






摘要:当前,图像生成与编辑方法主要将文本提示作为直接输入进行处理,而不对视觉构图和显式操作进行推理。我们提出了生成式思维链(Generation Chain-of-Thought,简称GoT),这是一种新颖范式,能够在输出图像之前,通过显式的语言推理过程实现生成与编辑。这种方法将传统的文本到图像生成与编辑转变为一种以推理为引导的框架,该框架能够分析语义关系和空间布局。我们定义了GoT的表述方式,并构建了大规模GoT数据集,其中包含超过900万个样本,这些样本带有详细的推理链,能够捕捉语义-空间关系。为了充分利用GoT的优势,我们实现了一个统一框架,该框架将用于推理链生成的Qwen2.5-VL与经过我们新型语义-空间引导模块增强的端到端扩散模型相结合。实验表明,我们的GoT框架在生成和编辑任务上均取得了优异性能,相较于基线方法有了显著提升。此外,我们的方法还支持交互式视觉生成,允许用户显式修改推理步骤,以精确调整图像。GoT为推理驱动的视觉生成与编辑开辟了新的方向,能够生成更符合人类意图的图像。为便于未来研究,我们将数据集、代码和预训练模型公开于https://github.com/rongyaofang/GoT。Huggingface链接:Paper page,论文链接:2503.10639
研究背景和目的
研究背景
随着人工智能技术的飞速发展,尤其是大型语言模型(LLMs)和多模态大型语言模型(MLLMs)的兴起,这些模型在理解和生成自然语言方面展现出了强大的能力。然而,在视觉内容生成领域,尽管扩散模型(Diffusion Models)已经取得了显著的进步,但现有的图像生成和编辑方法仍主要依赖于直接映射文本提示到图像内容,缺乏对视觉构图和显式操作的深入理解。这种局限性在处理复杂场景、需要精确空间布局和对象交互时尤为明显。相比之下,人类在构建场景时自然会考虑对象之间的关系和空间排列,而当前的图像生成系统却无法很好地模拟这一过程。
LLMs和MLLMs擅长复杂的推理任务,包括分析语义结构、推断关系、将视觉概念与详细上下文相结合等。这种先进的推理能力与当前图像生成系统中有限的推理能力之间存在差距,引发了如何将LLMs的推理机制整合到视觉生成和编辑中的关键问题。尽管先前的研究尝试利用LLMs进行图像生成,但大多数方法要么仅将LLMs作为文本编码器以增强提示解释,要么开发多模态LLMs以统一理解和生成,但这些方法都没有充分利用LLMs的推理能力来真正融合语言推理与视觉生成。此外,基于布局的方法虽然将LLMs用于布局规划,但将规划与生成作为单独的阶段,而没有在整个端到端过程中整合推理。
研究目的
针对上述问题,本研究旨在提出一种新颖的图像生成和编辑范式——生成链式思考(Generation Chain-of-Thought,GoT),该范式能够在输出图像之前通过显式的语言推理过程来指导视觉生成和编辑。通过整合LLMs的推理能力与扩散模型的高保真生成质量,GoT旨在实现以下目标:
