






摘要:东南亚(SEA)是一个语言和文化多样性极为丰富的地区,然而在视觉-语言(VL)研究中,该地区的代表性仍然严重不足。这往往导致人工智能(AI)模型无法捕捉到东南亚文化的细微差别。为了填补这一空白,我们推出了SEA-VL,这是一项开源倡议,旨在为东南亚语言开发高质量、具有文化相关性的数据。通过邀请来自东南亚国家的贡献者参与,SEA-VL旨在确保更好的文化相关性和多样性,促进在视觉-语言研究中对代表性不足的语言的更大包容性。除了众包之外,我们的倡议还更进一步,探索通过爬取和图像生成来自动收集具有文化相关性的图像。首先,我们发现图像爬取的文化相关性约为85%,同时比众包更具成本效益和时间效率。其次,尽管生成式视觉模型取得了显著进展,但合成图像在准确反映东南亚文化方面仍然不可靠。生成的图像往往无法反映该地区的细微传统和文化背景。总的来说,我们收集了128万张与东南亚文化相关的图像,比其他现有数据集大50倍以上。通过SEA-VL,我们旨在缩小东南亚在代表性方面的差距,促进开发更具包容性的AI系统,真实展现东南亚地区的多元文化。Huggingface链接:Paper page,论文链接:2503.07920
研究背景和目的
研究背景
东南亚(SEA)是一个语言和文化多样性极为丰富的地区,拥有超过1300种语言,是世界语言多样性最为显著的地区之一。然而,在视觉-语言(VL)研究领域,东南亚的代表性严重不足。这种代表性不足往往导致人工智能(AI)模型无法准确捕捉东南亚文化的细微差别,从而在应用中可能出现文化偏差或误解。例如,在图像描述、视觉问答等任务中,模型可能无法正确理解或描述具有东南亚特色的图像内容。
现有的一些视觉-语言数据集主要集中在西方或少数几个主要语言上,缺乏针对东南亚语言和文化的专门数据集。这限制了AI模型在东南亚地区的应用和推广,也阻碍了多模态技术在该地区的进一步发展。为了解决这个问题,需要开发专门针对东南亚语言和文化的视觉-语言数据集。
研究目的
本研究旨在填补东南亚在视觉-语言研究中的代表性空白,通过开发一个高质量、具有文化相关性的数据集——SEA-VL,来促进对代表性不足语言的更大包容性。SEA-VL数据集将涵盖东南亚地区的多种语言和文化,为AI模型的训练提供丰富的数据资源。通过该数据集,研究者和开发者可以构建出更能理解和表达东南亚文化的AI模型,从而推动视觉-语言技术在东南亚地区的应用和发展。
研究方法
数据收集方法
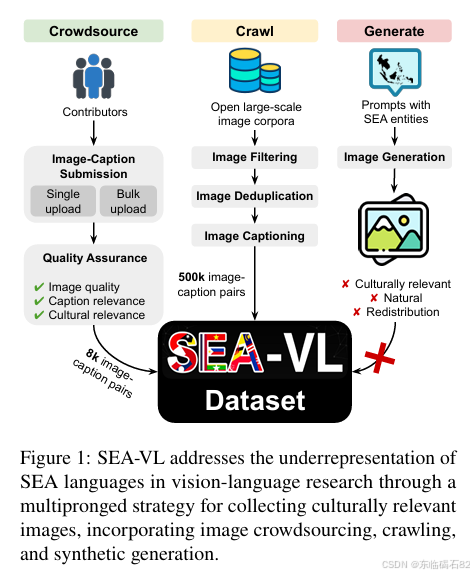
为了构建SEA-VL数据集,本研究采用了多种数据收集方法,包括众包、爬取和图像生成。
-
众包:通过邀请来自东南亚国家的贡献者参与,手工收集和提交具有文化相关性的图像。这种方法可以确保图像的高质量和文化相关性,但成本较高且耗时较长。
-
爬取:利用现有的大规模图像数据集,通过语义相似性过滤和去重等步骤,自动收集与东南亚文化相关的图像。这种方法成本较低且效率较高,但可能需要进一步的验证和清理工作。
-
图像生成:使用先进的生成式视觉模型(如Stable Diffusion、DALL-E等)来生成具有东南亚文化特色的图像。尽管这种方法在理论上具有巨大的潜力,但生成的图像在文化相关性和自然性方面仍存在挑战。
数据质量保证
为了确保SEA-VL数据集的质量和文化相关性,本研究采取了一系列严格的数据质量保证措施。在众包过程中,通过多轮验证和反馈机制来筛选高质量的图像。在爬取过程中,使用语义相似性过滤和去重技术来确保图像的多样性和文化相关性。在图像生成过程中,通过人工评估和调整模型参数来提高生成图像的质量。
数据集构建
