






摘要:长上下文自回归建模在语言生成方面取得了显著进展,但视频生成仍难以充分利用扩展的时间上下文。为了探究长上下文视频建模,我们引入了帧自回归(Frame AutoRegressive, FAR),这是一种用于视频自回归建模的强大基线方法。正如语言模型学习标记(token)之间的因果依赖关系(即标记自回归,Token AR)一样,FAR模型学习连续帧之间的时间因果依赖关系,其收敛效果优于标记自回归和视频扩散变换器。在FAR的基础上,我们观察到长上下文视觉建模由于视觉冗余而面临挑战。现有的旋转位置编码(Rotary Positional Encoding, RoPE)缺乏对远程上下文的有效时间衰减,无法很好地外推到长视频序列。此外,由于视觉标记的增长速度远快于语言标记,在长视频上进行训练的计算成本很高。为了解决这些问题,我们提出了平衡局部性和长程依赖性的方法。我们引入了FlexRoPE,这是一种测试时技术,它为RoPE添加了灵活的时间衰减,从而能够外推到16倍更长的视觉上下文。此外,我们还提出了长短时上下文建模方法,其中高分辨率的短时上下文窗口确保了细粒度的时间一致性,而无限的长时上下文窗口则使用较少的标记来编码长程信息。通过这种方法,我们可以在可管理的标记上下文长度内对长视频序列进行训练。我们证明,FAR在短视频和长视频生成方面都取得了最先进的性能,为视频自回归建模提供了一个简单而有效的基线方法。Huggingface链接:Paper page,论文链接:2503.19325
研究背景和目的
研究背景
随着人工智能技术的飞速发展,自然语言处理和计算机视觉领域取得了显著进展。长上下文自回归建模在语言生成方面已经展现出了强大的能力,如扩展对话、链式思维推理、上下文学习和检索增强生成等应用。然而,尽管这些进展令人瞩目,视频生成领域在利用扩展时间上下文方面仍然面临诸多挑战。视频生成任务相较于语言生成更为复杂,因为它需要同时处理空间和时间维度的信息。
现有的视频生成方法主要分为两大类:视频扩散模型和标记自回归模型。视频扩散模型通过逐步滑动窗口的方式生成长视频,但在有效利用早期上下文方面存在困难。标记自回归模型虽然借鉴了大型语言模型的范式,将连续帧量化为离散标记并学习标记之间的因果依赖关系,但由于单向视觉标记建模和信息损失问题,其生成质量仍然不如视频扩散变换器。此外,混合自回归-扩散模型虽然在图像和视频生成中得到了应用,但它们在训练和推理过程中观察到的上下文存在差异,这限制了模型的性能。
为了克服这些挑战,本文引入了帧自回归(FAR)模型,旨在专门为视频自回归建模设计一种强大且有效的基线方法。FAR模型不仅能够学习连续帧之间的时间因果依赖关系,还能够在每个帧内实现全注意力建模,从而在短视频和长视频生成方面表现出色。
研究目的
本文的研究目的主要包括以下几点:
- 引入FAR模型:作为视频自回归建模的强大基线,FAR模型通过帧级流匹配目标进行训练,能够捕捉连续帧之间的时间因果依赖关系。
- 解决训练和推理差异:针对混合自回归-扩散模型在训练和推理过程中观察到的上下文差异问题,本文提出使用随机干净上下文进行训练,以提高模型的收敛效果和推理性能。
- 探索长上下文视频建模:本文研究了长上下文视频建模中的两个常见问题:测试时的时间外推和长序列训练。针对这些问题,本文提出了FlexRoPE和长短时上下文建模方法,以平衡局部性和长程依赖性。
- 实现高效视频生成:通过引入FlexRoPE和长短时上下文建模,本文旨在实现高效的长视频训练和生成,同时保持高质量的生成效果。
研究方法
FAR模型框架
FAR模型基于扩散变换器构建,其关键架构差异在于注意力机制。对于每个帧,FAR模型在帧级应用因果注意力,同时保持帧内的全注意力。这种因果时空注意力机制使得FAR模型能够在生成过程中有效利用先前的上下文帧。
在训练过程中,FAR模型首先使用预训练的变分自编码器(VAE)将视频序列压缩到潜在空间。然后,通过独立采样每个帧的时间步,并使用线性插值在清洁潜在和采样噪声之间构建连续轨迹。接着,FAR模型应用帧级流匹配目标进行学习,优化可学习时间依赖的速度场。
随机干净上下文
