






摘要:多步骤空间推理涉及跨多个顺序步骤理解和推理空间关系,这对于解决复杂的现实世界应用至关重要,如机器人操作、自主导航和自动化装配。为了评估当前多模态大型语言模型(MLLMs)在获取这一基本能力方面的表现,我们引入了LEGO-Puzzles,这是一个可扩展的基准测试,旨在通过基于乐高(LEGO)的任务来评估MLLMs的空间理解和顺序推理能力。LEGO-Puzzles包含1100个精心挑选的视觉问答(VQA)样本,涵盖11个不同的任务,从基本的空间理解到复杂的多步骤推理。基于LEGO-Puzzles,我们对最先进的MLLMs进行了全面评估,并发现了它们在空间推理能力方面的显著局限性:即使是最强大的MLLMs,也只能回答大约一半的测试用例,而人类参与者的准确率超过90%。除了VQA任务外,我们还评估了MLLMs根据装配说明生成乐高图像的能力。我们的实验表明,只有Gemini-2.0-Flash和GPT-4o展现出有限的遵循这些指令的能力,而其他MLLMs要么复制输入图像,要么生成完全无关的输出。总体而言,LEGO-Puzzles揭示了现有MLLMs在空间理解和顺序推理能力方面的关键不足,并强调了进一步推进多模态空间推理的必要性。Huggingface链接:Paper page,论文链接:2503.19990
研究背景和目的
研究背景
随着人工智能技术的不断进步,多模态大型语言模型(MLLMs)在理解和生成文本、图像、音频和视频等多种模态信息方面取得了显著进展。这些模型不仅能够处理单个模态的数据,还能在多个模态之间进行交互和融合,从而展现出强大的跨模态理解能力。然而,尽管MLLMs在单模态和多模态任务上取得了令人瞩目的成就,它们在空间理解和顺序推理方面仍存在显著挑战。空间推理,特别是多步骤空间推理,是人工智能领域的一个核心难题,对于解决复杂的现实世界应用至关重要,如机器人操作、自动驾驶和自动化装配等。
这些应用不仅要求模型能够理解和感知空间关系,还需要模型能够在多个顺序步骤中进行推理和决策。然而,现有的MLLMs在空间理解和顺序推理方面的能力尚显不足。它们往往难以准确捕捉空间关系中的细微差别,特别是在处理涉及多个步骤的复杂空间推理任务时,更是显得力不从心。这种局限性严重制约了MLLMs在需要高精度空间理解和顺序推理的领域中的应用。
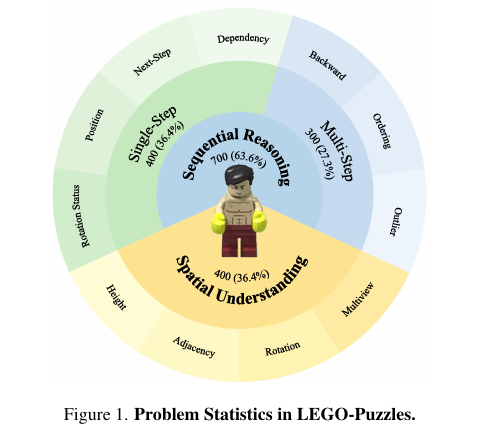
为了填补这一研究空白,评估并提升MLLMs在空间理解和顺序推理方面的能力,本研究引入了LEGO-Puzzles基准测试。LEGO-Puzzles是一个基于乐高积木构建的可扩展基准测试,旨在通过一系列基于乐高的任务来全面评估MLLMs的空间理解和顺序推理能力。
研究目的
本研究的主要目的包括:
-
评估现有MLLMs的空间理解和顺序推理能力:通过LEGO-Puzzles基准测试,对一系列最先进的MLLMs进行全面评估,揭示它们在空间理解和顺序推理方面的表现和不足。
-
揭示MLLMs在空间推理方面的局限性:深入分析MLLMs在处理多步骤空间推理任务时的表现,识别其存在的主要问题和挑战,为未来的模型改进提供方向。
-
推动多模态空间推理技术的发展:通过本研究,强调多模态空间推理技术的重要性,并鼓励研究人员和开发者进一步探索和改进这一领域的技术,以提升MLLMs在复杂现实世界应用中的实用性和可靠性。
研究方法
数据集构建
为了构建LEGO-Puzzles基准测试,研究团队首先收集了大量开源的乐高积木构建指南。这些指南包含了详细的步骤说明、可视化图像以及每个步骤所需的乐高积木。接着,研究团队利用这些指南生成了1100个精心挑选的视觉问答(VQA)样本,涵盖了11个不同的任务类别,从基本的空间理解到复杂的多步骤推理。
在数据生成过程中,研究团队采用了多种策略来确保数据的质量和一致性。首先,他们使用专业的渲染软件将乐高积木构建指南转换为PDF文件,并调整渲染设置以生成具有不同角度和光照条件的逼真图像。其次,他们设计了一系列任务特定的模板来生成问题和答案,确保每个样本都符合特定的任务要求。最后,他们实施了严格的质量控制流程,包括人工审查和交叉验证,以确保数据的准确性和可靠性。