基于收集到的图像数据,本研究构建了SEA-VL数据集。该数据集涵盖了东南亚地区的多种语言和文化,包括日常生活、地方产品、流行文化、地标建筑等多个方面。为了方便研究和开发者的使用,数据集还提供了详细的元数据和标注信息。
研究结果
数据集规模和文化覆盖
通过众包、爬取和图像生成等多种方法,本研究共收集了128万张与东南亚文化相关的图像,数据集规模远超其他现有数据集。这些图像涵盖了东南亚地区的11个国家,具有广泛的文化覆盖性和代表性。
数据质量和文化相关性
通过严格的数据质量保证措施,SEA-VL数据集在图像质量和文化相关性方面表现优异。众包过程中收集的图像经过多轮验证和反馈,确保了其高质量和文化相关性。爬取过程中使用的语义相似性过滤和去重技术有效提高了图像的多样性和文化覆盖性。尽管图像生成方面仍存在挑战,但通过人工评估和调整模型参数,生成的图像质量也在不断提高。
实验结果和分析
本研究还进行了一系列实验来评估不同数据收集方法的效果。实验结果表明,图像爬取在成本效益和时间效率方面优于众包,同时在文化相关性方面也表现出色(约85%)。然而,生成的图像在文化相关性和自然性方面仍需进一步提高。此外,本研究还评估了不同图像生成模型和图像描述模型在SEA-VL数据集上的性能,为未来的研究提供了有益的参考。
研究局限
尽管SEA-VL数据集在规模、质量和文化覆盖性方面表现出色,但仍存在一些局限性。
-
收集偏差和局限性:由于数据收集主要依赖于社交媒体平台和邮件列表等渠道,因此可能存在收集偏差和局限性。例如,人口较多、基础设施较好且与项目发起者联系更紧密的国家可能有更多的图像贡献者。此外,通过自我拍摄收集的图像可能只能代表更受欢迎的文化实践,而无法全面反映所有文化细节。
-
非全面的文化表示:东南亚文化的表示是一个复杂的循环,要捕捉每一种文化细微差别极具挑战性。尽管SEA-VL数据集在努力收集多样化的文化图像,但仍可能无法全面反映所有文化细节。这需要持续的努力和社区的支持来不断完善。
-
图像生成的局限性:尽管生成式视觉模型在图像生成方面取得了显著进展,但在生成具有文化相关性和自然性的图像方面仍存在挑战。生成的图像往往无法准确反映东南亚文化的细微传统和文化背景。
-
数据集的通用性:本研究不声称使用SEA-VL数据集训练的模型能够有效泛化到新兴的文化实践或代表性不足的传统中。这需要未来的研究来进一步探索和验证。
未来研究方向
针对上述研究局限,未来研究可以从以下几个方面进行改进和拓展:
-
优化数据收集方法:探索更高效、更全面的数据收集方法,以减少收集偏差和局限性。例如,可以考虑与当地的文化机构和组织合作,以获取更丰富、更多样化的文化图像。
-
提高图像生成质量:继续改进生成式视觉模型,提高其生成具有文化相关性和自然性图像的能力。这可能需要更深入的模型设计、更丰富的训练数据和更精细的调参过程。
-
增强文化表示的多样性:继续努力收集更多样化的文化图像,以更全面地反映东南亚地区的文化多样性。这可能需要持续的努力和社区的支持来不断完善数据集。
-
探索模型的泛化能力:研究如何使用SEA-VL数据集训练的模型来有效泛化到新兴的文化实践或代表性不足的传统中。这可能需要更深入的模型分析和更精细的调参过程。
-
推动多模态技术的发展:基于SEA-VL数据集,推动多模态技术在东南亚地区的应用和发展。例如,可以开发基于该数据集的视觉问答、图像描述等应用,以更好地满足当地用户的需求。
综上所述,本研究通过开发SEA-VL数据集,为东南亚地区的视觉-语言研究提供了宝贵的数据资源。未来研究将继续优化数据收集方法、提高图像生成质量、增强文化表示的多样性、探索模型的泛化能力并推动多模态技术的发展,以更好地促进AI技术在东南亚地区的应用和推广。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