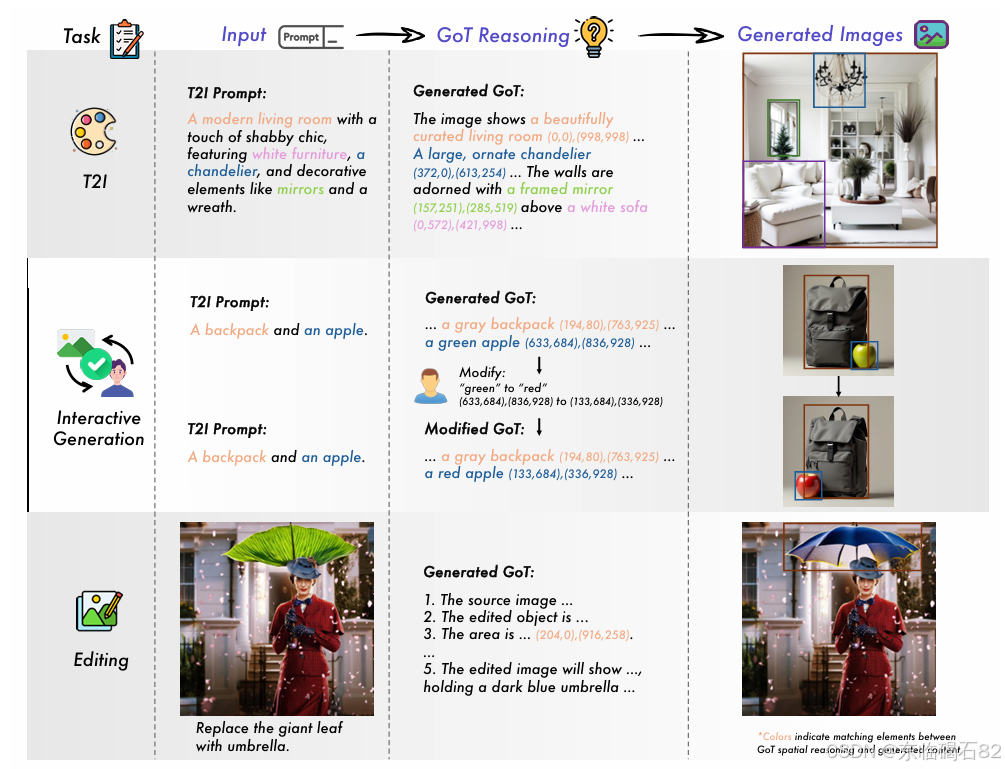
- 增强图像生成和编辑的推理能力:通过引入显式的语义和空间推理链,GoT能够为图像生成和编辑任务提供精确的对象布局、关系和属性控制。
- 提高生成图像的质量和编辑的准确性:通过显式地规划场景构图和对象交互,GoT能够生成更符合人类意图的图像,并在编辑任务中更准确地执行用户的指令。
- 实现交互式视觉生成:允许用户通过直接修改推理链来定制他们的文本到图像生成过程,从而提供一种可解释且可操作的界面。
研究方法
数据集构建
为了实现GoT范式,本研究首先构建了一个大规模的训练数据集,该数据集包含详细的推理链,这些推理链与视觉内容对齐,并捕捉了语义关系和空间配置。数据集的构建过程涉及以下步骤:
- 自动化数据创建管道:利用先进的LLMs和MLLMs设计任务特定的注释管道,以生成高质量的注释。对于文本到图像生成,使用Qwen2-VL生成简洁的提示和详细的视觉描述,然后利用Qwen2.5进行对象实体提取和空间关系建立。对于图像编辑,使用Qwen2-VL生成源图像和目标图像的全面描述,并通过边界框精确定位编辑区域。
- 数据收集和过滤:从多个来源收集图像数据,包括Laion-Aesthetics、JourneyDB和FLUX等,并对数据进行过滤和清理,以确保数据的质量和多样性。
- 注释和验证:对收集到的图像数据进行详细的注释,包括生成推理链、对象边界框和属性描述等。同时,对注释结果进行验证和修正,以确保数据的准确性。
GoT框架设计
GoT框架是一个统一的端到端方法,将推理引导的过程嵌入到视觉生成和编辑任务中。该框架包含两个主要组件:
- 语义-空间感知的MLLM:作为推理引擎,处理生成和编辑任务。该MLLM生成包含空间信息的结构化推理链,并通过语义和空间指导来引导扩散模型的生成过程。
- 多指导的扩散生成模块:基于SDXL架构,并融入了一种创新的三重指导机制,该机制通过语义理解、空间感知和参考知识来增强扩散模型。其中,语义指导路径通过交叉注意力层将MLLM生成的嵌入传递到扩散模型中,以提供更精确的语义控制;空间指导路径通过提取推理链中的坐标信息来创建颜色编码的掩码,并通过VAE编码器产生空间潜在特征,以实现对生成和编辑任务的空间控制;参考图像指导路径则处理源图像或参考图像以提取视觉特征,并在生成和编辑任务中提供无缝过渡。
训练过程
训练过程采用两阶段方法:首先在LAHR-GoT、JourneyDB-GoT和OmniEdit-GoT数据集上进行预训练(60,000步),然后在FLUX-GoT、OmniEdit-GoT和SEED-Edit-MultiTurn-GoT上进行微调(10,000步)。在训练过程中,联合优化MLLM的GoT交叉熵令牌损失和扩散模型的MSE损失,并采用低秩适应(LoRA)来高效地更新Qwen2.5-VL解码器的参数。
研究结果
定量结果
