






摘要:我们提出了Kimi-VL,这是一种高效的开源专家混合(MoE)视觉语言模型(VLM),它提供了先进的多模态推理、长上下文理解和强大的代理能力,同时在其语言解码器(Kimi-VL-A3B)中仅激活28亿个参数。 Kimi-VL 在具有挑战性的领域表现出色:作为通用 VLM,Kimi-VL 在多轮代理任务(例如 OSWorld)中表现出色,与旗舰模型相匹配。 此外,它在各种具有挑战性的视觉语言任务中表现出卓越的能力,包括大学水平的图像和视频理解、OCR、数学推理和多图像理解。 在比较评估中,它有效地与GPT-4o-mini、Qwen2.5-VL-7B和Gemma-3-12B-IT等尖端高效VLM竞争,同时在几个关键领域超越了GPT-4o。 Kimi-VL在处理长文本和清晰感知方面也有所进步。 Kimi-VL具有128K的扩展上下文窗口,可以处理各种长输入,在LongVideoBench上取得了64.5分的优异成绩,在MMLongBench-Doc上取得了35.1分的优异成绩。 其原生分辨率视觉编码器MoonViT进一步使其能够看到和理解超高分辨率的视觉输入,在InfoVQA上达到83.2,在ScreenSpot-Pro上达到34.5,同时保持了常见任务的较低计算成本。 在Kimi-VL的基础上,我们引入了一种先进的长期思考变体:Kimi-VL-Thinking。 该模型通过长链思维(CoT)监督微调(SFT)和强化学习(RL)开发而成,具有强大的长视野推理能力。 它在MMMU上获得了61.7分,在MathVision上获得了36.8分,在MathVista上获得了71.3分,同时保持了紧凑的2.8B激活的LLM参数,为高效的多模态思维模型设定了新的标准。 代码和模型可以在https://github.com/MoonshotAI/Kimi-VL上公开访问。Huggingface链接:,论文链接:2504.07491
研究背景和目的
研究背景
随着人工智能的快速发展,人们对AI助手的期望已经超越了传统的仅依赖语言的交互方式,更加符合我们这个世界固有的多模态特性。为了更好地理解和满足这些期望,新一代原生多模态模型应运而生,如GPT-4o(OpenAI等,2024)和Google Gemini(Gemini团队等,2024),它们具备无缝感知和解释视觉输入的能力,同时处理语言任务。最近,以OpenAI o1系列(OpenAI,2024)和Kimi k1.5(K.Team等,2025)为代表的高级多模态模型进一步推动了这一领域的边界,融入了更复杂的推理能力。
然而,开源社区在大型视觉语言模型(VLM)的发展方面显著落后于仅依赖语言的模型,特别是在可扩展性、计算效率和高级推理能力方面。尽管仅依赖语言的模型DeepSeek R1(DeepSeek-AI,D.Guo等,2025)已经利用了高效且可扩展的专家混合(MoE)架构,并支持复杂的长期链式思维(CoT)推理,但大多数最近的开源VLM,如Qwen2.5-VL(Bai等,2025)和Gemma-3(Gemma团队等,2025),仍然依赖于密集架构,并且不支持长期CoT推理。早期对基于MoE的视觉语言模型的探索,如DeepSeek-VL2(Zhiyu Wu等,2024)和Aria(D.Li等,2024),在其他关键维度上表现出局限性。结构上,这些模型仍然采用相对传统的固定大小视觉编码器,阻碍了它们对不同视觉输入的适应性。从能力角度来看,DeepSeek-VL2支持的上下文长度有限(4K),而Aria在细粒度视觉任务上表现不佳。此外,它们都不支持长期思考能力。
因此,迫切需要一种开源VLM,该模型有效地集成了结构创新、稳定能力和通过长期思考增强的推理能力。
研究目的
本研究旨在提出Kimi-VL,一种为开源社区设计的视觉语言模型。结构上,Kimi-VL结合了我们的Moonlight(J.Liu等,2025a)MoE语言模型,该模型仅激活28亿个参数(总共160亿个参数),以及一个4亿参数的原生分辨率MoonViT视觉编码器。在能力方面,Kimi-VL能够稳健地处理各种任务(如细粒度感知、数学、大学水平问题、OCR、代理等)和广泛的输入形式(如单图像、多图像、视频、长文档等)。具体来说,本研究旨在实现以下目标:
