






摘要:在多模态大型语言模型(MLLMs)中,长上下文视频理解面临着一个关键挑战:即在保持计算效率的同时,保留细粒度的时空模式。现有方法(例如稀疏采样、低分辨率密集采样和令牌压缩)在时间动态、空间细节或微妙交互方面存在显著的信息丢失,尤其是在具有复杂运动或不同分辨率的视频中。为了解决这个问题,我们提出了Mavors,一种新颖的框架,该框架引入了多粒度视频表示,用于全面的长视频建模。具体来说,Mavors通过两个核心组件直接将原始视频内容编码为潜在表示:1)一个块内视觉编码器(IVE),通过3D卷积和视觉转换器保留高分辨率空间特征;2)一个块间特征聚合器(IFA),使用基于转换器的依赖建模和块级旋转位置编码来建立跨块的时间一致性。此外,该框架通过将图像视为单帧视频并通过子图像分解来统一图像和视频理解。在多样基准测试上的实验表明,Mavors在保持空间保真度和时间连续性方面表现出色,在需要细粒度时空推理的任务中显著优于现有方法。Huggingface链接:Paper page,论文链接:2504.10068
研究背景和目的
研究背景
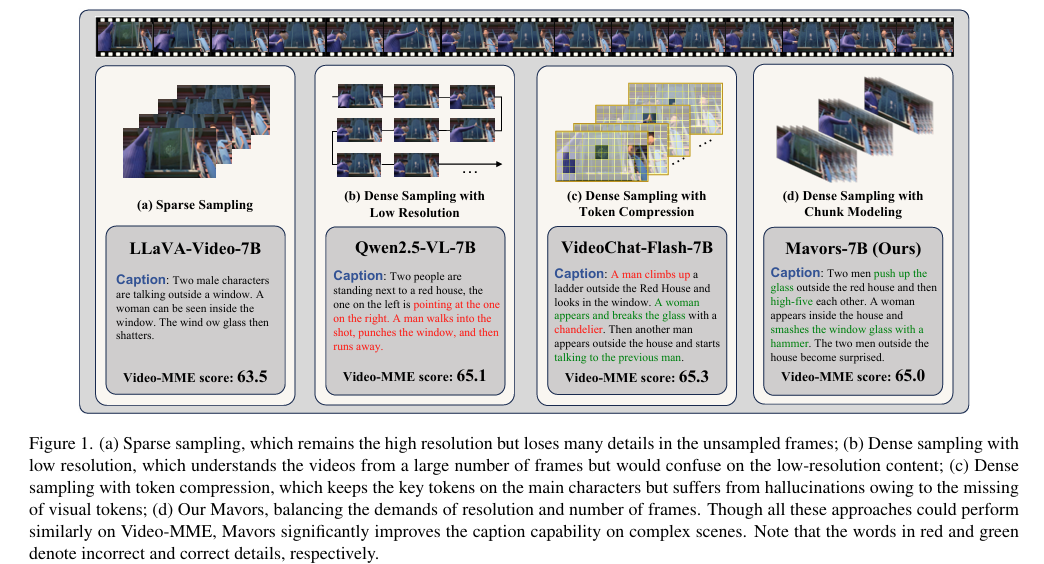
随着人工智能技术的快速发展,多模态大型语言模型(MLLMs)在理解和生成自然语言以及处理多模态信息方面展现出了巨大的潜力。然而,在应对长视频理解等复杂任务时,MLLMs仍面临诸多挑战。长视频通常包含丰富的时空信息,要求模型在处理过程中既要保持计算效率,又要能够准确捕捉视频中的细粒度时空模式。现有的方法,如稀疏采样、低分辨率密集采样和令牌压缩等,虽然在一定程度上缓解了计算压力,但往往会导致时间动态、空间细节或微妙交互信息的丢失,特别是在处理具有复杂运动或不同分辨率的视频时。
此外,现有多模态模型在处理图像和视频时,通常采用独立的方法,缺乏统一的框架来整合这两种模态的信息。这限制了模型在跨模态理解和生成任务中的表现。因此,开发一种能够高效处理长视频,同时保留细粒度时空模式,并实现图像和视频统一理解的多模态模型,成为当前研究的重要方向。
研究目的
针对上述挑战,本文旨在提出一种新颖的多粒度视频表示框架Mavors,用于多模态大型语言模型中的长视频理解。具体研究目的包括:
- 提出多粒度视频表示框架:通过引入块内视觉编码器和块间特征聚合器,实现对长视频的全面建模,同时保留视频中的细粒度时空模式。
- 统一图像和视频理解:通过将图像视为单帧视频,利用子图像分解方法,实现图像和视频理解的统一,提升模型在多模态任务中的表现。
- 提升长视频理解能力:在多样基准测试上验证Mavors框架的有效性,特别是在需要细粒度时空推理的任务中,展现其优越的性能。
研究方法
模型架构
Mavors框架主要由两个核心组件构成:块内视觉编码器(IVE)和块间特征聚合器(IFA)。
-
块内视觉编码器(IVE):IVE负责处理视频中的每个块(chunk),通过3D卷积和视觉转换器(ViT)提取高分辨率的空间特征。这些特征随后被用于生成视频块的潜在表示。
-
块间特征聚合器(IFA):IFA负责建立跨视频块的时间一致性。它使用基于转换器的依赖建模和块级旋转位置编码(C-RoPE),将来自不同视频块的特征进行聚合,从而生成能够反映整个视频内容的潜在表示。
训练范式
为了提升Mavors框架的性能,本文采用了多阶段训练范式,包括模态对齐、时间理解增强、多任务指令微调和直接偏好优化(DPO)训练。
-
模态对齐阶段:在该阶段,主要目标是实现视觉编码器和语言模型之间的语义空间对齐。通过训练块间特征聚合器和多层感知机(MLP)投影器,同时保持语言模型和块内视觉编码器冻结,使模型能够初步理解视频内容。
-
时间理解增强阶段:该阶段专注于提升模型对视频内容的真实理解。通过解冻所有组件(除了语言模型),在模态对齐的基础上进一步训练模型,使其能够处理更复杂的视频任务。