为了解决训练和推理过程中观察到的上下文差异问题,本文提出了随机干净上下文训练方法。在训练过程中,FAR模型随机替换一部分噪声帧为相应的清洁上下文帧,并为这些帧分配一个超出流匹配时间步调度器的独特时间步嵌入。这些清洁上下文帧在计算损失时被排除在外,但通过后续使用它们作为上下文的帧进行隐式学习。在推理过程中,这个独特的时间步嵌入引导模型有效利用清洁上下文帧。
FlexRoPE
针对长上下文视觉建模中的时间外推问题,本文提出了FlexRoPE方法。FlexRoPE在RoPE的基础上添加了灵活的时间衰减,通过在测试时应用线性偏差来控制时间衰减。这种方法能够在抑制远程上下文中的冗余视觉信息的同时,仍然允许模型使用RoPE捕捉长程依赖关系。
长短时上下文建模
为了高效地在长视频上进行训练,本文提出了长短时上下文建模方法。该方法维护一个高分辨率的短时上下文窗口来学习细粒度的时间一致性,同时使用一个低分辨率的长时上下文窗口并采用积极的块划分来减少上下文标记的数量。在训练过程中,短时上下文窗口固定为n帧,并从范围[0, m-n]中随机采样长时上下文帧,其中m是数据的最大序列长度。
研究结果
定量比较
- 短视频生成:在UCF-101和BAIR数据集上,FAR模型在短视频生成方面取得了显著优于其他方法的结果。无论是在无条件视频生成还是有条件视频生成中,FAR模型都表现出了更高的SSIM、PSNR和更低的LPIPS、FVD指标。
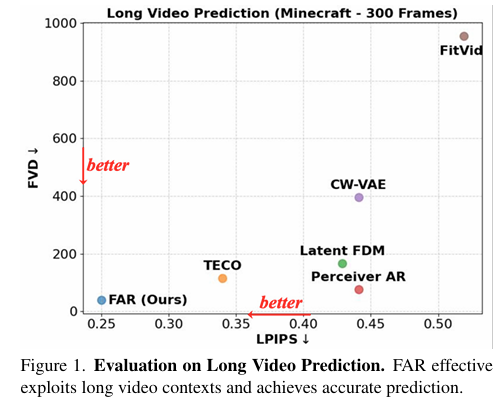
- 长视频预测:在Minecraft和DMLab数据集上,FAR模型在长上下文视频建模方面也表现出了优异的性能。通过长短时上下文建模方法,FAR模型能够在不增加过多计算成本的情况下,实现更低的预测误差(即LPIPS)和更高的视频质量。
定性比较
在长视频预测方面,FAR模型能够更有效地利用提供的上下文,并生成与真实视频更为接近的预测结果。通过可视化比较,可以清晰地看到FAR模型在长时间预测中保持了更好的一致性和准确性。
消融研究
- 随机干净上下文:消融研究表明,使用随机干净上下文进行训练的FAR模型在视频预测任务中取得了显著的性能提升。这表明随机干净上下文方法能够有效地解决训练和推理过程中的上下文差异问题。
- FlexRoPE:与RoPE和ALiBi方法相比,FlexRoPE在16倍时间外推任务中取得了更好的性能。FlexRoPE能够有效地抑制远程上下文中的冗余视觉信息,并实现更准确的时间外推。
- 长短时上下文分辨率和窗口大小:消融研究还探讨了长短时上下文分辨率和短时上下文窗口大小对模型性能的影响。实验结果表明,适当的长短时上下文分辨率和短时上下文窗口大小能够在计算效率和性能之间取得良好的平衡。
研究局限
尽管FAR模型在短视频和长视频生成方面都取得了优异的性能,但本研究仍存在一些局限性:
- 缺乏大规模实验:尽管FAR模型展示了巨大的潜力,但本研究仍缺乏在百万级文本到视频生成数据集上的大规模训练实验。这限制了FAR模型在实际应用中的广泛性和可靠性。
- 数据集限制:由于可用数据集的限制,本研究仅在最多300帧(约20秒)的视频上进行了实验,未能充分探究FAR模型在分钟级视频上的能力。这限制了FAR模型在处理更长视频序列时的表现。
未来研究方向
针对上述研究局限,未来的研究工作可以从以下几个方面展开:
- 扩大实验规模:将FAR模型扩展到更大规模的数据集上进行训练,以评估其在处理更复杂和更长视频序列时的性能。这将有助于提升FAR模型的实用性和泛化能力。
- 构建更长视频数据集:模拟构建分钟级甚至更长的视频数据集,以更好地评估FAR模型的长上下文建模能力。这将有助于推动视频生成技术在实际应用中的进一步发展。
- 探索其他应用场景:除了视频生成任务外,还可以探索FAR模型在其他序列视觉建模任务中的应用潜力,如图像序列建模等。这将有助于拓展FAR模型的应用范围和价值。
综上所述,本文通过引入FAR模型并提出FlexRoPE和长短时上下文建模方法,在短视频和长视频生成方面都取得了显著进展。然而,为了进一步提升FAR模型的性能和应用价值,未来的研究工作仍需不断努力和探索。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









