






摘要:我们介绍了FUSION,这是一个多模态大型语言模型(MLLM)家族,具有完全视觉语言对齐和集成范式。 与主要依赖于LLM解码后期模态交互的现有方法不同,我们的方法在整个处理管道中实现了深度、动态的集成。 为此,我们提出了文本引导的统一视觉编码,将文本信息融入到视觉编码中,实现像素级的整合。 我们进一步设计了上下文感知的递归对齐解码,在解码过程中递归地聚合基于文本上下文的视觉特征,从而实现细粒度的、问题级别的语义集成。 为了指导特征映射并减轻模态差异,我们开发了双监督语义映射损失。 此外,我们通过一种新的数据合成方法构建了一个综合语言驱动的问答(QA)数据集,优先考虑高质量的QA对,以优化文本引导的特征集成。 在这些基础上,我们以两种规模(3B、8B)训练FUSION,并证明我们的全模态集成方法在只有630个视觉表征的情况下,其性能明显优于现有方法。 值得注意的是,FUSION 3B在大多数基准测试中超过了Cambrian-1 8B和Florence-VL 8B。 即使限制为300个视觉令牌,FUSION 3B的表现仍然优于Cambrian-1 8B。 我们的消融研究表明,在相同配置下,FUSION在超过一半的基准测试中优于LLaVA-NeXT,没有动态分辨率,突出了我们方法的有效性。 我们发布了代码、模型权重和数据集。https://github.com/starriver030515/FUSION。Huggingface链接:Paper page,论文链接:2504.09925
研究背景和目的
研究背景
随着人工智能技术的飞速发展,多模态大型语言模型(MLLMs)在理解和生成跨模态信息方面展现出巨大的潜力。然而,传统的多模态模型在处理视觉和语言信息时,往往侧重于在模型解码阶段的后期进行模态交互,这种方式限制了模态间信息的深度融合。特别是在视觉语言理解领域,如何实现视觉和语言信息的全面、动态对齐与集成,是当前研究面临的重要挑战。此外,高质量的训练数据对于提升多模态模型的性能至关重要,但现有数据集的构建方法往往侧重于视觉内容的丰富性,而忽视了文本信息的多样性和深度,这限制了模型对复杂、指令遵循任务的理解能力。
研究目的
针对上述问题,本研究旨在提出一种全新的多模态大型语言模型——FUSION,该模型通过完全的视觉语言对齐和集成范式,实现深度跨模态理解。具体研究目的包括:
- 提出文本引导的统一视觉编码:将文本信息融入到视觉编码过程中,实现像素级别的深度整合,从而提高模型对视觉内容的理解能力。
- 设计上下文感知的递归对齐解码:在解码过程中递归地聚合基于文本上下文的视觉特征,实现细粒度的、问题级别的语义集成,提升模型对复杂问题的理解能力。
- 开发双监督语义映射损失:通过双监督的方式指导特征映射,减轻模态间的差异,提高模型在跨模态任务中的表现。
- 构建综合语言驱动的问答数据集:采用新的数据合成方法,优先考虑高质量的QA对,以优化文本引导的特征集成,为模型训练提供丰富、多样的训练数据。
- 验证模型性能:通过在不同规模和基准测试上的实验,验证FUSION模型在跨模态理解任务中的优越性。
研究方法
模型架构
FUSION模型由以下几个关键组件组成:
- 文本引导的统一视觉编码:将文本嵌入映射到视觉特征空间,并与视觉嵌入进行联合处理,通过多层编码层实现文本和视觉信息的相互细化。
- 上下文感知的递归对齐解码:在解码过程中引入交互层,通过局部窗口注意力机制递归地更新潜在令牌,实现视觉和文本信息的细粒度对齐。
- 双监督语义映射损失:通过视觉到文本和文本到视觉的双向转换损失,确保视觉和文本特征空间的一致性,减轻模态间的差异。
数据集构建
为了训练FUSION模型,本研究构建了一个综合语言驱动的问答数据集。该数据集通过以下步骤生成:
