音频序列并保持信息无损。
- 动态数据混合:采用基于采样温度的动态数据混合策略,以平衡不同任务的数据量,防止模型过拟合。
2.4 监督微调阶段
在SFT阶段,我们仅微调LoRA参数,以使语音LLMs能够处理更复杂的任务,并直接根据说话者的语音进行响应。我们使用文本和语音指令来训练模型,以增强其遵循指令的能力。
3. 数据工程
为了确保训练数据的质量和多样性,我们精心选择了多个数据集,并对数据进行了清洗和过滤。具体做法包括:
- ASR数据:选择高质量的数据集,并应用SpecAugment来增强模型的鲁棒性。同时,通过拼接不同说话者的语音来帮助LLMs理解对话和说话者数量。
- 声音数据:将环境声音嵌入到音频中,以构建混合声音数据。同时,对声音数据进行标准化处理,包括统一标签格式和音频长度。
- 指令数据:设计了三种类型的QA格式来构建SFT数据,以提高模型理解和分析语音的能力。此外,还使用了Chain of Thought(CoT)方法来降低复杂任务的复杂性。
4. 实验
4.1 设置
我们使用Whisper Large V3作为音频编码器,Llama-3.1-8B-Instruct作为基础模型。对齐适配器和缩小适配器分别包含635M和67M参数。训练在32A800 GPUs上进行,总训练时间约为五天。
4.2 结果
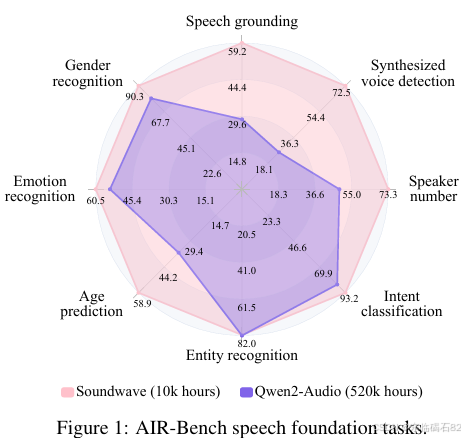
在基础音频任务上,Soundwave在语音翻译和情感识别任务上表现出色,显著优于Qwen2-Audio模型。在AIR-Bench语音基础任务上,Soundwave的平均准确率达到了75.5%,优于其他开源模型。此外,Soundwave在零样本语音翻译任务上也表现出色,展示了其强大的泛化能力。
- ASR任务:虽然Soundwave在ASR任务上的表现略逊于Qwen2-Audio,但这主要是由于Soundwave使用的训练数据量较少。随着训练数据的增加,Soundwave在ASR任务上的表现有望进一步提升。
- 语音翻译任务:Soundwave在多种语言对的语音翻译任务上均表现出色,特别是在低资源语言对上取得了显著进步。
- 情感识别任务:Soundwave在情感识别任务上的准确率达到了60.5%,优于Qwen2-Audio模型的54.6%。
4.3 分析
通过进一步分析,我们发现Soundwave的对齐适配器和缩小适配器在提高训练效率和模型性能方面发挥了关键作用。具体来说:
- 对齐效果:Soundwave的音频和文本表示之间的相似性显著高于其他方法,这表明我们的对齐策略是有效的。
- 训练速度:Soundwave在对齐阶段的训练速度几乎是其他方法的三倍,这得益于我们的高效训练策略和数据质量。
- 数据质量:高质量的数据对于训练效率至关重要。使用未清洗的数据会导致训练过程不稳定,并显著降低模型性能。
5. 相关工作
许多研究致力于构建端到端的语音LLMs,以实现语音和文本之间的无缝交互。然而,大多数方法仍然依赖于大量的训练数据。相比之下,Soundwave通过采用高效的训练策略和新颖的架构,成功地在仅使用少量训练数据的情况下实现了出色的性能。
6. 结论
语音理解是多模态LLMs的核心能力之一。然而,当前的语音LLMs通常依赖于庞大的训练数据和计算资源。为了解决这个问题,我们提出了Soundwave模型,它采用了一种高效的训练策略和新颖的架构来解决语音和文本之间的表示空间差距和序列长度不一致性问题。实验结果表明,Soundwave在多种语音任务上表现出色,并在仅使用少量训练数据的情况下超越了先进的Qwen2-Audio模型。未来工作将包括扩展模型的参数规模、引入音乐和多语言数据以及进一步验证我们的方法在大规模模型上的可行性。
7. 影响与限制
Soundwave模型的成功表明,在LLMs中实现语音-文本对齐并不一定需要庞大的训练数据。通过采用高效的训练策略和新颖的架构,我们可以在保持模型性能的同时显著降低数据需求。然而,Soundwave模型仍存在一些限制,如尚未在大规模模型上进行验证、声音数据量相对较小以及在音乐理解和多语言支持方面存在不足。未来工作将致力于解决这些问题,并进一步推动语音LLMs的发展。
8. 伦理考虑
在研究和应用Soundwave模型时,我们严格遵守学术标准和开源许可协议。我们使用的数据集均为公开可用的开源数据集,并确保在数据收集和处理过程中遵循相关法律法规和伦理准则。此外,我们还采取了措施来防止模型被滥用于生成误导性和有害的内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