在文本到图像生成任务上,GoT框架在GenEval基准测试上取得了最高的整体分数(0.64),特别是在单个对象(0.99)、计数任务(0.67)和颜色任务(0.85)上表现出色。与冻结文本编码器方法和LLM/MLLM增强方法相比,GoT框架在各项指标上均表现出更均衡的性能,验证了引入显式推理机制对组合生成能力的增强作用。
在图像编辑任务上,GoT框架在Emu-Edit基准测试上的CLIP-I(0.864)和CLIP-T(0.276)指标上均取得了最高分数,并在ImagenHub和Reason-Edit基准测试上也表现出色。特别是在需要语义-空间推理的复杂编辑场景中,GoT框架展现出了优越的性能。
定性结果
在文本到图像生成方面,GoT框架能够基于输入提示有效地规划对象布局,并生成高度对齐和美观的图像。在图像编辑方面,GoT框架能够准确地识别和定位通过间接描述引用的对象,有效地处理复杂的空间指令,并在多步骤编辑操作中表现出色。
消融研究
消融研究验证了GoT框架中不同组件对性能的影响。添加GoT推理链到基线模型能够增强LLM的语义指导能力,引入语义-空间指导模块(SSGM)则进一步提高了模型性能,特别是在图像编辑任务中。完整的GoT框架在预训练阶段取得了最高的分数,证明了延长预训练和完整模型设计的显著益处。
研究局限
尽管GoT框架在图像生成和编辑任务上取得了显著的性能提升,但仍存在一些局限性:
- 数据集限制:虽然构建了大规模的训练数据集,但数据的多样性和复杂性仍有待提高。特别是对于一些罕见或极端的视觉场景,数据集的覆盖可能不足。
- 模型复杂性:GoT框架融合了多个先进的模型组件,导致模型复杂度较高。这可能导致在资源受限的环境下部署模型时面临挑战。
- 用户交互体验:虽然GoT框架实现了交互式视觉生成,但用户界面的友好性和易用性仍有待提升。特别是在处理复杂编辑指令时,用户可能需要一定的学习成本。
未来研究方向
- 扩大数据集规模和多样性:继续收集更多样化和复杂的视觉数据,以进一步提高模型的泛化能力和鲁棒性。特别是针对一些罕见或极端的视觉场景,需要构建专门的数据集进行训练。
- 优化模型架构和降低复杂性:探索更高效的模型架构和训练方法,以降低GoT框架的复杂性和计算成本。例如,可以采用模型压缩和加速技术来减小模型大小并提高推理速度。
- 提升用户交互体验:开发更直观和易用的用户界面,以降低用户的学习成本并提高交互效率。同时,可以引入自然语言处理技术来更好地理解用户的编辑意图和需求。
- 拓展应用场景:将GoT框架应用于更多的视觉生成和编辑场景,如视频生成、3D模型生成等。通过不断拓展应用场景,可以进一步验证GoT框架的通用性和实用性。
此外,还可以探索将GoT框架与其他先进技术相结合的可能性,如自监督学习、强化学习等。通过整合多种技术手段,可以进一步提升GoT框架的性能和效果,为视觉生成和编辑领域带来更多的创新和突破。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