-
多任务指令微调阶段:在此阶段,模型被调整为能够适应多种多模态任务。通过引入包括文本、图像、多图像和复杂视频在内的多样化数据格式,以及接地任务和时间接地任务,增强模型对时空细节的感知能力。
-
直接偏好优化(DPO)训练阶段:为了解决QA任务中模型生成响应过于简洁,以及描述性任务中模型无法适当终止生成的问题,引入了DPO训练阶段。通过比较不同候选响应的偏好得分,优化模型在开放性问题回答、图像描述和视频描述等任务上的表现。
研究结果
实验设置与基准测试
为了全面评估Mavors框架的性能,本文在多个视频和图像基准测试上进行了实验,包括MMWorld、PerceptionTest、Video-MME、MLVU、MVBench、EventHallusion、TempCompass、VinoGround、DREAM-1K等视频理解基准测试,以及MMMU、MathVista、AI2D、CapsBench等图像理解基准测试。
主要实验结果
实验结果表明,Mavors框架在视频理解任务中表现出色,特别是在需要细粒度时空推理的任务中。具体来说:
-
视频理解任务:与基线模型相比,Mavors在多个视频理解基准测试上取得了显著更高的分数。例如,在Video-MME基准测试上,Mavors的得分比Qwen2.5-VL-7B高出近5个百分点,显示出其在处理长视频任务时的优越性能。
-
图像理解任务:尽管Mavors主要针对视频理解设计,但其在图像理解任务上也表现出了强大的性能。在图像描述任务CapsBench上,Mavors的得分甚至超过了某些72B规模的模型,展示了其在跨模态任务中的广泛适用性。
-
消融实验:通过消融实验进一步验证了Mavors框架中各个组件的有效性。例如,移除块间特征聚合器或降低块内视觉编码器的帧数,都会导致模型性能的显著下降,表明这些组件对于保持视频中的时空一致性至关重要。
研究局限
尽管Mavors框架在长视频理解任务中表现出了优越的性能,但仍存在一些局限性:
-
计算效率:尽管Mavors通过多粒度视频表示提高了模型对长视频的处理能力,但其计算效率仍有待进一步提升。特别是在处理非常高分辨率或非常长的视频时,模型的推理速度可能会受到影响。
-
数据依赖性:Mavors的性能在很大程度上依赖于训练数据的质量和多样性。如果训练数据不足以覆盖所有可能的视频场景和模态交互,模型的泛化能力可能会受到限制。
-
模型复杂性:Mavors框架包含多个复杂的组件和训练阶段,这使得模型的实现和调优相对困难。对于资源有限的用户来说,可能难以部署和训练这样的模型。
未来研究方向
针对上述研究局限,未来研究可以从以下几个方面展开:
-
提升计算效率:探索更高效的视频编码和特征提取方法,以减少模型的计算开销。例如,可以利用深度学习加速器或分布式计算技术来加速模型的推理过程。
-
增强数据多样性:继续收集和整理高质量的多模态数据,特别是包含复杂场景和模态交互的视频数据。这可以通过与数据提供者合作、利用众包平台或开发自动数据生成技术来实现。
-
简化模型架构:在保证性能的前提下,尝试简化Mavors框架的架构和训练过程。例如,可以通过模型剪枝、知识蒸馏或参数共享等技术来减少模型的复杂度。
-
跨模态融合研究:进一步探索图像和视频之间的跨模态融合方法,以提高模型在多模态任务中的表现。例如,可以研究如何将图像中的静态信息与视频中的动态信息更有效地结合起来。
-
应用拓展:将Mavors框架应用于更广泛的实际场景中,如视频问答、视频摘要、视频推荐等。通过在实际任务中的验证和反馈,不断改进和优化模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