- 高质量图像标注池:从多个高质量图像标注数据集中选取图像和对应的标注。
- 文本丰富:利用大型语言模型(LLMs)对标注进行丰富,生成详细、细腻的文本描述。
- 图像生成:将丰富的文本描述作为提示,使用扩散模型生成与文本内容紧密对齐的图像。
- QA对生成:再次利用LLMs对生成的图像和文本描述进行问答对生成,确保问答对的多样性和高质量。
- 数据过滤:通过多阶段过滤过程,确保生成的数据符合高标准和多样性要求。
训练策略
本研究采用了一种三阶段的训练框架,以确保视觉和语言模态之间的全面对齐和集成:
- 基础语义对齐阶段:利用大量图像标注对预训练视觉编码器,建立视觉和文本表示之间的精确语义对齐。
- 上下文多模态融合阶段:在基础语义对齐的基础上,引入各种类型的QA数据,增强模型在不同场景下对齐视觉和语言表示的能力。
- 视觉指令调整阶段:使模型暴露于各种视觉任务中,提高其回答下游视觉相关问题的能力。
研究结果
模型性能
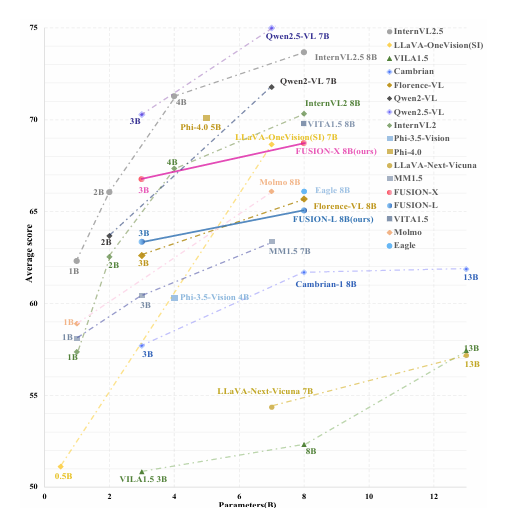
在多个基准测试上,FUSION模型展现出了优越的性能。特别是在MMBench、VisWiz、POPE等一般多模态基准测试上,FUSION 3B模型在大多数指标上超越了Cambrian-1 8B和Florence-VL 8B等先进模型。即使在视觉令牌数量限制为300的情况下,FUSION 3B模型仍然保持了较高的性能,证明了其高效性和鲁棒性。
消融研究
消融研究表明,FUSION模型的各个组件(文本引导的统一视觉编码、上下文感知的递归对齐解码、双监督语义映射损失)均对模型性能有显著提升。特别是双监督语义映射损失和文本引导的统一视觉编码的组合使用,显著提高了模型在一般多模态任务上的表现。此外,潜在令牌数量的增加对OCR和视觉中心任务有显著提升,而合成数据的使用则显著增强了模态对齐和下游任务性能。
研究局限
尽管FUSION模型在多模态理解任务中展现出了优越的性能,但本研究仍存在一些局限性:
- 数据集的局限性:虽然本研究构建了一个综合语言驱动的问答数据集,但数据集的规模和多样性仍有待进一步提高。特别是在一些特定领域和场景下,数据集的覆盖范围和深度可能不足。
- 模型的泛化能力:虽然FUSION模型在多个基准测试上取得了优异的表现,但其泛化能力仍需进一步验证。特别是在面对一些极端或罕见的情况下,模型的表现可能受到影响。
- 计算资源的限制:由于FUSION模型是一个大型的多模态模型,其训练和推理过程需要大量的计算资源。这限制了模型在一些资源受限场景下的应用。
未来研究方向
针对上述研究局限,未来研究可以从以下几个方面展开:
- 扩大数据集规模和多样性:通过不断收集和生成高质量的多模态数据,进一步扩大数据集的规模和多样性,提高模型的泛化能力和鲁棒性。
- 优化模型架构和训练策略:探索更高效的模型架构和训练策略,降低模型的计算和存储需求,提高模型的训练和推理速度。
- 增强模型的解释性和可解释性:通过引入可解释性技术,增强模型对决策过程的解释能力,提高模型在实际应用中的可信度和可接受度。
- 拓展应用场景:将FUSION模型应用于更多的实际场景中,如智能家居、自动驾驶、医疗诊断等,验证其在实际应用中的有效性和可行性。同时,针对不同应用场景的需求,对模型进行定制化和优化。
综上所述,本研究在多模态大型语言模型领域取得了重要的进展,为未来的研究提供了有益的参考和启示。通过不断优化模型架构、训练策略和数据集质量,我们有望进一步提高多模态模型的理解和生成能力,推动人工智能技术的发展和应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