模型评估
在模型评估阶段,研究团队选择了一系列最先进的MLLMs作为评估对象,包括开源模型和专有模型。他们采用零样本设置对所有模型进行了全面评估,以比较它们在处理不同任务时的表现。评估指标主要包括准确率、人类专家评估的相似性和指令遵循度等。
为了更深入地了解模型在处理多步骤顺序推理任务时的表现,研究团队还设计了一个细粒度的顺序推理任务——Next-k-Step。该任务要求模型在给定当前乐高对象和目标乐高对象的情况下,通过逐步添加k个额外的乐高积木来识别正确的乐高对象。通过调整k的值,研究团队可以评估模型在处理不同长度推理步骤时的表现。
研究结果
空间理解和顺序推理能力评估
基于LEGO-Puzzles基准测试的评估结果显示,现有MLLMs在空间理解和顺序推理方面的能力存在显著局限性。即使是最强大的模型,如Gemini-2.0-Flash和GPT-4o,也只能回答大约一半的测试用例,而人类参与者的准确率超过90%。这表明MLLMs在处理复杂空间关系和顺序推理任务时仍存在较大差距。
具体来说,在基本空间理解任务中,大多数模型在高度识别任务上的表现尤其糟糕,准确率普遍低于随机猜测。这表明MLLMs在处理涉及2D和3D视角转换的空间关系时存在困难。在顺序推理任务中,模型在单步骤推理任务上的表现相对较好,但在多步骤推理任务上的表现则显著下降。这表明MLLMs在处理需要跨多个步骤进行推理和决策的任务时存在挑战。
图像生成能力评估
除了VQA任务外,研究团队还评估了MLLMs根据装配说明生成乐高图像的能力。实验结果显示,只有Gemini-2.0-Flash和GPT-4o展现出有限的遵循指令生成图像的能力,而其他模型要么复制输入图像,要么生成完全无关的输出。这表明MLLMs在将空间理解和顺序推理能力转化为实际图像生成任务时仍存在显著挑战。
Next-k-Step任务评估
在Next-k-Step任务的评估中,研究团队发现随着推理步骤的增加,模型的准确率普遍下降。这表明MLLMs在处理需要跨多个步骤进行推理的任务时容易积累错误,导致最终预测结果的不一致性。此外,他们还发现Chain-of-Thought(CoT)提示策略在单步骤推理任务中能够显著提升模型的表现,但在多步骤推理任务中的效果有限。这表明现有的CoT策略在处理复杂多步骤推理任务时可能并不适用。
研究局限
尽管本研究在评估MLLMs的空间理解和顺序推理能力方面取得了一定进展,但仍存在一些局限性。首先,LEGO-Puzzles基准测试主要基于乐高积木构建任务,可能无法全面反映MLLMs在所有类型空间推理任务中的表现。其次,研究团队仅评估了有限数量的MLLMs,可能无法全面揭示现有模型在空间推理方面的局限性和挑战。此外,由于评估是在零样本设置下进行的,模型可能无法充分利用其训练数据中的相关知识来提升性能。
未来研究方向
基于本研究的结果和局限性,未来研究可以从以下几个方面展开:
-
扩展基准测试:开发更广泛、更多样化的基准测试来评估MLLMs的空间理解和顺序推理能力。这些基准测试可以涵盖不同类型的空间推理任务,如空间导航、物体操作等,以更全面地反映模型在实际应用中的表现。
-
改进模型架构和训练方法:针对MLLMs在空间推理方面的局限性,研究新的模型架构和训练方法以提升其性能。例如,可以探索将3D坐标信息嵌入到语言表示中的方法,或者开发能够显式建模空间关系的神经网络架构。
-
结合人类知识和常识推理:引入人类知识和常识推理来增强MLLMs的空间理解和顺序推理能力。例如,可以利用知识图谱或常识数据库来提供额外的背景信息和先验知识,帮助模型更好地理解和推理空间关系。
-
多模态融合与交互:进一步研究多模态信息的融合与交互机制,以提升MLLMs在处理复杂多模态任务时的表现。例如,可以探索如何更有效地结合视觉、听觉和文本信息来提高模型的空间推理能力。
-
实际应用探索:将MLLMs的空间推理能力应用于实际场景中,如机器人操作、自动驾驶和智能制造等。通过在实际应用中的测试和验证,不断优化和提升模型的性能和可靠性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









