






摘要:视频扩散模型的发展揭示了一个重大挑战:巨大的计算需求。为了缓解这一挑战,我们注意到扩散的反向过程具有内在的熵减少特性。鉴于视频模态中的帧间冗余,在高熵阶段保持全帧率是不必要的。基于这一洞见,我们提出了TPDiff,一个统一的框架,用于提高训练和推理效率。通过将扩散过程分为几个阶段,我们的框架在扩散过程中逐步增加帧率,仅在最后阶段采用全帧率,从而优化计算效率。为了训练多阶段扩散模型,我们引入了一个专门的训练框架:阶段式扩散。通过求解在对齐数据和噪声下的分区概率流常微分方程(ODE),我们的训练策略适用于各种扩散形式,并进一步提高了训练效率。全面的实验评估验证了我们的方法的通用性,实验结果显示训练成本降低了50%,推理效率提高了1.5倍。Huggingface链接:Paper page,论文链接:2503.09566
研究背景和目的
研究背景
随着深度学习技术的不断发展,视频生成领域取得了显著突破。特别是视频扩散模型的出现,使得从文本描述或图像生成高质量视频成为可能。然而,视频扩散模型在训练过程中面临着巨大的计算挑战。传统的视频扩散模型需要在整个扩散过程中保持全帧率,这导致了极高的计算成本。同时,随着对长视频生成需求的增加,训练和推理成本也在相应增加,这严重阻碍了视频生成技术的进一步发展。
尽管已经有一些研究尝试通过级联框架、轻量级模型以及金字塔流等方法来提高视频扩散模型的训练和推理效率,但这些方法仍存在一定的局限性。例如,级联框架容易导致误差累积并显著增加推理时间;轻量级模型虽然计算效率高,但在处理大量数据和复杂模型时性能可能受限;金字塔流方法虽然在空间维度上取得了成功,但在时间维度上的应用仍有待探索,并且其自回归的生成方式显著降低了推理速度。
研究目的
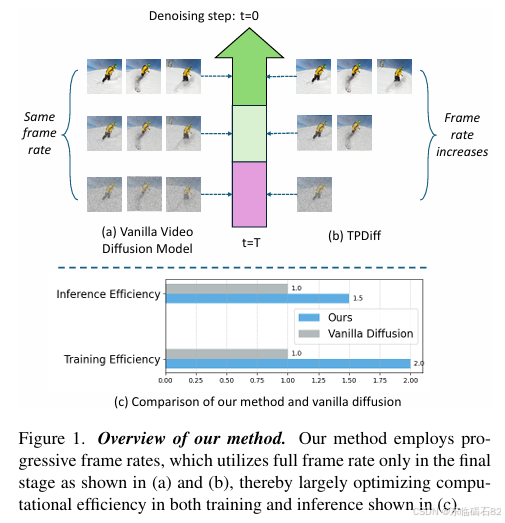
针对上述问题,本研究旨在提出一种新颖的视频扩散模型框架——TPDiff(Temporal Pyramid Video Diffusion Model),以显著提高视频扩散模型的训练和推理效率。通过利用视频中的帧间冗余特性,TPDiff在扩散过程中逐步增加帧率,仅在最后阶段采用全帧率,从而在不牺牲生成质量的前提下,大幅减少计算成本。此外,本研究还设计了一个专门的训练框架——阶段式扩散,以适用于不同类型的扩散形式,并进一步提高训练效率。
研究方法
初步概念
本研究首先介绍了去噪扩散隐式模型(DDIM)和流匹配(Flow Matching)等扩散模型的基本概念。DDIM通过在潜在空间中操作,将真实数据逐步转换为高斯噪声,并训练一个神经网络来预测添加的噪声。流匹配则通过学习一个速度场,将高斯噪声传输到真实数据的分布。
时序金字塔扩散
基于视频中的帧间冗余特性,本研究提出了时序金字塔视频扩散模型。该模型将扩散过程分为多个阶段,每个阶段采用不同的帧率。通过逐步增加帧率,模型能够在保持生成质量的同时,显著降低计算成本。具体而言,TPDiff将扩散过程分为K个阶段,每个阶段的帧率降低为原始帧率的1/2^(k-1),确保只有最后阶段采用全帧率。
训练策略
为了训练多阶段扩散模型,本研究引入了一种专门的训练框架——阶段式扩散。该框架通过求解对齐数据和噪声下的分区概率流常微分方程(ODE),实现了对不同扩散形式的统一处理。具体步骤如下:
-
数据噪声对齐:在添加噪声到视频之前,通过最小化视频噪声对的聚合距离,预先确定每个视频的目标噪声分布,从而确保数据噪声对齐。
-