- 开发一种高效的多模态模型,能够在处理多模态输入时仅激活有限数量的参数。
- 使模型具备强大的多模态推理能力,能够在多种基准测试中表现出色。
- 通过长期CoT激活和强化学习(RL),进一步提升模型的长视野推理能力。
- 提供开源的代码和模型,促进社区的研究和发展。
研究方法
模型架构
Kimi-VL的架构由三部分组成:一个原生分辨率视觉编码器(MoonViT)、一个多层感知机(MLP)投影器和一个MoE语言模型,如图3所示。
-
MoonViT:设计用于以原生分辨率处理图像,消除了对复杂子图像分割和拼接操作的需求。它采用NaViT(Dehghani等,2023)中的打包方法,将图像分为补丁,展平并顺序连接成一维序列。这些预处理操作使MoonViT能够与语言模型共享相同的核心计算操作和优化,如由FlashAttention(Dao等,2022)支持的变长序列注意力机制,从而确保对不同分辨率图像的非妥协训练吞吐量。
-
MLP投影器:使用两层MLP来桥接视觉编码器(MoonViT)和LLM。首先,通过像素混洗操作压缩MoonViT提取的图像特征的空间维度,然后在空间域中进行2×2下采样,并相应地扩展通道维度。接下来,将像素混洗后的特征输入到两层MLP中,将其投影到LLM嵌入的维度。
-
MoE语言模型:利用Moonlight模型(J.Liu等,2025a),一个具有28亿个激活参数、160亿个总参数的MoE语言模型。对于实现,我们从Moonlight预训练阶段的中间检查点开始,该检查点已经处理了5.2T纯文本数据并激活了8192个令牌(8K)的上下文长度。然后,继续使用由纯文本数据和多种模态数据组成的联合配方进行预训练,总共消耗了2.3T令牌。
优化器
使用增强的Muon优化器(J.Liu等,2025b)进行模型优化。与原始Muon优化器(Jordan等,2024)相比,添加了权重衰减并仔细调整了每个参数的更新比例。此外,还开发了一个遵循ZeRO-1(Rajbhandari等,2020)优化策略的Muon分布式实现,该策略实现了最优的内存效率和降低的通信开销,同时保留了算法的数学性质。
预训练阶段
Kimi-VL的预训练包括四个阶段,总共消耗了4.4T令牌,如图4和表1所示:
- ViT训练阶段:单独训练MoonViT,以建立一个强大的原生分辨率视觉编码器。
- 联合预训练阶段:使用纯文本数据和多种模态数据的组合进行联合训练,同时增强模型的语言和多模态能力。
- 联合冷却阶段:在预训练阶段之后,进行一个多模态冷却阶段,其中仅更新视觉编码器和MLP投影器,以进一步提高模型的视觉理解能力。
- 联合长上下文激活阶段:将模型的上下文长度从8192(8K)扩展到131072(128K),以增强模型对长上下文的理解能力。
后训练阶段
- 联合监督微调(SFT):使用指令格式的SFT数据对Kimi-VL的基础模型进行微调,以增强其遵循指令和进行对话的能力。
- 长期CoT监督微调:通过长期CoT监督微调,进一步提升模型的长视野推理能力。
- 强化学习(RL):采用在线策略镜像下降作为RL算法,通过迭代细化策略模型πθ来提高其解决问题的准确性。
研究结果
多模态推理和长上下文理解
Kimi-VL在多个基准测试中表现出色,证明了其在多模态推理和长上下文理解方面的强大能力。
-
大学水平学术问题:在MMMU验证集上,Kimi-VL取得了57.0%的分数,优于DeepSeek-VL2(51.1%),并与Qwen2.5-VL-12B(59.6%)相当。
-
一般视觉能力:在MMBench-EN-v1.1上,Kimi-VL达到了83.1%的准确率,优于所有比较的高效VLM,并与GPT-4o相当。
-
