






摘要:现有的大型视觉-语言模型(LVLMs)能够处理包含多达128k个视觉和文本标记的上下文输入,但它们在生成超过1000个单词的连贯输出时却显得力不从心。我们发现,其主要限制在于监督微调(SFT)过程中缺乏长输出示例。为了解决这一问题,我们推出了LongWriter-V-22k,这是一个包含22,158个示例的SFT数据集,每个示例都包含多张输入图像、一条指令以及对应的长度在0到10,000个单词之间的输出。此外,为了生成与输入图像保持高保真度的长输出,我们对SFT模型采用了直接偏好优化(DPO)方法。考虑到为长输出(例如3000个单词)收集人类反馈的成本高昂,我们提出了IterDPO方法,该方法将长输出拆分为多个片段,并通过迭代修正与原始输出形成偏好对。此外,我们还开发了MMLongBench-Write基准测试,其中包含六项任务,用于评估VLMs的长生成能力。我们采用LongWriter-V-22k和IterDPO训练的70亿参数模型在该基准测试中表现出色,甚至超越了像GPT-4o这样的大型专有模型。代码和数据请访问:GitHub - THU-KEG/LongWriter-V: LongWriter-V: Enabling Ultra-Long and High-Fidelity Generation in Vision-Language Models
Huggingface链接:Paper page,论文链接:2502.14834
本文提出了一种新的方法,旨在增强视觉-语言模型(VLMs)生成超长且高保真度文本的能力。随着视觉-语言模型在处理多模态输入方面的能力日益增强,其在各种实际应用中的潜力也日益凸显。然而,现有的大型视觉-语言模型在生成超过1000个单词的连贯输出时仍面临挑战。本文通过分析这一限制的原因,并提出相应的解决方案,为VLMs的长文本生成能力提供了新的思路。
- 研究背景与动机:
- 视觉-语言模型的发展现状:近年来,视觉-语言模型在处理视觉和文本输入方面取得了显著进展。这些模型能够理解复杂的视觉场景,并将其与文本信息相结合,以执行各种任务,如图像描述、视觉问答等。然而,尽管这些模型在处理长上下文输入方面有所突破,但在生成长文本输出时仍受到限制。
- 长文本生成的需求:在许多实际应用中,如创意写作、专业写作、医疗报告生成等,需要模型能够生成详细且连贯的长文本。然而,现有的VLMs在生成超过1000个单词的文本时,往往会出现内容重复、逻辑不连贯等问题。
- 研究动机:本文旨在解决VLMs在长文本生成方面的限制,通过引入新的数据集和训练方法,提高模型生成超长且高保真度文本的能力。
- 现有模型的限制分析:
- 输出长度限制:本文通过实验发现,现有的VLMs在生成文本时,输出长度普遍限制在1000个单词以内。这一限制主要源于模型在监督微调(SFT)过程中缺乏长输出示例。
- 监督微调数据集的影响:实验结果显示,SFT数据集中长输出示例的比例对模型输出长度有显著影响。当SFT数据集中包含更多长输出示例时,模型能够生成更长的文本。
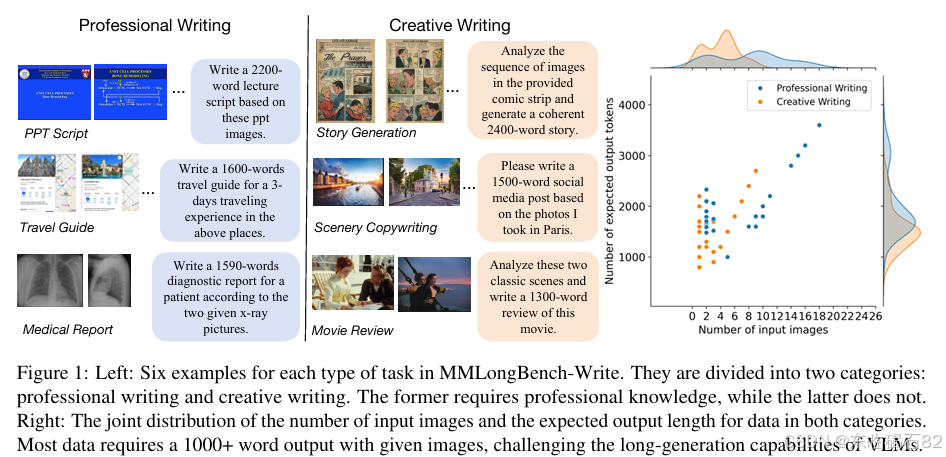
- 基准测试设计:为了更全面地评估VLMs的长生成能力,本文设计了MMLongBench-Write基准测试,其中包含六个任务,要求模型根据视觉输入生成长文本。
- LongWriter-V方法介绍:
- LongWriter-V-22k数据集:为了解决现有模型在长文本生成方面的限制,本文引入了LongWriter-V-22k数据集。该数据集包含22,158个示例,每个示例都包含多张输入图像、一条指令以及对应的长度在0到10,000个单词之间的输出。这些示例通过一种两阶段的方法生成,首先使用VLM生成大纲,然后根据大纲逐段生成文本。
- 直接偏好优化(DPO):为了提高生成文本的质量,本文对SFT模型采用了DPO方法。DPO方法通过收集人类专家对模型输出的修正意见,形成偏好对,然后利用这些偏好对优化模型。然而,为长输出收集人类反馈的成本高昂。因此,本文提出了IterDPO方法,将长输出拆分为多个片段,并通过迭代修正与原始输出形成偏好对,从而有效降低了收集人类反馈的成本。