阶段式目标计算:对于每个阶段,通过数据噪声对齐,计算该阶段的噪声目标,并利用ODE路径关系表达中间潜变量。
-
损失函数优化:利用计算得到的中间潜变量和噪声目标,计算相应的损失函数,并通过梯度下降法优化模型参数。
推理策略
在推理过程中,TPDiff采用标准的采样算法来求解每个阶段的反向ODE。为了确保阶段连续性,在完成一个阶段后,通过上采样和噪声注入来匹配下一个阶段的起点分布。
研究结果
实验设置
本研究在DDIM和流匹配两种扩散框架下实现了TPDiff,并基于MiniFlux和SD1.5两个图像模型,通过微调所有参数来扩展到视频模型(MiniFlux-vid和AnimateDiff)。实验数据集由从OpenVID1M中精选的约100k高质量文本视频对组成。
实验结果分析
-
推理效率:与基线模型相比,TPDiff在推理效率上实现了显著提升。具体来说,MiniFlux-vid和AnimateDiff的推理速度分别提高了1.71倍和1.49倍。
-
训练效率:TPDiff在训练效率上也表现出色,训练速度比基线模型快了2倍和2.13倍(在DDIM和流匹配框架下)。这主要得益于数据噪声对齐和较短的平均序列长度。
-
生成质量:尽管TPDiff在训练和推理效率上有所提升,但其生成质量并未受到损害。定量评估结果显示,TPDiff在大多数指标上均优于基线模型,表明其有效消除了传统视频扩散模型在时间建模上的冗余。
-
定性分析:定性比较结果显示,TPDiff生成的视频在语义准确性和运动幅度上均优于基线模型。例如,在“一个人在火星上谈话”的提示下,TPDiff能够更准确地生成指定动作,而基线模型则生成了与提示不符的摇头动作。
-
消融研究:消融研究表明,数据噪声对齐和重噪声推理策略对TPDiff的性能提升起到了关键作用。没有数据噪声对齐的模型生成的视频较为模糊,而没有重噪声推理策略的模型则会产生闪烁和模糊的结果。
研究局限
尽管TPDiff在提高视频扩散模型的训练和推理效率方面取得了显著成效,但仍存在一些局限性:
-
模型复杂度:尽管TPDiff通过阶段式扩散降低了计算成本,但整体模型复杂度仍然较高,对于计算资源有限的场景可能不适用。
-
扩展性:目前TPDiff主要应用于文本到视频的生成任务,其在其他视频生成任务(如视频到视频的转换、视频修复等)中的表现尚待验证。
-
长期依赖性:由于TPDiff在扩散过程中逐步增加帧率,可能在处理具有长期依赖性的视频内容时表现不佳。
未来研究方向
针对上述研究局限,未来可以从以下几个方面进行深入研究:
-
模型优化:进一步优化TPDiff的模型结构,降低模型复杂度,提高其在计算资源有限场景下的适用性。
-
任务扩展:探索TPDiff在其他视频生成任务中的应用,如视频到视频的转换、视频修复等,以验证其通用性和有效性。
-
长期依赖性建模:研究如何在TPDiff中引入长期依赖性建模机制,以更好地处理具有长期依赖性的视频内容。
-
实时生成:开发基于TPDiff的实时视频生成系统,以满足实际应用中的实时性需求。
-
多模态融合:探索将TPDiff与其他多模态技术(如音频、文本等)相结合,以实现更加丰富和多样的视频生成效果。
综上所述,TPDiff作为一种新颖的视频扩散模型框架,在提高训练和推理效率方面表现出了显著优势。然而,其仍存在一定的局限性,需要未来进一步研究和优化。通过不断探索和创新,相信TPDiff将在视频生成领域发挥更加重要的作用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