多图像推理:在BLINK基准测试上,Kimi-VL取得了57.3%的分数,优于Qwen2.5-VL-7B(56.4%)、GPT-4o-mini(53.6%)和Gemma3-12B-IT(50.3%)。
-
数学推理:在MathVista基准测试上,Kimi-VL取得了68.7%的分数,优于所有比较模型,包括GPT-4o(63.8%)和Qwen2.5-VL-7B(68.2%)。
-
OCR和文档理解:在InfoVQA上,Kimi-VL取得了83.2%的准确率,优于GPT-4o(80.7%)和DeepSeek-VL2(78.1%)。在OCRBench上,Kimi-VL取得了86.7%的分数,优于所有比较模型。
-
代理接地和多轮代理交互:在ScreenSpot-V2上,Kimi-VL达到了92.0%的准确率;在极其困难的ScreenSpot-Pro上,取得了34.5%的分数。在OSWorld上,Kimi-VL达到了8.22%的通过率,优于GPT-4o(5.03%)。
-
长文档和长视频理解:在MMLongBench-Doc上,Kimi-VL取得了34.7%的准确率,优于GPT-4o-mini(29.0%)和Qwen2.5-VL-7B(29.6%)。在LongVideoBench上,Kimi-VL取得了64.5%的分数,优于所有比较的高效VLM。
长期思考变体:Kimi-VL-Thinking
通过长期CoT监督和RL训练得到的Kimi-VL-Thinking模型在多个基准测试上表现出色,展示了强大的长视野推理能力。
-
MMMU:在MMMU验证集上,Kimi-VL-Thinking取得了61.7%的分数,优于GPT-4o-mini(60.0%)和Qwen2.5-VL-7B(58.6%)。
-
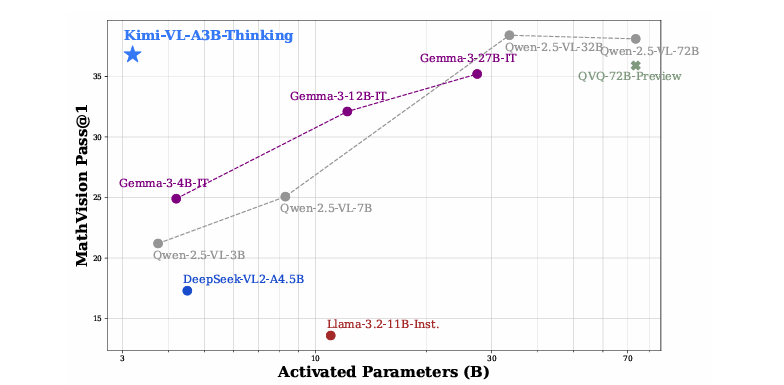
MathVision:在MathVision基准测试上,Kimi-VL-Thinking取得了36.8%的分数,优于GPT-4o(30.4%)和QVQ-72B-Preview(35.9%)。
-
MathVista:在MathVista基准测试上,Kimi-VL-Thinking取得了71.3%的分数,优于GPT-4o(63.8%)和GPT-4o-mini(56.7%)。
研究局限
尽管Kimi-VL在多个基准测试中表现出色,但它仍面临一些挑战:
-
模型规模限制:当前的模型规模对于许多标准任务是有效的,但对于高度专业化或领域特定的问题,或强烈依赖于语言能力的问题,其处理能力仍然有限,限制了Kimi-VL处理极其复杂场景的能力。
-
推理能力上限:尽管对于典型用例,Kimi-VL的推理能力已经很强,但它尚未达到其理论上限,特别是对于需要多步推理或更深上下文理解的复杂任务。
-
长上下文能力不足:尽管提供了128K的扩展上下文窗口,但由于其注意力层中的参数有限(仅相当于30亿参数模型),其长上下文能力对于某些涉及极长序列或高体积上下文信息的高级应用仍然不足。
未来研究方向
为了克服当前的研究局限,未来的工作将集中在以下几个方面:
-
扩展模型规模:通过增加模型规模,提高Kimi-VL处理高度专业化或领域特定问题的能力,以及处理极其复杂场景的能力。
-
增强预训练数据:扩展预训练数据的多样性和规模,以进一步提高Kimi-VL的多模态理解和推理能力。
-
优化后训练算法:改进SFT和RL算法,以更有效地提升Kimi-VL的长期思考和推理能力。
-
测试时扩展:研究测试时扩展技术,以进一步提高Kimi-VL在处理长上下文和复杂查询时的性能。
-
发布更大版本:优化Kimi-VL,并发布更大规模的版本,以满足不同应用场景的需求。
综上所述,Kimi-VL作为一种高效的多模态视觉语言模型,在多模态推理、长上下文理解和代理能力方面表现出色。然而,它仍面临一些挑战,需要通过未来的研究工作来克服。我们相信,随着技术的不断进步,Kimi-VL将在更多领域展现出其巨大的潜力和应用价值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