- 模型训练与结果:本文采用LongWriter-V-22k和IterDPO方法训练了一个70亿参数的模型。实验结果显示,该模型在MMLongBench-Write基准测试中表现出色,甚至超越了像GPT-4o这样的大型专有模型。
- 实验结果与分析:
- 基准测试性能:在MMLongBench-Write基准测试中,本文训练的模型在各个任务上都取得了优异的成绩。特别是在需要生成超过3000个单词的文本的任务中,该模型展现出了显著的优势。
- 长度与质量得分:实验结果显示,本文训练的模型在长度和质量得分上都优于其他基线模型。这表明该模型不仅能够生成更长的文本,而且生成文本的质量也更高。
- 人类评价:为了更全面地评估模型生成文本的质量,本文还进行了人类评价实验。实验结果显示,人类评价者更倾向于选择本文训练的模型生成的文本,这进一步证明了该模型在生成长文本方面的优势。
- 消融实验与模型分析:
- 消融实验:本文通过消融实验分析了LongWriter-V-22k数据集中不同数据源对模型性能的影响。实验结果显示,多图像指令和回译数据对模型性能的提升最为显著。此外,IterDPO方法和AI反馈对模型性能的提升也起到了重要作用。
- 模型分析:本文通过对模型生成文本的详细分析,发现该模型在生成长文本时能够保持较高的连贯性和逻辑性。同时,该模型还能够根据指令中的要求调整生成文本的长度和风格。
- 相关工作与比较:
- 视觉-语言模型的长上下文理解:本文回顾了近年来在视觉-语言模型长上下文理解方面的研究工作。这些工作主要集中在提高模型处理长上下文输入的能力上,而在长文本生成方面的研究相对较少。
- 长文本生成方法:本文还回顾了现有的长文本生成方法,包括计划-写作方法、递归神经网络等。然而,这些方法在处理视觉-语言输入时仍存在局限性。
- 与现有方法的比较:本文将LongWriter-V方法与现有的长文本生成方法进行了比较。实验结果显示,LongWriter-V方法在生成超长且高保真度文本方面表现出色,优于其他现有方法。
- 未来工作与局限性:
- 未来工作:未来的工作可以探索更高效的训练策略和更大的数据集,以进一步提高VLMs的长文本生成能力。此外,还可以将LongWriter-V方法扩展到其他多模态任务中,如视频描述、图像生成等。
- 局限性:尽管LongWriter-V方法在长文本生成方面取得了显著进展,但仍存在一些局限性。例如,LongWriter-V-22k数据集的大小可能不足以充分捕捉长文本生成任务的多样性。此外,该数据集和基准测试目前仅支持英语和中文,未来工作应考虑扩展到其他语言。
- 伦理考虑:
- 信息准确性:尽管VLMs在生成文本方面表现出色,但生成的信息可能不准确或误导性。特别是在处理涉及常识性知识的任务时,模型可能会输出与上下文不符的信息。因此,在部署这些模型时,应采取额外的保障措施和验证机制。
- 隐私保护:在收集用于训练的数据时,应确保数据经过脱敏处理以保护个人隐私。本文使用的所有数据源都是公开的,并获得了相应的许可。
总结:
本文提出了一种新的方法,旨在增强视觉-语言模型的长文本生成能力。通过引入LongWriter-V-22k数据集和IterDPO方法,本文成功训练了一个能够生成超长且高保真度文本的VLM。实验结果显示,该模型在MMLongBench-Write基准测试中表现出色,甚至超越了像GPT-4o这样的大型专有模型。此外,本文通过消融实验和模型分析深入探讨了不同因素对模型性能的影响。尽管本文的工作取得了显著进展,但仍存在一些局限性,如数据集大小、语言支持等。未来的工作可以探索更高效的训练策略和更大的数据集,以进一步提高VLMs的长文本生成能力。同时,在部署这些模型时,也应考虑伦理和隐私保护问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









